
领先一步
VMware 提供培训和认证,助您加速进步。
了解更多本文是探索基于 Java Functions 新设计的 Spring Cloud Stream 应用系列博客的一部分。
以下是本系列博客的所有之前部分。
在本篇博文中,我们将探讨允许我们从 MySQL、PostgreSQL、MongoDB、Oracle、DB2 和 SQL Server 等数据库捕获数据库变更,并通过各种消息绑定器(如 RabbitMQ、Apache Kafka、Azure Event Hubs、Google PubSub 和 Solace PubSub+ 等)实时处理这些变更的Debezium CDC source。
我们还将揭示如何使用Analytics sink将捕获的数据库变更转换为指标,并将其发布到各种监控系统进行进一步分析。
本文首先解释了 CDC supplier 和 Analytics consumer 组件,展示了如何在自己的 Spring 应用中以编程方式定制和使用它们。接下来我们解释了CDC source和Analytics sink是如何基于 supplier 和 consumer 构建,以提供开箱即用、即时可用的流应用。
最后,我们将演示使用Spring Cloud Data Flow (SCDF)部署实时响应数据库更新、将变更事件转换为分析指标并将其发布到 Prometheus 以便使用 Grafana 进行分析和可视化展示的流管道是多么容易。
变更数据捕获(CDC)是一种技术,用于观察写入数据库的所有数据变更,并将其发布为可以流式处理的事件。由于应用数据库总是在变化,CDC 允许您对这些变更做出反应,并使您的应用能够以与提交到数据库相同的顺序流式传输每个行级变更。
CDC 支持多种用例,例如:缓存失效、内存数据视图、更新搜索索引、通过保持不同数据源同步实现数据复制、实时欺诈检测、存储审计跟踪、数据溯源等等。
Spring Cloud Data Flow CDC Source 应用基于Debezium构建,Debezium 是一种流行的开源、基于日志的 CDC 实现,支持各种数据库。CDC Source 支持多种消息绑定器,包括 Apache Kafka、Rabbit MQ、Azure Event Hubs、Google PubSub、Solace PubSub+。
注意
CDC source 实现嵌入了Debezium Engine,它不依赖于 Apache Kafka 和 ZooKeeper!您可以将 CDC source 与任何受支持的消息绑定器一起使用!然而,Debezium Engine 确实存在一些需要考虑的限制。
CDC Debezium Supplier 被实现为一个 java.util.function.Supplier bean,调用时将传递给定目录中的文件内容。该文件 supplier 具有以下签名
Supplier<Flux<Message<?>>>
该 supplier 的用户可以订阅返回的 Flux<Message<?>,它是一个消息流或结构复杂的CDC Change Events流。每个事件由三个部分组成(例如 metadata、before 和 after),如下面的 payload 样本所示
{
"before": { ... }, // row data before the change.
"after": { ... }, // row data after the change.
"source": { // the names of the database and table where the change was made.
"connector": "mysql", "server_id": 223344,"snapshot": "false",
"name": "my-app-connector", "file": "mysql-bin.000003", "pos": 355, "row": 0,
"db": "inventory", // source database name.
"table": "customers", // source table name.
},
"op": "u", // operation that made the change.
"ts_ms": 1607440256301, // timestamp - when the change was made.
"transaction": null // transaction information (optional).
}
如果 cdc.flattening.enabled 属性设置为 true,则只有 after 部分作为独立消息传递。
为了调用 CDC supplier,我们需要指定一个源数据库来接收 CDC 事件。cdc.connector 属性用于选择受支持的源数据库类型,包括 mysql、postgres、sql server、db2、oracle、cassandra 和 mongo。cdc.config.database.* 属性用于配置源访问。以下是连接到 MySQL 数据库的示例配置
# DB type
cdc.connector=mysql
# DB access
cdc.config.database.user=debezium
cdc.config.database.password=dbz
cdc.config.database.hostname=localhost
cdc.config.database.port=3306
# DB source metadata
cdc.name=my-sql-connector
cdc.config.database.server.id=85744
cdc.config.database.server.name=my-app-connector
cdc.name、cdc.config.database.server.id 和 cdc.config.database.server.name 属性用于识别和分派传入事件。您可以选择设置 cdc.flattening.enabled=true 以平展 CDC 事件,用其 after 字段替换原始变更事件,从而创建一个简单的 Kafka 记录。您还可以选择使用 cdc.schema=true 将 DB schema 包含到 CDC 事件中。
注意
源数据库必须配置为暴露其 Write-Ahead Log API,以便 Debezium 能够连接并消费 CDC 事件。Debezium Connector Documentation 详细描述了如何为任何受支持的数据库启用 CDC。出于此处演示的目的,我们将使用预配置的MySQL docker image。
CDC supplier 是一个可重用的 Spring bean,我们可以将其注入到最终用户自定义应用中。注入后,可以直接调用它,并与自定义数据处理相结合。以下是一个示例。
@Autowired
Supplier<Flux<Message<?>>> cdcSupplier;
public void consumeDataAndSendEmail() {
Flux<Message<?> cdcData = cdcSupplier.get();
messageFlux.subscribe(t -> {
if (t == something)
//send the email here.
