
抢占先机
VMware 提供培训和认证,助您加速进步。
了解更多本文是一个系列博客的一部分,探讨了基于 Java Function 的全新设计的 Spring Cloud Stream applications。在本篇中,我们将深入研究文件供应者 (file supplier) 及其对应的 Spring Cloud Stream 文件源 (file source)。我们还将介绍 MongoDB 消费者 (MongoDB consumer) 及其对应的 Spring Cloud Stream 接收器 (sink)。最后,我们将演示如何在 Spring Cloud Data Flow 上将文件源和 MongoDB 接收器协同编排成一个管道 (pipeline)。
以下是本系列博客的所有先前部分。
文件摄取和从这些文件读取数据是一个经典的企业用例。几十年来,许多企业一直依赖不同程度的文件设施来执行关键任务系统。数 TB 的数据作为文件在互联网和企业内网中传输。例如,想象一下银行数据中心,它每秒从所有分支机构、ATM 和 POS 交易接收数据文件,然后需要处理这些文件并将其放入其他系统中。这只是一个领域,但有成千上万的例子表明文件处理是许多业务的关键路径。存在许多遗留系统,其中编写了许多自定义应用程序,每个应用程序都采用自己的方式来处理这些用例。Spring Integration 多年来一直作为通道适配器提供文件支持。这些组件可以实现为 Function,而在从文件读取的情况下,我们可以提供一个可重用并注入到最终用户应用程序中的通用 Supplier Function。在以下部分中,我们将看到有关此功能抽象及其各种使用场景的更多详细信息。
文件 Supplier 是一个组件,实现为 java.util.function.Supplier Bean,当被调用时,它将提供给定目录中的文件内容。文件 supplier 具有以下签名。
Supplier<Flux<Message<?>>>
supplier 的用户可以订阅返回的 Flux<Message<?>,这是一个消息流或目录中文件本身的流。
为了调用文件 supplier,我们需要指定一个目录来轮询文件。目录信息是必需的,必须通过配置属性 file.supplier.directory 提供。默认情况下,supplier 将生成 byte[] 类型的数据,但它也通过配置属性 file.consumer.mode 支持另外两种文件消费模式。支持的附加值是 lines 和 ref。lines 文件消费模式将逐行消费文件内容。这对于读取文本文件(例如 CSV 文件和其他结构化文本数据)非常有用。ref 模式将提供实际的 File 对象。默认情况下,文件 supplier 还会阻止重复读取已读过的文件。这由属性 file.supplier.preventDuplicates 控制。
文件 supplier 是一个可重用的 Spring Bean,可以注入到最终用户的自定义应用程序中。注入后,可以直接调用它并结合自定义数据处理。这是一个示例。
@Autowired
Supplier<Flux<Message<?>>> fileSupplier;
public void consumeDataAndSendEmail() {
Flux<Message<?> data = fileSupplier.get();
messageFlux.subscribe(t -> {
if (t == something)
//send the email here.
}
}
}
在上面的伪代码中,我们注入了文件 supplier Bean,然后使用它调用其 get 方法来获取一个 Flux。然后我们订阅该 Flux,并通过 Flux 接收到数据时,应用一些过滤并根据过滤结果执行操作。这只是一个简单的示例,展示了如何重用文件 supplier。当您在实际应用程序中尝试时,您可能需要在实现中进行更多调整,例如在执行条件检查之前将接收到的数据的默认数据类型从 byte[] 转换为其他类型,或者将默认的文件读取模式从 content 更改为 lines 等。
当文件 supplier 与 Spring Cloud Stream 结合使用时,它会变得更强大,成为一个文件源。正如我们在之前的博客中看到的,这个 supplier 已经预先打包了 Spring Cloud Stream 中的 Kafka 和 RabbitMQ 绑定器,使它们成为可以作为 Spring Boot 应用程序运行的 uber jar。让我们看看如何获取这个 uber jar 并将其作为独立应用程序运行。
