
{kind=link}
领先一步
VMware 提供培训和认证,助您加速进步。
了解更多到目前为止,在本系列中,我们已经介绍了基于 Java 函数的新流应用程序以及函数组合。我们还提供了如何从供应商构建源以及从消费者构建接收器的详细示例。在这里,我们继续接下来的几个案例研究中的第一个。每个案例研究都演示了如何在各种场景中使用一个或多个可用的预打包 Spring Boot 流应用程序来构建数据流管道。
今天我们将展示两个最常用的应用程序:HTTP 源和JDBC 接收器。我们将使用它们构建一个简单的服务,该服务接受 HTTP POST 请求并将内容保存到数据库表中。我们将首先将它们作为独立的Spring Cloud Stream应用程序运行,然后展示如何使用Spring Cloud Data Flow编排相同的管道。本文以分步教程的形式呈现,我们鼓励您在阅读时遵循这些步骤。
这个简单的流应用程序由两个通过消息代理进行通信的远程进程组成。预打包的流应用程序可以开箱即用地与 Apache Kafka 或 RabbitMQ 配合使用。这里我们将使用 Apache Kafka。JDBC 接收器将数据插入数据库。在本例中,我们将使用 MySQL。
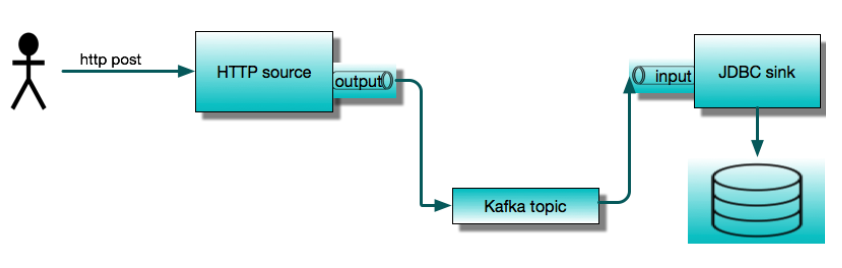
假设我们从头开始,开发环境中没有 Kafka 或 MySQL。为了运行这个示例,我们将使用 Docker。因此,我们需要在本地机器上运行 Docker。稍后我们将使用 Spring Cloud Data Flow,所以我们将利用 Data Flow 的 docker-compose 安装。这是开始使用 Data Flow 的最简单方法。它会启动多个容器,包括 MySQL 和 Kafka。为了使这些后端服务可用于独立应用程序,我们需要调整标准安装以发布端口,并更改 Kafka 的广告主机名。
注意
我已经在 Mac OS 上使用此设置运行,并期望类似的设置也能在 Windows 上运行。如果您遇到问题或有任何有用的提示,请在评论区留言。
首先,让我们创建一个名为 http-jdbc-demo 的目录,并将 docker-compose.yml 从 github 下载到该目录。
wget -O docker-compose.yml https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.6.0/spring-cloud-dataflow-server/docker-compose.yml
或
curl https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.6.0/spring-cloud-dataflow-server/docker-compose.yml -o docker-compose.yml
为了能够从本地主机连接到 Kafka 和 MySQL,我们将下载另一个 YAML 文件来覆盖我们的自定义配置。
wget -O shared-kafka-mysql.yml https://raw.githubusercontent.com/spring-cloud/stream-applications/gh-pages/files/shared-kafka-mysql.yml