}
}
}
在上面的伪代码中,我们注入了 CDC supplier bean,然后使用它调用其 get() 方法来获取一个 Flux。然后我们订阅该Flux,每次通过 Flux 接收到数据时,都应用一些过滤,并根据数据执行操作。这只是一个简单的说明,展示了如何重用 CDC supplier。在实际应用中尝试时,您可能需要在实现中进行更多调整,例如在进行条件检查之前将接收到的数据的默认数据类型从 byte[] 转换为其他类型。
提示
为了构建一个独立的、非流式的应用,您可以利用cdc-debezium-boot-starter。只需添加 cdc-debezium-boot-starter 依赖项并实现自定义的 Consumer<SourceRecord> handler 来处理传入的数据库变更事件即可。
正如本系列博客中所见,所有开箱即用的 Spring Cloud Stream 源应用都已自动配置了几个通用的处理器。您可以将这些处理器作为CDC source的一部分激活。以下是一个示例,我们在其中运行 CDC source,接收数据,然后在将消费的数据发送到中间件上的目的地之前对其进行转换。
java -jar cdc-debezium-source.jar
--cdc.connector=mysql --cdc.name=my-sql-connector
--cdc.config.database.server.name=my-app-connector
--cdc.config.database.user=debezium --cdc.config.database.password=dbz
--cdc.config.database.hostname=localhost --cdc.config.database.port=3306
--cdc.schema=true
--cdc.flattening.enabled=true
--spring.cloud.function.definition=cdcSupplier|spelFunction
--spel.function.expression=payload.toUpperCase()
通过为 spring.cloud.function.definition 属性提供值 cdcSupplier|spelFunction,我们激活了与 CDC supplier 组合的 spel 函数。然后我们提供一个 SpEL 表达式,用于使用 spel.function.expression 转换数据。还有其他几种函数可以以这种方式进行组合。有关更多详细信息,请参阅此处。