第一步,获取带有 Apache Kafka 变体的文件源。
wget https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/file-source-kafka/3.0.0-SNAPSHOT/file-source-kafka-3.0.0-SNAPSHOT.jar
确保您的 Kafka 正在默认端口上运行。
现在是时候独立运行文件源了。
java -jar file-source-kafka-3.0.0-SNAPSHOT.jar --file.supplier.directory=/tmp/data-files --file.consumer.mode=lines --spring.cloud.stream.bindings.output.destination=file-data
默认情况下,Spring Cloud Stream 期望输出绑定是 fileSupplier-out-0(因为 fileSupplier 是 supplier Bean 的名称)。然而,当这些应用程序生成时,这个输出绑定会被覆盖为 output。这样做是为了适应在 Spring Cloud Data Flow 上运行此源应用程序时的一些要求。
我们还要求应用程序读取落在 /tmp/data-files 目录中的文件,并将其逐行消费(使用 lines 模式)。
观察 Kafka 主题 file-data。使用 kafkacat 工具,您可以执行此操作:
kafkacat -b localhost:9092 -t file-data
现在,在 /tmp/data-files 目录中放置一些文件。您将看到数据到达 file-data Kafka 主题,文件中每一行代表一个 Kafka 记录。
如果您想将文件限制为特定模式,可以使用属性 file.supplier.filenamePattern 的简单命名模式,或者使用属性 file.supplier.filenameRegex 的更复杂的基于正则表达式的模式。
正如我们在本系列博客的第二部分中所看到的,所有开箱即用的 Spring Cloud Stream 源应用程序都已自动配置了几个开箱即用的通用处理器。您可以将这些处理器作为文件源的一部分激活。这里有一个示例,我们运行文件源并接收数据,然后将消费的数据进行转换,再发送到中间件上的目的地。
java -jar file-source-kafka-3.0.0-SNAPSHOT.jar --file.supplier.directory=/tmp/data-files --file.consumer.mode=lines --spring.cloud.stream.bindings.output.destination=file-data --spring.cloud.function.definition=fileSupplier|spelFunction --spel.function.expression=payload.toUpperCase()
通过为 spring.cloud.function.definition 属性提供值 fileSupplier|spelFunction,我们激活了与文件 supplier 组合的 SpEL Function。然后,我们提供一个 SpEL 表达式,用于使用 spel.function.expression 转换数据。
还有其他几种 Function 可以通过这种方式组合。请在此处查看更多详细信息。
MongoDB consumer 提供了一个 Function,允许从外部系统接收数据,然后将这些数据写入 MongoDB。我们可以直接在自定义应用程序中使用 consumer Bean 将数据插入到 MongoDB 集合中。以下是 MongoDB consumer Bean 的类型签名。
Consumer<Message<?>> mongodbConsumer
一旦注入到自定义应用程序中,用户可以直接调用 consumer 的 accept 方法,并提供一个 Message<?> 对象,将其有效载荷发送到 MongoDB 集合。
使用 MongoDB consumer 时,collection 是一个必需属性,必须通过 mongodb.consumer.collection 进行配置。
