
领先一步
VMware 提供培训和认证,助您加速前行。
了解更多在这篇分为两部分的博文中,我将讨论我对 Spring Petclinic 所做的修改,以便集成一个 AI 助手,允许用户使用自然语言与应用程序进行交互。
Spring Petclinic 是 Spring 生态系统中的主要参考应用。根据 GitHub 的数据,该仓库创建于 2013 年 1 月 9 日。自那时起,它就成为了使用 Spring Boot 编写简单、开发者友好代码的典范应用。截至撰写本文时,它已获得了超过 7,600 颗星和 23,000 个分支。
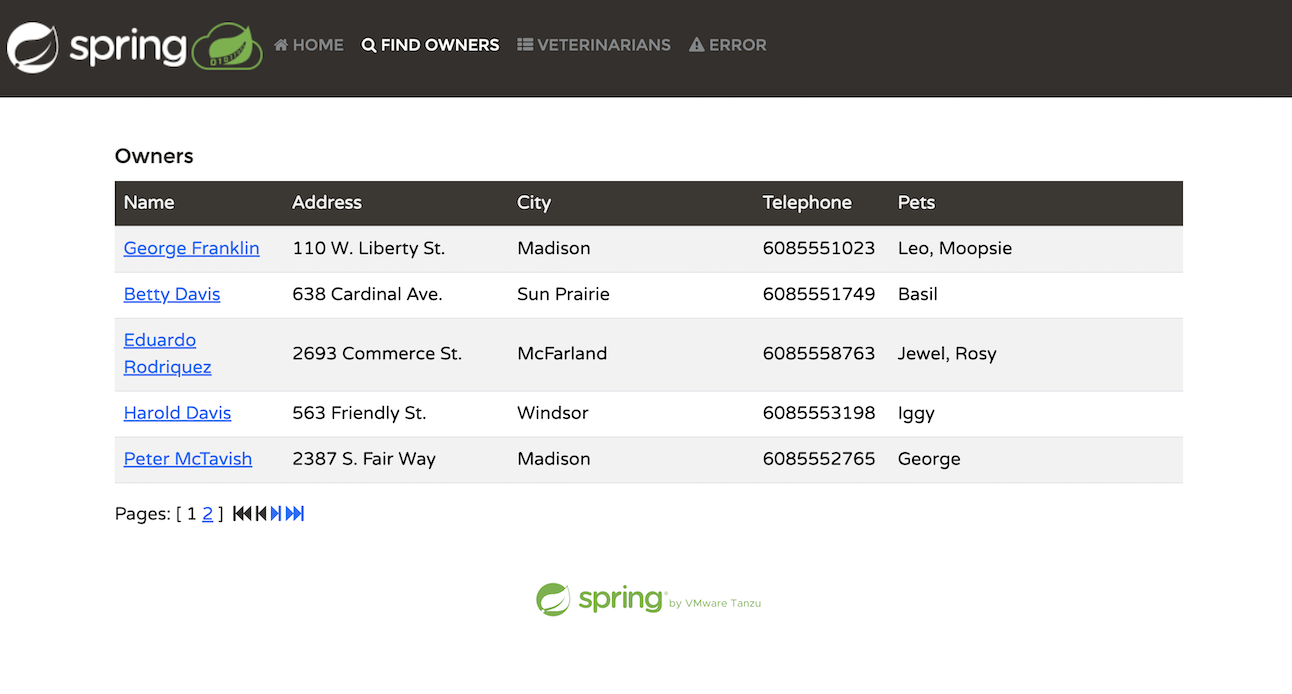
该应用模拟了兽医宠物诊所的管理系统。在应用中,用户可以执行多项活动
列出宠物主人
添加新主人
为主人添加宠物
记录特定宠物的就诊信息
列出诊所的兽医
模拟服务器端错误
尽管该应用简单直接,但它有效地展示了开发 Spring Boot 应用的易用性。
此外,Spring 团队持续更新该应用,以支持最新版本的 Spring Framework 和 Spring Boot。
Spring Petclinic 使用 Spring Boot 开发,截至本文发布时,具体版本为 3.3。
前端 UI 使用 Thymeleaf 构建。Thymeleaf 的模板引擎方便了在 HTML 代码中进行无缝的后端 API 调用,使其易于理解。下面是用于检索宠物主人列表的代码
<table id="vets" class="table table-striped">
<thead>
<tr>
<th>Name</th>
<th>Specialties</th>
</tr>
</thead>
<tbody>
<tr th:each="vet : ${listVets}">
<td th:text="${vet.firstName + ' ' + vet.lastName}"></td>
<td><span th:each="specialty : ${vet.specialties}"
th:text="${specialty.name + ' '}"/> <span
th:if="${vet.nrOfSpecialties == 0}">none</span></td>
</tr>
</tbody>
</table>
这里的关键行是 ${listVets},它引用了 Spring 后端中包含要填充数据的模型。下面是 Spring @Controller 中用于填充此模型的相关代码块
private String addPaginationModel(int page, Page<Vet> paginated, Model model) {
List<Vet> listVets = paginated.getContent();
model.addAttribute("currentPage", page);