Analytics consumer 提供了一个函数,用于从输入数据消息中计算分析结果,并将其作为指标发布到各种监控系统。它利用 micrometer library 为大多数流行的监控系统提供统一的编程体验,并使用 Spring Expression Language (SpEL) 来定义如何从输入数据计算指标名称、值和标签。
我们可以在自定义应用中直接使用 consumer bean 来计算传递消息的分析结果。以下是 Analytics consumer bean 的类型签名
Consumer<Message<?>> analyticsConsumer
注入到自定义应用后,用户可以直接调用 consumer 的 accept() 方法,并提供一个 Message<?> 对象,以计算分析结果并将其发布到后端监控系统。
Message 是数据的通用容器。每个 Message 实例包括一个 payload 和 headers,其中包含用户可扩展的属性,格式为键值对。SpEL 表达式用于访问消息的 headers 和 payload,以计算指标的数量和标签。例如,计数器指标可以有一个从输入消息 payload 大小计算出的值 amount,并添加一个从 kind header 值提取的 my_tag 标签
analytics.amount-expression=payload.lenght()
analytics.tag.expression.my_tag=headers['kind']
Analytics consumer 的配置属性以 analytics.* 前缀开头。请参阅AnalyticsConsumerProperties了解可用的 analytics 属性。监控配置属性以 management.metrics.export 前缀开头。要配置特定的监控系统,请遵循提供的配置说明。
与 CDC Source 的情况一样,Spring Cloud Stream 开箱即用的应用已经提供了一个基于 Analytics consumer 的Analytics sink。
该 sink 可用于 Apache Kafka 和 RabbitMQ 绑定器变体。当用作 Spring Cloud Stream sink 时,Analytics consumer 会自动配置为接受来自相应中间件系统的数据,例如,来自 Kafka topic 或 RabbitMQ exchange 的数据。
单独运行 CDC source 和 Analytics sink 没什么问题,但 Spring Cloud Data Flow 使将它们作为管道运行变得非常容易。基本上,我们想要编排看起来像这样的数据流