与文件源的情况一样,开箱即用的 Spring Cloud Stream 应用程序已经提供了使用 MongoDB consumer 的 MongoDB sink。该 sink 支持 Kafka 和 RabbitMQ 绑定器变体。当用作 Spring Cloud Stream sink 时,MongoDB consumer 会自动配置为接受来自相应中间件系统的数据,例如,来自 Kafka 主题或 RabbitMQ 交换器的数据。
让我们花几分钟验证我们可以独立运行 MongoDB sink。
在终端窗口中执行以下命令。
docker run -d --name my-mongo \
-e MONGO_INITDB_ROOT_USERNAME=mongoadmin \
-e MONGO_INITDB_ROOT_PASSWORD=secret \
-p 27017:27017 \
mongo
docker exec -it my-mongo /bin/sh
这将使我们进入运行中的 Docker 容器的 shell 会话。在 shell 中调用以下命令。
# mongo
> use admin
> db.auth('mongoadmin','secret')
1
> db.createCollection('test_collection’')
{ "ok" : 1 }>
现在我们已经设置好 MongoDB,让我们独立运行 sink。
wget https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/mongodb-sink-kafka/3.0.0-SNAPSHOT/mongodb-sink-kafka-3.0.0-SNAPSHOT.jar
java -jar mongodb-sink-kafka-3.0.0-SNAPSHOT.jar --mongodb.consumer.collection=test_collection --spring.data.mongodb.username=mongoadmin --spring.data.mongodb.password=secret --spring.data.mongodb.database=admin --spring.cloud.stream.bindings.input.destination=test-data-mongo
将一些 JSON 数据插入到 Kafka 主题 test-data-mongo 中。例如,您可以使用 Kafka 附带的控制台生产者脚本,如下所示。
/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test-data-mongo
然后像这样生成数据:
{"hello":"mongo"}
转到我们在上面 Docker shell 中启动的终端上的 MongoDB CLI。
db.test_collection.find()
通过 Kafka 主题输入的数据应显示为输出。
独立运行文件源和 MongoDB 都很顺利,但 Spring Cloud Data Flow 使得将它们作为管道运行变得非常容易。基本上,我们想要编排一个等同于 File Source | Filter | MongoDB 的流程。
本系列博客中的一篇专门详细介绍了如何运行 Spring Cloud Data Flow 并将应用程序部署为流。如果您不熟悉运行 Spring Cloud Data Flow,请回顾该博客。下面,我们将简要介绍设置 Spring Cloud Data Flow 的步骤。
首先,我们需要获取用于运行 Spring Cloud Data Flow 的 docker-compose 文件。
wget -O docker-compose.yml https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.6.0/spring-cloud-dataflow-server/docker-compose.yml
另外,获取这个用于运行 MongoDB 的附加 docker-compose 文件。
wget -O mongodb.yml https://raw.githubusercontent.com/spring-cloud/stream-applications/gh-pages/files/mongodb.yml
我们需要设置一些环境变量才能正确运行 Spring Cloud Data Flow。