接下来,我们需要获取本地机器的局域网 IP 地址。在 Mac 上,您可以通过以下几种方式之一完成此操作,例如
dig +short $(hostname)
或
ping $(hostname)
局域网 IP 地址对 docker 容器也是可访问的,而容器内部的 localhost 或 127.0.0.1 指的是自身。我们需要将环境变量 KAFKA_ADVERTISED_HOST_NAME 设置为这个值。我们还需要设置其他几个环境变量
export KAFKA_ADVERTISED_HOST_NAME=$(dig +short $(hostname))
export DATAFLOW_VERSION=2.6.0
export SKIPPER_VERSION=2.5.0
并注册 Data Flow 中的最新流应用程序
export STREAM_APPS_URI=https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/stream-applications-descriptor/2020.0.0-SNAPSHOT/stream-applications-descriptor-2020.0.0-SNAPSHOT.stream-apps-kafka-maven
现在,从我们的项目目录中,我们可以启动 Data Flow 集群。
docker-compose -f docker-compose.yml -f shared-kafka-mysql.yml up
这将显示大量日志消息并持续运行,直到您终止它(例如,Ctrl-C),这将停止所有容器。保持此终端打开。
打开一个新的终端并输入
docker ps
这将列出 Data Flow 集群中正在运行的容器。我们稍后会查看 Data Flow。此时,请确保 dataflow-kafka 容器在 PORTS 下显示 0.0.0.0:9092→9092/tcp,并且 dataflow-mysql 类似地显示 0.0.0.0:3306→3306/tcp。
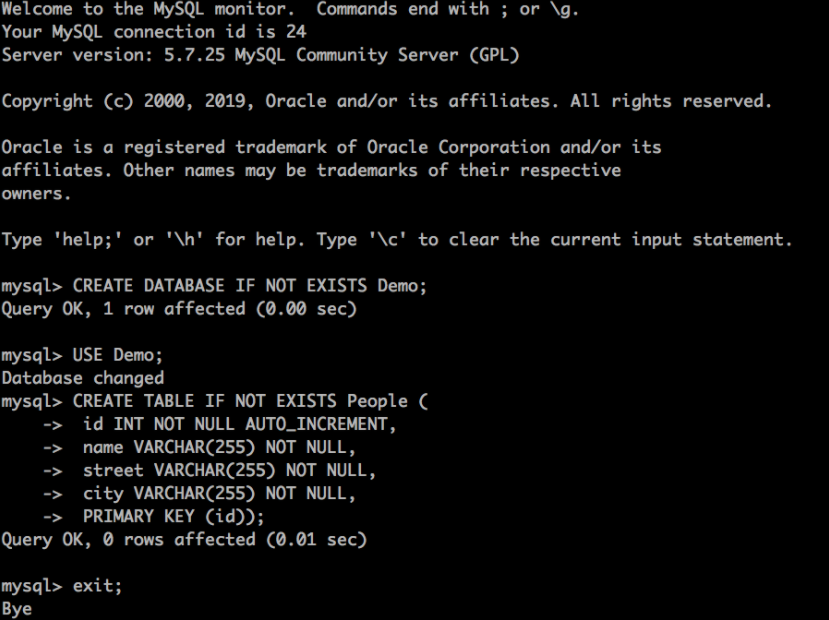
我们可以将 JDBC sink 应用程序配置为自动初始化数据库,但为了简单起见,我们将手动创建它。我们可以使用任何 JDBC 数据库工具或通过在 dataflow-mysql 容器内运行 mysql 来完成此操作。
docker exec -it dataflow-mysql mysql -uroot -p
系统将提示您输入密码。数据库凭据已在 docker-compose.yml 中配置。如果您不想在那里查找,用户名是 root,密码是 rootpw。
输入以下命令——您应该能够复制并粘贴整个内容——以创建数据库和表。
CREATE DATABASE IF NOT EXISTS Demo;
USE Demo;
CREATE TABLE IF NOT EXISTS People (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
street VARCHAR(255) NOT NULL,
city VARCHAR(255) NOT NULL,
PRIMARY KEY (id));
输入 exit; 退出。