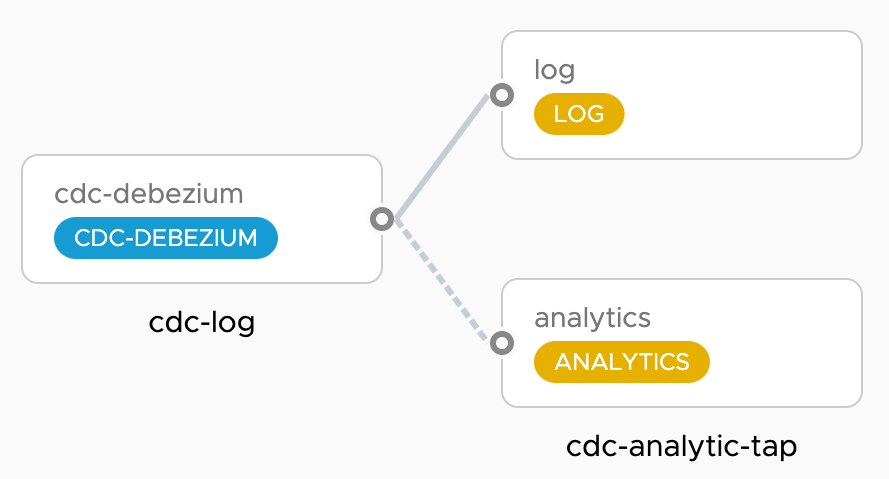
cdc-log 管道部署了一个 cdc-source,它使用 JSON 消息格式将所有数据库变更流式传输到 log-sink。同时,cdc-analytics-tap 管道接入 cdc-source 的输出到 analytics-sink,以便从 CDC 事件计算 DB 统计数据并将其发布到时间序列数据库 (TSDB),例如 Prometheus 或 Wavefront。Grafana 仪表盘用于可视化这些变更。
Spring Cloud Data Flow 的安装说明解释了如何在任何受支持的云平台上安装 Spring Cloud Data Flow。
下面,我们将简要介绍设置 Spring Cloud Data Flow 的步骤。首先,我们需要获取用于运行 Spring Cloud Data Flow、Prometheus 和 Grafana 的 docker-compose 文件
wget -O docker-compose.yml https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.7.0/spring-cloud-dataflow-server/docker-compose.yml
wget -O docker-compose-prometheus.yml https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.7.0/spring-cloud-dataflow-server/docker-compose-prometheus.yml
此外,获取这个额外的 docker-compose 文件,用于安装一个配置为暴露其预写日志(write-ahead log)的源 MySQL 数据库,cdc-debezium 将连接到该数据库。
wget -O mysql-cdc.yml https://gist.githubusercontent.com/tzolov/48dec8c0db44e8086916129201cc2c8c/raw/26e1bf435d58e25ff836e415dae308edeeef2784/mysql-cdc.yml
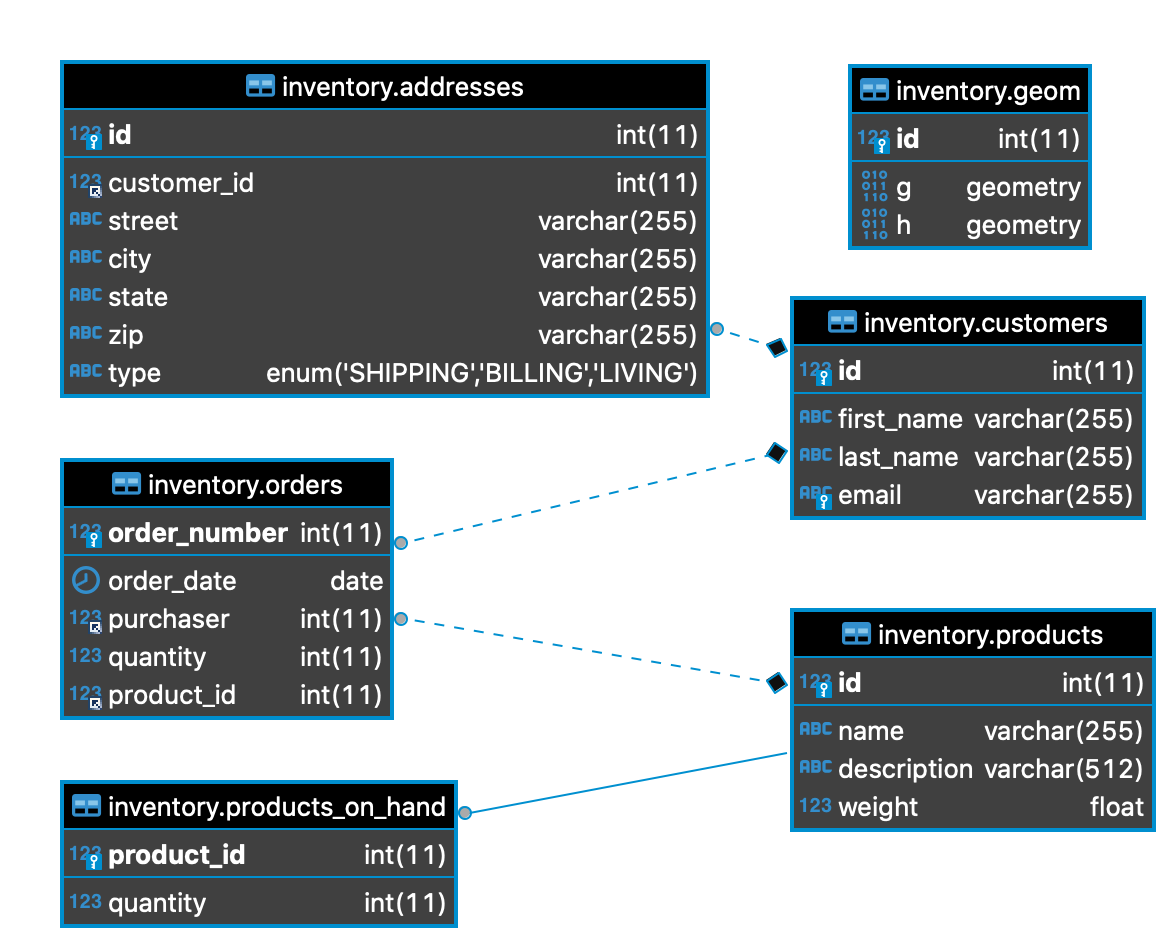
mysql-cdc 使用 debezium/example-mysql 镜像,并附带一个 inventory 示例数据库
为了正确运行 Spring Cloud Data Flow,我们需要设置一些环境变量。
export DATAFLOW_VERSION=2.7.1
