
领先一步
VMware 提供培训和认证,助您加速进步。
了解更多在本系列博客的第一部分中,我们探讨了将 Spring AI 与大型语言模型集成的基础知识。我们逐步构建了一个自定义 ChatClient,利用函数调用进行动态交互,并完善了提示以适应 Spring Petclinic 的用例。最终,我们拥有了一个功能齐全的 AI 助手,能够理解和处理与我们的兽医诊所领域相关的请求。
现在,在第二部分中,我们将通过探索检索增强生成(RAG)进一步深入,这项技术使我们能够处理那些无法通过典型函数调用方法满足的大型数据集。让我们看看 RAG 如何将 AI 与特定领域的知识无缝集成。
虽然列出兽医可以是一个直接的实现,但我选择将其作为一个机会来展示检索增强生成(RAG)的强大功能。
RAG 将大型语言模型与实时数据检索相结合,以生成更准确和上下文相关的文本。尽管这个概念与我们之前的工作一致,但 RAG 通常强调从向量存储中检索数据。
向量存储包含以嵌入形式存在的数据——捕捉信息含义的数值表示,例如关于我们兽医的数据。这些嵌入以高维向量的形式存储,有助于基于语义而非传统基于文本的搜索进行高效的相似性搜索。
例如,考虑以下兽医及其专长:
Alice Brown 医生 - 心脏病学
Bob Smith 医生 - 牙科
Carol White 医生 - 皮肤病学
在传统的搜索中,查询“洗牙”将不会产生精确匹配。然而,通过由嵌入驱动的语义搜索,系统会识别出“洗牙”与“牙科”相关。因此,Bob Smith 医生将被作为最佳匹配返回,即使他的专长从未在查询中明确提及。这说明了嵌入是如何捕捉底层含义而不是仅仅依赖精确关键词的。尽管此过程的实现超出了本文的范围,但您可以通过观看此YouTube 视频了解更多信息。
趣闻:这个例子是由 ChatGPT 自己生成的。
本质上,相似性搜索通过识别搜索查询的数值与源数据最接近的数值进行操作。返回最接近的匹配项。将文本转换为这些数值嵌入的过程也由 LLM 处理。
当处理大量数据时,使用向量存储是最有效的。考虑到六个兽医可以轻松地在一次 LLM 调用中处理,我旨在将数量增加到 256 个。虽然 256 个可能仍然相对较少,但它足以说明我们的过程。
在这种设置中,兽医可以有零个、一个或两个专长,这与 Spring Petclinic 的原始示例相呼应。为了避免手动创建所有这些模拟数据的繁琐任务,我寻求了 ChatGPT 的帮助。它生成了一个联合查询,该查询生成了 250 名兽医,并为其中 80% 的兽医分配了专长。
-- Create a list of first names and last names
WITH first_names AS (
SELECT 'James' AS name UNION ALL
SELECT 'Mary' UNION ALL
SELECT 'John' UNION ALL
...
),
last_names AS (
SELECT 'Smith' AS name UNION ALL
SELECT 'Johnson' UNION ALL
SELECT 'Williams' UNION ALL
...
),
random_names AS (
SELECT
first_names.name AS first_name,
last_names.name AS last_name
FROM
first_names
CROSS JOIN
last_names
ORDER BY
RAND()
LIMIT 250
)
INSERT INTO vets (first_name, last_name)
SELECT first_name, last_name FROM random_names;
-- Add specialties for 80% of the vets
WITH vet_ids AS (
SELECT id
FROM vets
ORDER BY RAND()
LIMIT 200 -- 80% of 250
),
specialties AS (
SELECT id
FROM specialties
),
random_specialties AS (
SELECT
vet_ids.id AS vet_id,
specialties.id AS specialty_id
FROM
vet_ids
CROSS JOIN
specialties
ORDER BY
RAND()
LIMIT 300 -- 2 specialties per vet on average
)
INSERT INTO vet_specialties (vet_id, specialty_id)
SELECT
vet_id,
specialty_id
FROM (
SELECT
vet_id,
specialty_id,
ROW_NUMBER() OVER (PARTITION BY vet_id ORDER BY RAND()) AS rn
FROM
random_specialties
) tmp
WHERE
rn <= 2; -- Assign at most 2 specialties per vet
-- The remaining 20% of vets will have no specialties, so no need for additional insertion commands
为了确保我的数据在每次运行时保持静态和一致,我将 H2 数据库中的相关表导出为硬编码的插入语句。然后,这些语句被添加到data.sql文件中。
INSERT INTO vets VALUES (default, 'James', 'Carter');
INSERT INTO vets VALUES (default, 'Helen', 'Leary');
INSERT INTO vets VALUES (default, 'Linda', 'Douglas');
INSERT INTO vets VALUES (default, 'Rafael', 'Ortega');
INSERT INTO vets VALUES (default, 'Henry', 'Stevens');
INSERT INTO vets VALUES (default, 'Sharon', 'Jenkins');
INSERT INTO vets VALUES (default, 'Matthew', 'Alexander');
INSERT INTO vets VALUES (default, 'Alice', 'Anderson');
INSERT INTO vets VALUES (default, 'James', 'Rogers');
INSERT INTO vets VALUES (default, 'Lauren', 'Butler');
INSERT INTO vets VALUES (default, 'Cheryl', 'Rodriguez');
...