此时,我们准备运行 HTTP 源和 JDBC 接收器。Spring Boot 可执行 JAR 已发布到 Spring Maven 仓库。我们需要使用 Kafka 绑定器构建的 JAR。
wget https://repo.spring.io/snapshot/org/springframework/cloud/stream/app/http-source-kafka/3.0.0-SNAPSHOT/http-source-kafka-3.0.0-SNAPSHOT.jar
wget https://repo.spring.io/snapshot/org/springframework/cloud/stream/app/jdbc-sink-kafka/3.0.0-SNAPSHOT/jdbc-sink-kafka-3.0.0-SNAPSHOT.jar
我们将在单独的终端会话中运行这些。我们需要配置这些应用程序以使用相同的 Kafka 主题,我们称之为 jdbc-demo-topic。Spring Cloud Stream Kafka 绑定器将自动创建此主题。我们还需要配置 JDBC 接收器以连接到我们的数据库并将数据映射到我们创建的表。我们将发布如下所示的 JSON
{
“name”:”My Name”,
“address”: {
“street”:”My Street”,
“city”: “My City”
}
}
我们要将这些值插入到 Demo 数据库的 People 表中,插入到 name、street 和 city 列中。
打开我们下载 jar 的新终端会话并运行
java -jar jdbc-sink-kafka-3.0.0-SNAPSHOT.jar --spring.datasource.url=jdbc:mariadb://:3306/Demo --spring.datasource.username=root --spring.datasource.password=rootpw --jdbc.consumer.table-name=People --jdbc.consumer.columns=name,city:address.city,street:address.street --spring.cloud.stream.bindings.input.destination=jdbc-demo-topic
请注意用于将字段映射到列的 jdbc.consumer.columns 语法。
打开我们下载 jar 的新终端会话并运行
java -jar http-source-kafka-3.0.0-SNAPSHOT.jar --server.port=9000 --spring.cloud.stream.bindings.output.destination=jdbc-demo-topic
这里我们将源的 HTTP 端口设置为 9000(默认为 8080)。此外,源的输出目的地与接收器的输入目的地匹配非常重要。
接下来,我们需要向 https://:9000 发布一些数据。
curl https://:9000 -H'Content-Type:application/json' -d '{"name":"My Name","address":{"street":"My Street","city":"My City"}}}
再次,找到一个开放的终端会话并