export SKIPPER_VERSION=2.6.1
export STREAM_APPS_URI=https://dataflow.springframework.org.cn/kafka-maven-latest
现在一切准备就绪,是时候开始运行 Spring Cloud Data Flow 和所有其他辅助组件了。
docker-compose -f docker-compose.yml -f docker-compose-prometheus.yml -f mysql-cdc.yml up
提示
要使用 RabbitMQ 而不是 Apache Kafka,您可以按照RabbitMQ Instead of Kafka 说明下载额外的 docker-compose 文件,并将 STREAM_APPS_URI 变量设置为 https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/stream-applications-descriptor/2020.0.0-SNAPSHOT/stream-applications-descriptor-2020.0.0-SNAPSHOT.stream-apps-rabbit-maven。
提示
要使用 Wavefront 而不是 Prometheus & Grafana,请遵循Wavefront 说明。
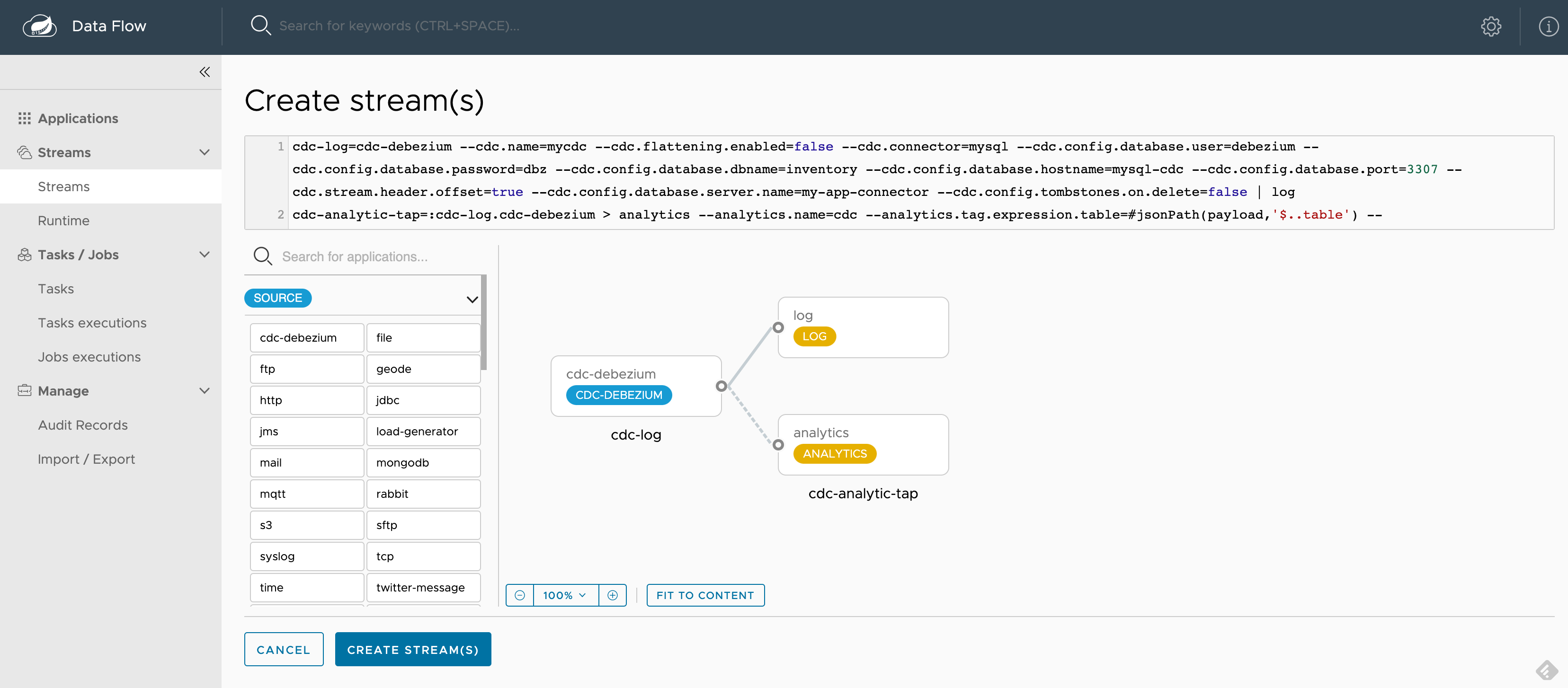
SCDF 启动并运行后,访问 https://:9393/dashboard。然后转到左侧的 Streams 并选择 Create Stream。从 source 应用中选择 cdc-debezium,从 sink 应用中选择 log 和 analytics,以定义 cdc-log = cdc-debezium | log 和 cdc-analytic-tap = :cdc-log.cdc-debezium > analytics 管道。您可以点击应用选项来选择所需的属性。
为了更快地启动,您可以复制/粘贴以下现成的管道定义片段
cdc-log = cdc-debezium --cdc.name=mycdc --cdc.flattening.enabled=false --cdc.connector=mysql --cdc.config.database.user=debezium --cdc.config.database.password=dbz --cdc.config.database.dbname=inventory --cdc.config.database.hostname=mysql-cdc --cdc.config.database.port=3307 --cdc.stream.header.offset=true --cdc.config.database.server.name=my-app-connector --cdc.config.tombstones.on.delete=false | log
cdc-analytic-tap = :cdc-log.cdc-debezium > analytics --analytics.name=cdc --analytics.tag.expression.table=#jsonPath(payload,'$..table') --analytics.tag.expression.operation=#jsonPath(payload,'$..op') --analytics.tag.expression.db=#jsonPath(payload,'$..db')
cdc-log 管道部署了一个 cdc-debezium source,它连接到地址为 mysql-cdc:3307 的 MySQL 数据库,并将 DB 变更事件流式传输到 log sink。有关可用配置选项,请参阅cdc-debezium docs。
cdc-analytic-tap 管道接入 cdc-debezium source 的输出,并将 cdc 事件流式传输到 analytics sink。analytics 创建一个metrics counter(称为 cdc),并使用SpEL expressions 从流式传输的消息 payloads 计算指标标签(例如 db、table 和 operations)。
例如,让我们修改 MySQL inventory 数据库中的 customers 表。更新事务作为变更事件发送到 cdc-debezium source,它将原生 DB 事件转换为统一的消息 payload,如下所示
{
"before": {
"id": 1004, "first_name": "Anne", "last_name": "Kretchmar", "email": "[email protected]"
},
"after": {
"id": 1004, "first_name": "Anne2", "last_name": "Kretchmar", "email": "[email protected]"
},
"source": {
"version": "1.3.1.Final", "connector": "mysql", "server_id": 223344, "thread": 5,