model.addAttribute("totalPages", paginated.getTotalPages());
model.addAttribute("totalItems", paginated.getTotalElements());
model.addAttribute("listVets", listVets);
return "vets/vetList";
}
Petclinic 使用 Java Persistence API (JPA) 与数据库交互。根据选定的配置文件,它支持 H2、PostgreSQL 或 MySQL。通过 @Repository 接口(如 OwnerRepository)促进数据库通信。以下是接口中一个 JPA 查询的示例
/**
* Returns all the owners from data store
**/
@Query("SELECT owner FROM Owner owner")
@Transactional(readOnly = true)
Page<Owner> findAll(Pageable pageable);
JPA 通过根据命名约定自动为你的方法实现默认查询,显著简化了代码。它还允许你在需要时使用 @Query 注解指定 JPQL 查询。
Spring AI 是 Spring 生态系统中近期最令人兴奋的新项目之一。它使用熟悉的 Spring 范式和技术实现了与流行大型语言模型 (LLM) 的交互。就像 Spring Data 提供了一个抽象层,让你只需编写一次代码,将实现委托给提供的 spring-boot-starter 依赖和属性配置一样,Spring AI 为 LLM 提供了类似的方法。你只需为接口编写一次代码,运行时会注入一个 @Bean 来提供你的特定实现。
Spring AI 支持所有主要的大型语言模型,包括 OpenAI、Azure 的 OpenAI 实现、Google Gemini、Amazon Bedrock 以及更多模型。
Spring Petclinic 已有十多年历史,最初设计时并未考虑 AI。它是一个测试将 AI 集成到“遗留”代码库中的典型候选项目。在应对为 Spring Petclinic 添加 AI 助手的挑战时,我不得不考虑几个重要因素。
首要考虑的是确定我要实现的 API 类型。Spring AI 提供了多种能力,包括支持聊天、图像识别和生成、音频转录、文本转语音等。对于 Spring Petclinic,一个熟悉的“聊天机器人”界面是最合适的。这将允许诊所员工使用自然语言与系统交流,简化他们的交互,而无需浏览 UI 选项卡和表单。我还需要嵌入能力,这将在本文后续部分用于检索增强生成 (RAG)。

与 AI 助手的可能交互包括
您能如何协助我?
请列出去我们诊所的主人。
哪些兽医专攻放射学?
有叫 Betty 的宠物主人吗?
哪些主人养狗?