docker exec -it dataflow-mysql mysql -uroot -p
使用 rootpw 登录并查询表
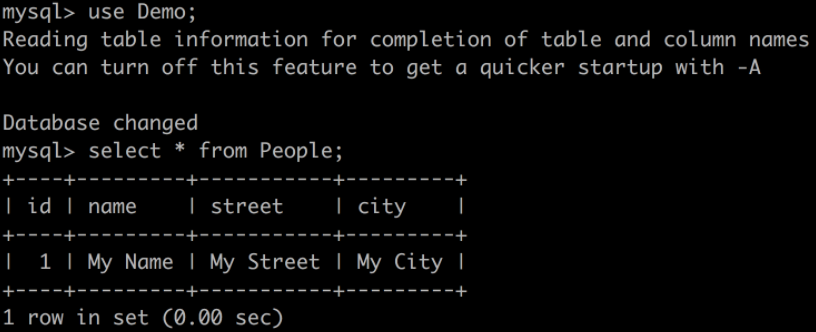
如果你看到这个,恭喜你!独立的 Spring Cloud Stream 应用程序按预期工作。我们现在可以终止我们的独立应用程序 (Ctrl-C)。让 docker-compose 进程保持运行,以便我们可以查看 Data Flow。
正如我们所看到的,即使我们不需要编写任何代码,在“裸机”上运行这些应用程序也需要很多手动步骤。这些步骤包括
自定义 docker-compose 配置,或者在本地机器上安装 kafka 和 mysql
使用 Maven URL 下载所需版本的流应用程序(我们碰巧知道这里要使用哪些)
确保 Spring Cloud Stream 目标绑定已正确配置,以便应用程序可以通信
查找并阅读 文档 以获取配置属性(我们已经完成了这些以准备此示例)并正确设置它们。
管理多个终端会话
在接下来的部分中,我们将看到使用 Spring Cloud Data Flow 可以消除所有这些步骤,并提供更丰富的整体开发体验。
要开始,请打开 Data Flow Dashboard,地址为 https://:9393/dashboard。这将带您进入应用程序视图,您可以在其中看到已注册的预打包应用程序。我们之前运行的 docker-compose 命令执行了此步骤,它使用我们提供的 URL 获取流应用程序的最新快照版本,包括我们刚刚运行的相同 jar 文件。
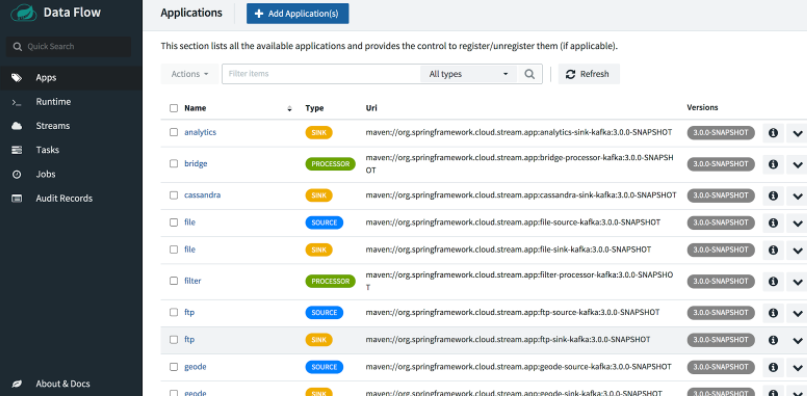
在控制面板中,从左侧菜单中选择 Streams,然后单击 Create Streams 以打开图形化流编辑器。
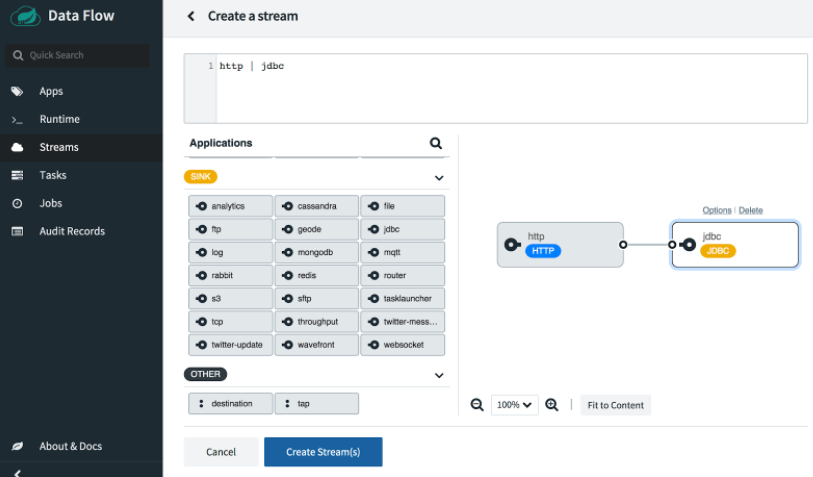
将 http 源和 jdbc 接收器拖放到编辑器窗格中,然后使用鼠标连接两个句柄。或者,您可以直接在顶部的文本框中键入 Data Flow 流定义 DSL:http | jdbc。
接下来我们需要配置应用程序。如果您点击任何一个应用程序,您将看到一个 Options 链接。打开 JDBC sink 的选项窗口。您将看到所有可用的配置属性以及简短描述。以下屏幕截图显示了部分视图;我们需要滚动才能看到其余部分。
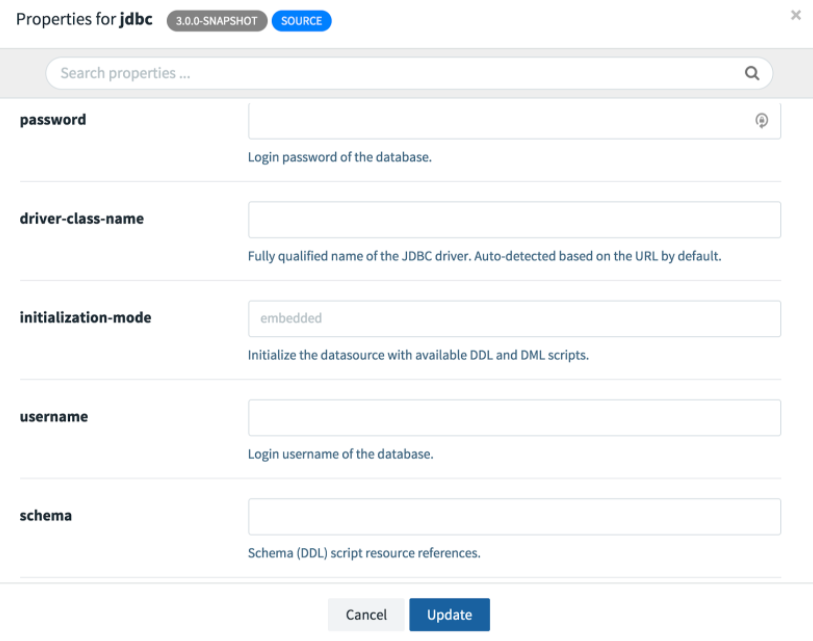
与之前一样,我们需要提供 URL、用户名、密码、表和列。在这里,我们需要将 JDBC URL 更改为 jdbc:mariadb://mysql:3306/Demo,因为主机名 mysql 对应于 docker-compose.yml 中定义的 mysql 服务名称。此外,我们将 http 端口设置为 20000,因为它在已配置的已发布端口范围内。有关更多详细信息,请参阅 skipper-server 配置。
让我们看看自动生成的流定义 DSL
http --port=20000 | jdbc --password=rootpw --username=root --url=jdbc:mariadb://mysql:3306/Demo --columns=name,city:address.city,street:address.street --table-name=People