"name": "my-app-connector", "file": "mysql-bin.000003", "pos": 355, "row": 0,
"db": "inventory",
"table": "customers",
},
"op": "u",
"ts_ms": 1607440256301,
"transaction": null
}
以下 SpEL 表达式用于从 CDC 消息 payload 中计算 3 个标签(db、table、operation)。这些标签会分配给发布到 Prometheus 的每个 cdc 指标。
--analytics.tag.expression.db=#jsonPath(payload,'$..db')
--analytics.tag.expression.table=#jsonPath(payload,'$..table')
--analytics.tag.expression.operation=#jsonPath(payload,'$..op')
以下是选择所有属性后的截图示例
创建并部署 cdc-log 和 cdc-analytics-tap 管道,接受所有默认选项。您也可以选择使用 Group Actions 同时部署这两个流。
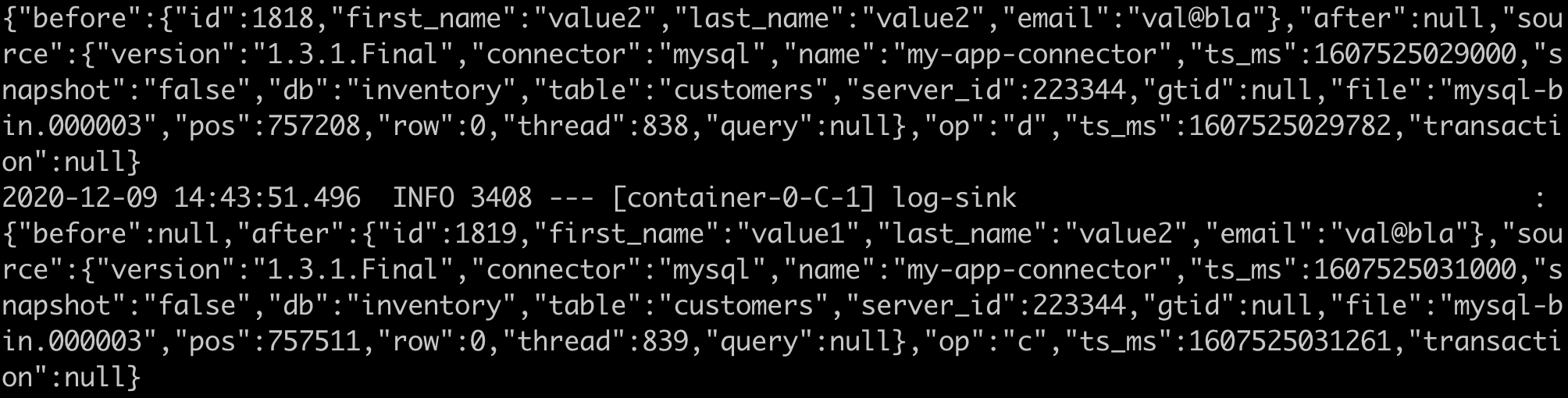
流部署后,您可以通过 SCDF UI 或使用 Skipper docker 容器查看已部署应用的日志,具体方法如文档中解释。如果您查看 Log sink 应用的日志,应该会看到类似于这些的 CDC JSON 消息
接下来使用按钮(或直接打开 localhost:3000)进入 Grafana 仪表盘,并以用户:admin 和密码:admin 登录。您可以探索 Applications 仪表盘来检查已部署管道的性能。现在您可以导入 CDC Grafana Dashboard-Prometheus.json 仪表盘,并看到类似于此的仪表盘
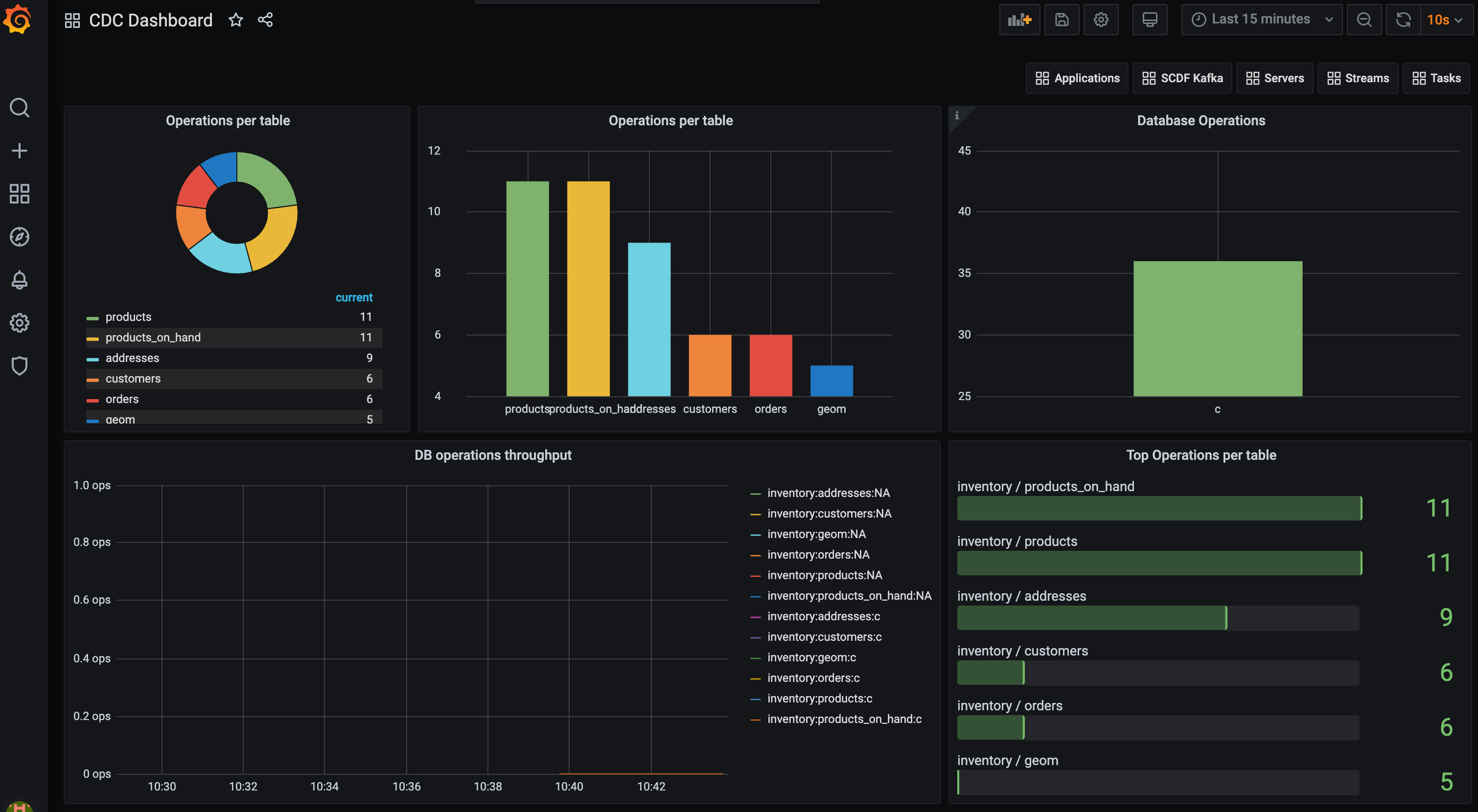
以下查询用于在 Prometheus 中聚合 cdc_total 指标
sort_desc(topk(10, sum(cdc_total) by (db, table)))
sort_desc(topk(100, sum(cdc_total) by (op)))
提示
您可以在 https://:9090 打开 Prometheus UI,检查配置并运行一些临时 PQL 查询。