export DATAFLOW_VERSION=2.6.0
export SKIPPER_VERSION=2.5.0
export STREAM_APPS_URI=https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/stream-applications-descriptor/2020.0.0-SNAPSHOT/stream-applications-descriptor-2020.0.0-SNAPSHOT.stream-apps-kafka-maven
现在一切准备就绪,是时候开始运行 Spring Cloud Data Flow 和所有其他辅助组件了。
docker-compose -f docker-compose.yml -f mongo.yml up
一旦 SCDF 启动并运行,请访问 https://:9393/dashboard。然后转到左侧的 Streams 并选择 Create Stream。从源应用程序中选择 File,从处理器中选择 Filter,从 sink 应用程序中选择 MongoDB。点击选项并选择以下属性。以下是选择所有属性后的截图。
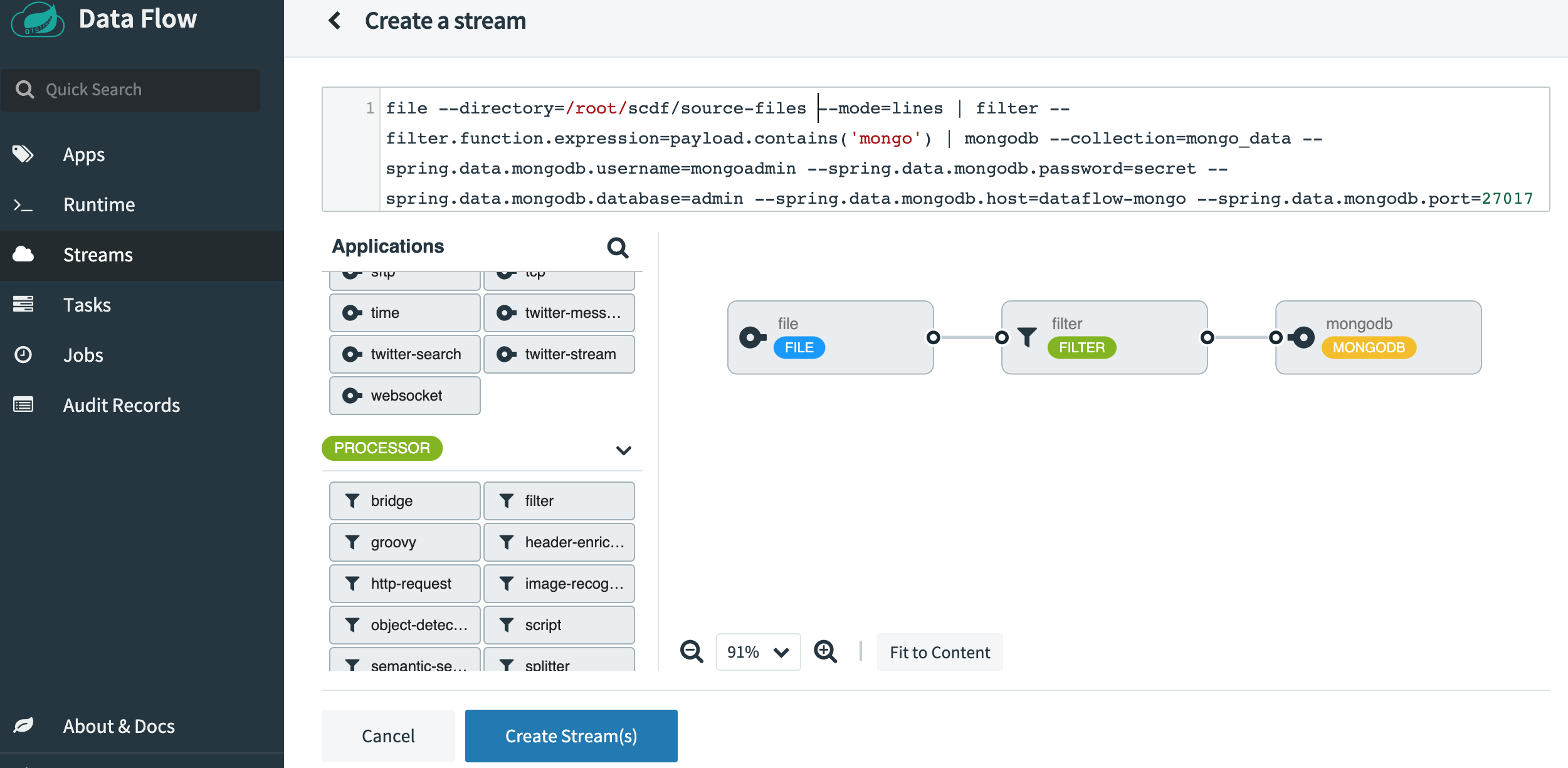
将流命名为 file-source-filter-mongo,然后点击 Create the Stream。创建后,点击“Deploy the Stream”。接受所有默认选项,然后点击屏幕底部的“Deploy Stream”。
流部署完成后,请在调用 Spring Cloud Data Flow docker-compose 脚本的同一目录下创建一个名为 source-files 的目录。该目录已经由运行 Spring Cloud Data Flow 组件(Skipper)之一的 Docker 容器挂载,并可由容器看到。确保此 source-files 目录具有正确的访问级别,特别是由于 Docker 容器将以 root 身份运行应用程序,而您很可能在本地机器上以非 root 用户身份运行。在 UI 上查看文件源应用程序的日志以检查是否有权限错误。如果看到任何错误,请解决这些问题。
准备一个新的终端会话,并使用 mongo CLI 工具。
docker exec -it dataflow-mongo /bin/sh
# mongo
> use admin
> db.auth(‘mongoadmin’,'secret')
1
> db.createCollection(‘mongo_data’')
{ "ok" : 1 }>
在 source-files 目录中放置一些文件,内容如下。
{"non-sql":"mongo"}
{"sql":"mysql"}
{"document":"mongo"}
{"log":"kafka"}
{"sink":"mongo"}
转到 mongo CLI 终端会话。
db.mongo_data.find()
您将看到我们在管道中添加的过滤组件过滤掉了文件中所有不包含单词 mongo 的条目。您应该看到类似于以下的输出。
{ "_id" : ObjectId("5f4551c470e0373080fcd0b8"), "non-sql" : "mongo" }
{ "_id" : ObjectId("5f4551c470e0373080fcd0b2"), "sink" : "mongo" }
{ "_id" : ObjectId("5f4551c470e0373080fcd0b5"), "document" : "mongo" }
在本篇博客中,我们快速回顾了文件 Supplier 及其对应的 Spring Cloud Stream 源。我们还了解了 MongoDB consumer 和相应的 Spring Cloud Stream sink 应用程序。我们探讨了如何将 Function 组件注入到自定义应用程序中。之后,我们看到了如何独立运行文件源和 MongoDB sink 的 Spring Cloud Stream 应用程序。最后,我们深入研究了 Spring Cloud Data Flow,并编排了一个从文件源到 MongoDB sink 的管道,并在途中过滤掉了一些数据。
本系列博客将继续更新。在接下来的几周里,我们将探讨更多类似于本博客中描述的场景,但会涉及不同的 Function 和应用程序。