此 DSL 可用于脚本或 Data Flow 客户端应用程序以自动化流创建。我们的配置已完成,但 Spring Cloud Stream 目标绑定在哪里?我们不需要它们,因为 Data Flow 为我们处理了连接。
选择 Create Stream 按钮并将流命名为 http-jdbc。
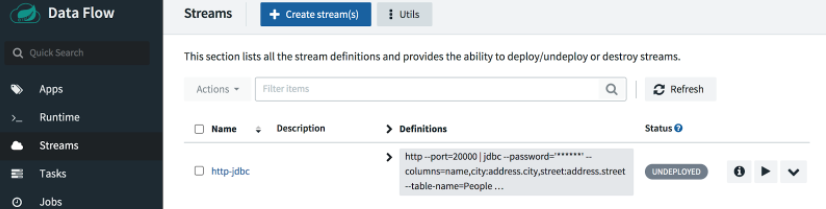
要部署流,请单击播放按钮

接受默认部署属性,然后单击页面底部的 Deploy stream。
根据需要点击 Refresh 按钮。大约一分钟后,您应该会看到我们的流已部署。
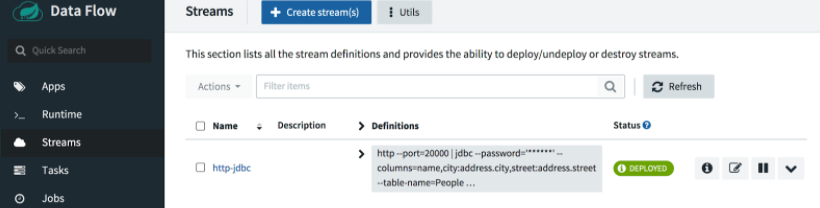
这里我们将向端口 20000 发布一些不同的值
curl https://:20000 -H'Content-Type:application/json' -d '{"name":"Your Name","address":{"street":"Your Street","city":"Your City"}}}'
当我们再次运行查询时,我们应该会看到表中添加了一行新数据。
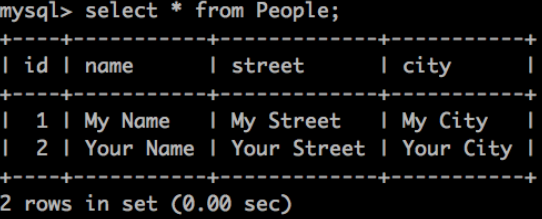
干得好!
敏锐的读者会注意到,即使平台本身在容器中运行,也没有为部署的应用程序创建 Docker 容器。在 Data Flow 架构中,Skipper 服务器负责部署流应用程序。在本地配置中,Skipper 使用本地部署器在其 localhost 上运行 jar 文件,就像我们运行独立应用程序时一样。为了证明这一点,我们可以在 Skipper 容器中运行 ps
docker exec -it skipper ps -ef

要查看控制台日志,请使用 stdout 路径
docker exec -it skipper more /tmp/1596916545104/http-jdbc.jdbc-v4/stdout_0.log
tail -f 命令也适用。
如果部署成功,应用程序日志也可以从 UI 中查看。
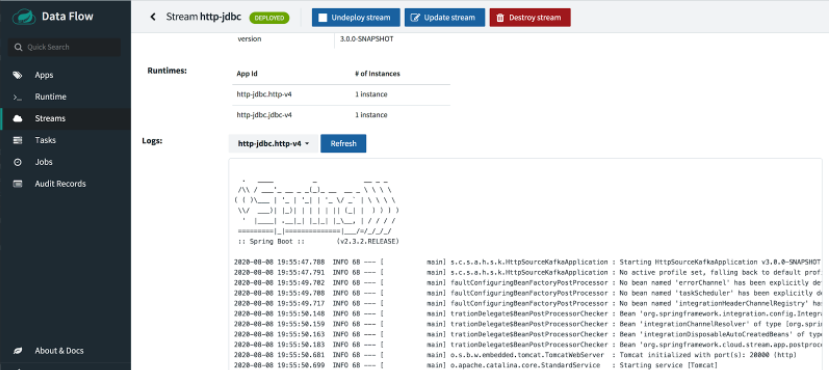
但如果部署失败,我们可能需要深入研究以解决问题。
注意
本地 Data Flow 安装适用于本地开发和探索,但我们不建议将其用于生产环境。生产级别的 Spring Cloud Data Flow OSS 以及商业许可产品可用于 Kubernetes 和 Cloud Foundry。
我们刚刚仔细研究了如何使用预打包的 Spring Cloud Stream 应用程序构建一个简单的数据流管道,以将通过 HTTP 发布的 JSON 内容保存到关系数据库中。我们使用 Docker 和 docker-compose 安装了一个本地环境,然后我们部署了源和接收器应用程序,首先在“裸机”上,然后使用 Spring Cloud Data Flow。希望我们学到了一些关于使用 Spring Cloud Stream、Data Flow、Docker 容器、HTTP 源和 JDBC 接收器有趣的知识。
在接下来的几周,我们将展示更多 Spring Cloud Stream 和 Spring Cloud Data Flow 的案例研究,每个案例都将探索不同的流应用程序和功能。