...
-- Total of 256 vets
-- First, let's make sure we have 5 specialties
INSERT INTO specialties (name) VALUES ('radiology');
INSERT INTO specialties (name) VALUES ('surgery');
INSERT INTO specialties (name) VALUES ('dentistry');
INSERT INTO specialties (name) VALUES ('cardiology');
INSERT INTO specialties (name) VALUES ('anesthesia');
INSERT INTO vet_specialties VALUES ('220', '2');
INSERT INTO vet_specialties VALUES ('131', '1');
INSERT INTO vet_specialties VALUES ('58', '3');
INSERT INTO vet_specialties VALUES ('43', '4');
INSERT INTO vet_specialties VALUES ('110', '3');
INSERT INTO vet_specialties VALUES ('63', '5');
INSERT INTO vet_specialties VALUES ('206', '4');
INSERT INTO vet_specialties VALUES ('29', '3');
INSERT INTO vet_specialties VALUES ('189', '3');
...
...
我们有几种可用于向量存储本身的选项。带有 pgVector 扩展的 Postgres 可能是最受欢迎的选择。Greenplum——一个大规模并行 Postgres 数据库——也支持 pgVector。Spring AI 参考文档列出了当前支持的向量存储。
对于我们简单的用例,我选择使用 Spring AI 提供的 SimpleVectorStore。这个类使用一个简单的 Java ConcurrentHashMap 实现了一个向量存储,这对于我们包含 256 名兽医的小数据集来说绰绰有余。这个向量存储的配置,以及聊天内存的实现,都在用 @Configuration 注解的 AIBeanConfiguration 类中定义。
@Configuration
@Profile("openai")
public class AIBeanConfiguration {
@Bean
public ChatMemory chatMemory() {
return new InMemoryChatMemory();
}
@Bean
VectorStore vectorStore(EmbeddingModel embeddingModel) {
return new SimpleVectorStore(embeddingModel);
}
}
向量存储需要在应用程序启动时立即嵌入兽医数据。为了实现这一点,我添加了一个 VectorStoreController bean,其中包含一个监听 ApplicationStartedEvent 的 @EventListener。此方法会在应用程序启动并运行后立即由 Spring 自动调用,确保兽医数据在适当的时间嵌入到向量存储中。
@EventListener
public void loadVetDataToVectorStoreOnStartup(ApplicationStartedEvent event) throws IOException {
// Fetches all Vet entites and creates a document per vet
Pageable pageable = PageRequest.of(0, Integer.MAX_VALUE);
Page<Vet> vetsPage = vetRepository.findAll(pageable);
Resource vetsAsJson = convertListToJsonResource(vetsPage.getContent());
DocumentReader reader = new JsonReader(vetsAsJson);
List<Document> documents = reader.get();
// add the documents to the vector store
this.vectorStore.add(documents);
if (vectorStore instanceof SimpleVectorStore) {
var file = File.createTempFile("vectorstore", ".json");
((SimpleVectorStore) this.vectorStore).save(file);
logger.info("vector store contents written to {}", file.getAbsolutePath());
}
logger.info("vector store loaded with {} documents", documents.size());
}
public Resource convertListToJsonResource(List<Vet> vets) {
ObjectMapper objectMapper = new ObjectMapper();
try {
// Convert List<Vet> to JSON string
String json = objectMapper.writeValueAsString(vets);
// Convert JSON string to byte array
byte[] jsonBytes = json.getBytes();