您可以连接到地址为 localhost:3307 的 inventory CDC MySQL 数据库(用户:root,密码:debezium),并开始修改数据。
以下 docker 命令展示了如何连接到 mysql-cdc
docker exec -it mysql-cdc mysql -uroot -pdebezium --database=inventory
以下脚本有助于生成多个 insert、update 和 delete DB 事务
for i in {1..100}; do docker exec -it mysql-cdc mysql -uroot -pdebezium --database=inventory -e'INSERT INTO customers (first_name, last_name, email) VALUES ("value1", "value2", "val@bla"); UPDATE customers SET first_name="value2" WHERE first_name="value1"; DELETE FROM customers where first_name="value2";'; done
您将看到 log-sink 的日志反映这些变更,以及 CDC 仪表盘图表的更新。
在本篇博客中,我们了解了 CDC-debezium supplier 和 Analytics consumer 函数及其对应的 Spring Cloud Stream source 和 sink 是如何工作的。supplier 和 consumer 函数可以注入到自定义应用中,与其他业务逻辑相结合。
source 和 sink 应用是开箱即用的,可用于 Kafka 和 RabbitMQ 中间件变体。
您可以轻松构建将 Cdc-debezium supplier 与 Geode consumer 相结合的独立应用,以创建和维护数据库数据的内存视图。类似地,您可以将 Cdc-debezium supplier 与 Elasticsearch consumer 相结合,以实时维护数据库数据的可搜索索引。
更令人兴奋的是,您可以使用开箱即用的 cdc-debezium source、geode sink 和 elasticsearch sink 应用实现上述场景。您可以在不同的消息绑定器和源数据库上构建这些管道。
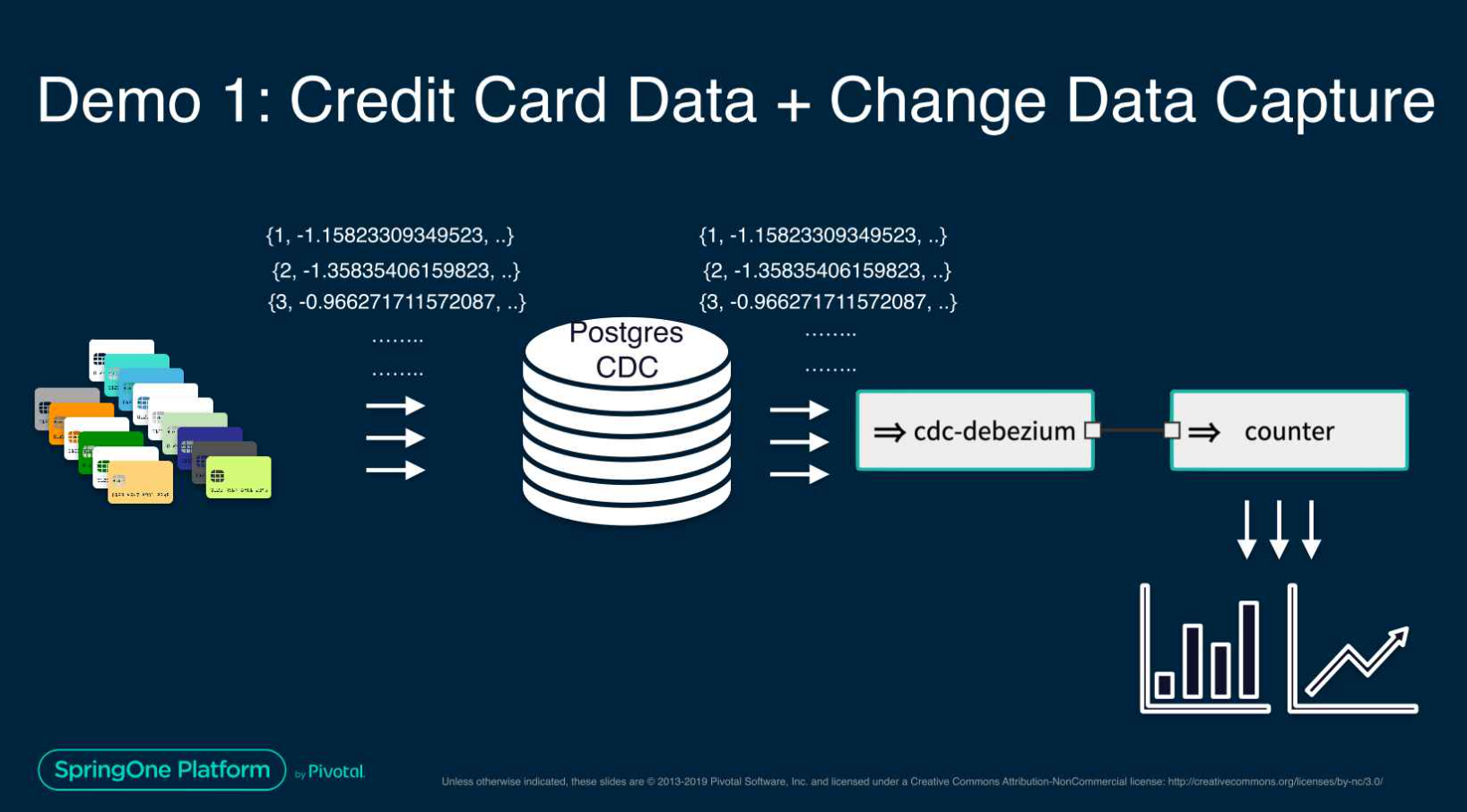
这个Spring One 演示文稿展示了一个高级用例,使用 CDC-debezium 和机器学习构建用于信用卡欺诈检测的流式数据管道。
本系列博客还有几篇后续文章即将发布。敬请期待。