// Create a ByteArrayResource from the byte array
return new ByteArrayResource(jsonBytes);
}
catch (JsonProcessingException e) {
e.printStackTrace();
return null;
}
}
这里有很多内容需要理解,所以让我们来看看代码:
与 listOwners 类似,我们首先从数据库中检索所有兽医。
Spring AI 将 Document 类型的实体嵌入到向量存储中。Document 表示嵌入的数值数据及其原始的、人类可读的文本数据。这种双重表示允许我们的代码将嵌入向量与自然文本之间的关联映射起来。
为了创建这些 Document 实体,我们需要将我们的 Vet 实体转换为文本格式。Spring AI 为此提供了两个内置读取器:JsonReader 和 TextReader。由于我们的 Vet 实体是结构化数据,因此将它们表示为 JSON 格式是合理的。为此,我们使用辅助方法 convertListToJsonResource,该方法利用 Jackson 解析器将兽医列表转换为内存中的 JSON 资源。
接下来,我们调用向量存储上的 add(documents) 方法。此方法负责通过遍历文档列表(我们的 JSON 格式的兽医)并嵌入每个文档,同时将其原始元数据与之关联来嵌入数据。
虽然并非严格要求,但我们也生成了一个 vectorstore.json 文件,它表示我们的 SimpleVectorStore 数据库的状态。此文件允许我们观察 Spring AI 在幕后如何解释存储的数据。让我们看看生成的文件,以了解 Spring AI 看到的内容。
{
"dd919c71-06bb-4777-b974-120dfee8b9f9" : {
"embedding" : [ 0.013877872, 0.03598228, 0.008212427, 0.00917901, -0.036433823, 0.03253927, -0.018089917, -0.0030867155, -0.0017038669, -0.048145704, 0.008974405, 0.017624263, 0.017539598, -4.7888185E-4, 0.013842596, -0.0028221398, 0.033414137, -0.02847539, -0.0066955267, -0.021885695, -0.0072387885, 0.01673529, -0.007386951, 0.014661016, -0.015380662, 0.016184973, 0.00787377, -0.019881975, -0.0028785826, -0.023875304, 0.024778388, -0.02357898, -0.023748307, -0.043094076, -0.029322032, ... ],
"content" : "{id=31, firstName=Samantha, lastName=Walker, new=false, specialties=[{id=2, name=surgery, new=false}]}",
"id" : "dd919c71-06bb-4777-b974-120dfee8b9f9",
"metadata" : { },
"media" : [ ]
},
"4f9aabed-c15c-43f6-9dbc-46ed9a18e176" : {
"embedding" : [ 0.01051745, 0.032714732, 0.007800559, -0.0020621764, -0.03240663, 0.025530376, 0.0037602335, -0.0023702774, -0.004978633, -0.037364256, 0.0012831709, 0.032742742, 0.005430281, 0.00847278, -0.004285406, 0.01146276, 0.03036196, -0.029941821, 0.013220336, -0.03207052, -7.518716E-4, 0.016665466, -0.0052062077, 0.010678503, 0.0026591222, 0.0091940155, ... ],
"content" : "{id=195, firstName=Shirley, lastName=Martinez, new=false, specialties=[{id=1, name=radiology, new=false}, {id=2, name=surgery, new=false}]}",
"id" : "4f9aabed-c15c-43f6-9dbc-46ed9a18e176",
"metadata" : { },
"media" : [ ]
},
"55b13970-cd55-476b-b7c9-62337855ae0a" : {
"embedding" : [ -0.0031563698, 0.03546827, 0.018778138, -0.01324492, -0.020253662, 0.027756566, 0.007182742, -0.008637386, -0.0075725033, -0.025543278, 5.850768E-4, 0.02568248, 0.0140383635, -0.017330453, 0.003935892, ... ],
"content" : "{id=19, firstName=Jacqueline, lastName=Ross, new=false, specialties=[{id=4, name=cardiology, new=false}]}",
"id" : "55b13970-cd55-476b-b7c9-62337855ae0a",
"metadata" : { },
"media" : [ ]
},
...
...
...
真酷!我们有一个 JSON 格式的 Vet,旁边还有一组数字,虽然它们对我们来说可能没什么意义,但对 LLM 来说却意义重大。这些数字代表嵌入的向量数据,模型用它来理解 Vet 实体之间的关系和语义,其方式远超简单的文本匹配。
如果我们在每次应用程序重启时都运行此嵌入方法,将会导致两个显著的缺点:
启动时间长:每个 Vet JSON 文档都需要通过再次调用 LLM 重新嵌入,从而延迟应用程序就绪。
成本增加:每次应用程序启动时,嵌入 256 个文档将向 LLM 发送 256 个请求,导致不必要的 LLM 信用消耗。
嵌入更适合 ETL(抽取、转换、加载)或流处理,这些过程独立于主 Web 应用程序运行。这些过程可以在后台处理嵌入,而不会影响用户体验或产生不必要的成本。
为了简化 Spring Petclinic 中的操作,我决定在启动时加载预嵌入的向量存储。这种方法可以实现即时加载并避免任何额外的 LLM 成本。这是实现该目标的方法的补充:
@EventListener
public void loadVetDataToVectorStoreOnStartup(ApplicationStartedEvent event) throws IOException {
Resource resource = new ClassPathResource("vectorstore.json");
// Check if file exists
if (resource.exists()) {
// In order to save on AI credits, use a pre-embedded database that was saved
// to disk based on the current data in the h2 data.sql file
File file = resource.getFile();
((SimpleVectorStore) this.vectorStore).load(file);
logger.info("vector store loaded from existing vectorstore.json file in the classpath");
return;
}
// Rest of the method as before
...
...
}
vectorstore.json 文件位于 src/main/resources 下,这确保应用程序在启动时总是加载预嵌入的向量存储,而不是从头开始重新嵌入数据。如果我们需要重新生成向量存储,只需删除现有的 vectorstore.json 文件并重新启动应用程序即可。一旦生成了更新的向量存储,我们可以将新的 vectorstore.json 文件放回 src/main/resources。这种方法提供了灵活性,同时避免了在常规重启期间不必要的重新嵌入过程。
有了我们准备好的向量存储,实现 listVets 函数变得简单明了。该函数定义如下:
@Bean
@Description("List the veterinarians that the pet clinic has")
public Function<VetRequest, VetResponse> listVets(AIDataProvider petclinicAiProvider) {
return request -> {
try {
return petclinicAiProvider.getVets(request);
}
catch (JsonProcessingException e) {
e.printStackTrace();
return null;
}
};
}
record VetResponse(List<String> vet) {
};
record VetRequest(Vet vet) {
}
这是 AIDataProvider 中的实现:
public VetResponse getVets(VetRequest request) throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
String vetAsJson = objectMapper.writeValueAsString(request.vet());
SearchRequest sr = SearchRequest.from(SearchRequest.defaults()).withQuery(vetAsJson).withTopK(20);
if (request.vet() == null) {
// Provide a limit of 50 results when zero parameters are sent
sr = sr.withTopK(50);
}
List<Document> topMatches = this.vectorStore.similaritySearch(sr);
List<String> results = topMatches.stream().map(document -> document.getContent()).toList();
return new VetResponse(results);
}
让我们回顾一下我们在这里做了什么:
我们从请求中的 Vet 实体开始。由于向量存储中的记录表示为 JSON,第一步是将 Vet 实体也转换为 JSON。
接下来,我们创建一个 SearchRequest,它是传递给向量存储的 similaritySearch 方法的参数。SearchRequest 允许我们根据特定需求微调搜索。在这种情况下,我们主要使用默认值,除了 topK 参数,它决定返回多少结果。默认情况下,它设置为 4,但在我们的例子中,我们将其增加到 20。这使我们能够处理更广泛的查询,例如“有多少兽医专攻心脏病学?”
如果请求中未提供任何过滤器(即 Vet 实体为空),我们会将 topK 值增加到 50。这使我们能够针对“列出诊所中的兽医”等查询返回最多 50 位兽医。当然,这不会是完整的列表,因为我们希望避免用过多数据淹没 LLM。然而,我们应该没问题,因为我们仔细调整了系统文本来管理这些情况。
When dealing with vets, if the user is unsure about the returned results,
explain that there may be additional data that was not returned.
Only if the user is asking about the total number of all vets,
answer that there are a lot and ask for some additional criteria.
For owners, pets or visits - answer the correct data.
最后一步是调用 similaritySearch 方法。然后,我们将每个返回结果的 getContent() 进行映射,因为这包含实际的 Vet JSON,而不是嵌入数据。
从这里开始,一切照旧。LLM 完成函数调用,检索结果,并确定如何在聊天中最佳地显示数据。
让我们看看它的实际效果:
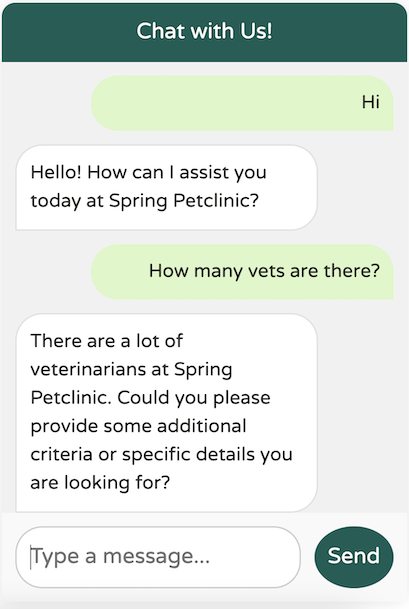
看起来我们的系统文本功能正常,避免了任何过载。现在,让我们尝试提供一些具体标准:
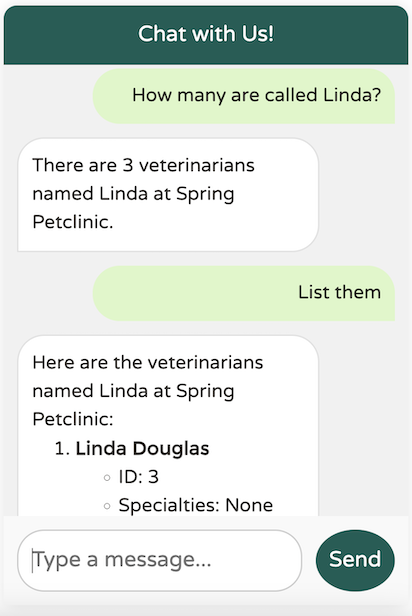
LLM 返回的数据与我们的预期完全一致。让我们尝试一个更广泛的问题:

LLM 成功识别出至少 20 名专攻心脏病学的兽医,符合我们定义的 topK 上限(20)。然而,如果对结果有任何不确定性,LLM 会指出可能还有其他可用的兽医,正如我们的系统文本中指定的那样。
实现聊天机器人 UI 涉及使用 Thymeleaf、JavaScript、CSS 和 SCSS 预处理器。
在审查代码后,我决定将聊天机器人放置在一个可以从任何选项卡访问的位置,这使得 layout.html 成为理想的选择。
在与 Dave Syer 博士讨论 PR 时,我意识到我不应该直接修改 petclinic.css,因为 Spring Petclinic 使用 SCSS 预处理器来生成 CSS 文件。
我承认——我主要是一名后端 Spring 开发人员,职业生涯专注于 Spring、云架构、Kubernetes 和 Cloud Foundry。虽然我有一些 Angular 经验,但我不是前端开发专家。我或许能想出一些东西,但它可能看起来不够精致。
幸运的是,我有一个很棒的结对编程伙伴——ChatGPT。如果您对我是如何开发 UI 代码感兴趣,可以查看这个ChatGPT 会话。与大型语言模型协作进行编码练习能学到很多东西,这令人惊叹。请记住,要仔细审查建议,而不是盲目地复制粘贴。
在 Spring AI 上实验了几个月后,我深深体会到这个项目背后的深思熟虑和努力。Spring AI 真正独特之处在于,它允许开发人员探索 AI 的世界,而无需培训数百名团队成员学习 Python 等新语言。更重要的是,这种体验突显了一个更大的优势:您的 AI 代码可以与您现有的业务逻辑共存,位于同一个代码库中。您只需添加几个额外的类,即可轻松地用 AI 功能增强遗留代码库。避免在新的 AI 特定应用程序中从头开始重建所有数据,这极大地提高了生产力。即使是 IDE 中现有 JPA 实体的自动代码完成等简单功能也能带来巨大的不同。
Spring AI 有潜力通过简化 AI 功能的集成来显著增强基于 Spring 的应用程序。它使开发人员能够利用机器学习模型和 AI 驱动的服务,而无需深入的数据科学专业知识。通过抽象复杂的 AI 操作并将其直接嵌入到熟悉的 Spring 框架中,开发人员可以专注于快速构建智能、数据驱动的功能。这种 AI 与 Spring 的无缝融合营造了一个创新不受技术障碍阻碍的环境,为开发更智能、更具适应性的应用程序创造了新机遇。