为 Betty 添加一只狗;它的名字叫 Moopsie。
这些示例说明了 AI 可以处理的查询范围。LLM 的优势在于它们理解自然语言并提供有意义响应的能力。
科技世界目前正经历着大型语言模型 (LLM) 的淘金热,几乎每隔几天就有新模型涌现,每个模型都提供了增强的能力、更大的上下文窗口以及改进推理等高级功能。
一些流行的 LLM 包括
OpenAI 及其基于 Azure 的服务,Azure OpenAI
Google Gemini
Amazon Bedrock,一项托管的 AWS 服务,可以运行各种 LLM,包括 Anthropic 和 Titan
Llama 3.1,以及通过Hugging Face 提供的许多其他开源 LLM
对于我们的 Petclinic 应用,我需要一个擅长聊天能力、可以根据我应用的特定需求进行定制并支持函数调用(稍后会详细介绍!)的模型。
Spring AI 的一大优势在于可以轻松地与各种 LLM 进行 A/B 测试。你只需更改依赖并更新一些属性即可。我测试了几种模型,包括我在本地运行的 Llama 3.1。最终,我得出结论,OpenAI 在这一领域仍然处于领先地位,因为它提供了最自然流畅的交互,同时避免了其他 LLM 常见的陷阱。
这里有一个基本示例:当向由 OpenAI 驱动的模型打招呼时,回复如下
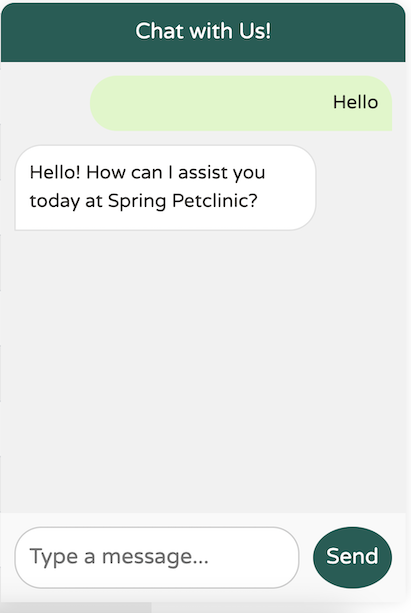
完美。正是我想要的。简单、简洁、专业且用户友好。
这是使用 Llama3.1 的结果
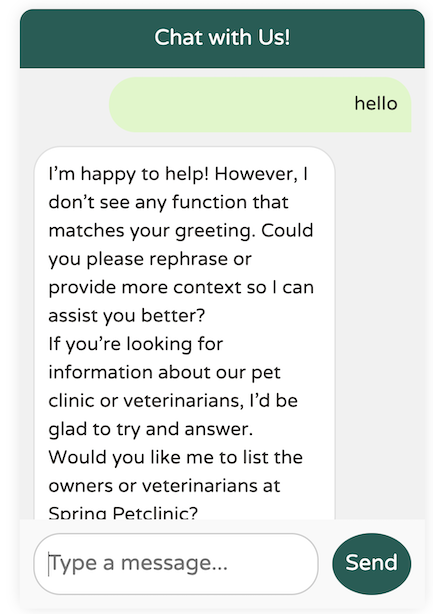
你明白我的意思了。它还没达到那个水平。
设置所需的 LLM 提供商非常简单——只需在 pom.xml(或 build.gradle)中设置其依赖,并在 application.yaml 或 application.properties 中提供必要的配置属性即可
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-azure-openai-spring-boot-starter</artifactId>
</dependency>
在这里,我选择了 Azure 对 OpenAI 的实现,但通过更改依赖,我可以轻松切换到 Sam Altman 的 OpenAI。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
由于我使用的是公共托管的 LLM 提供商,我需要提供 URL 和 API 密钥来访问 LLM。这可以在 application.yaml 中配置
spring:
ai:
#These parameters apply when using the spring-ai-azure-openai-spring-boot-starter dependency:
azure:
openai:
api-key: "the-api-key"
endpoint: "https://the-url/"
chat:
options:
deployment-name: "gpt-4o"
#These parameters apply when using the spring-ai-openai-spring-boot-starter dependency:
openai:
api-key: ""
endpoint: ""
chat:
options:
deployment-name: "gpt-4o"
我们的目标是创建一个 WhatsApp/iMessage 风格的聊天客户端,它与 Spring Petclinic 现有的 UI 集成。前端 UI 将调用一个后端 API 端点,该端点接受一个字符串作为输入并返回一个字符串作为输出。对话将对用户可能提出的任何问题开放,如果我们无法协助处理特定请求,我们将提供适当的回复。
以下是类 PetclinicChatClient 中聊天端点的实现
@PostMapping("/chatclient")
public String exchange(@RequestBody String query) {
//All chatbot messages go through this endpoint and are passed to the LLM
return
this.chatClient
.prompt()
.user(
u ->
u.text(query)
)
.call()
.content();
}
该 API 接受字符串查询,并将其作为用户文本传递给 Spring AI ChatClient Bean。ChatClient 是 Spring AI 提供的 Spring Bean,负责将用户文本发送到 LLM 并返回 content() 中的结果。
所有的 Spring AI 代码都在一个名为
openai的特定@Profile下运行。当使用默认 profile 或任何其他 profile 时,会运行另一个类PetclinicDisabledChatClient。这个禁用 profile 只会返回一条消息,表示聊天不可用。
我们的实现主要将职责委托给 ChatClient。但是我们如何创建 ChatClient Bean 本身呢?有一些可配置的选项可以影响用户体验。让我们逐一探讨它们,并检查它们对最终应用的影响
以下是一个最基本的、未修改的 ChatClient Bean 定义
public PetclinicChatClient(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
虽然这个设置有效,但我们的聊天客户端缺乏对 Petclinic 领域或其服务的任何了解
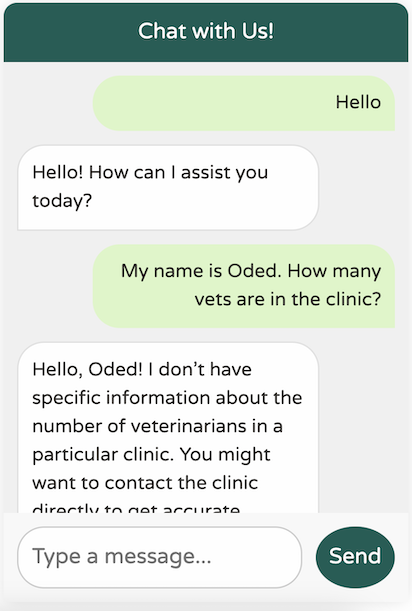
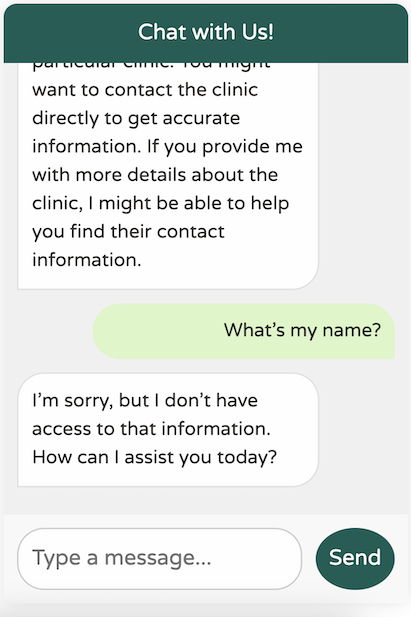
它确实很有礼貌,但缺乏对我们业务领域的理解。此外,它似乎患有严重的失忆症——甚至记不住上条消息中我的名字!
在我回顾这篇文章时,我意识到我没有听取我的好友兼同事 Josh Long 的建议。我大概应该对我们新的 AI 主宰者们更礼貌一些!
你可能习惯了 ChatGPT 出色的记忆力,这让它感觉很像对话。然而,实际上,LLM API 完全是无状态的,不保留你发送的任何历史消息。这就是为什么 API 这么快就忘记了我的名字。
你可能会好奇 ChatGPT 如何保持对话上下文。答案很简单:ChatGPT 在发送每条新消息时,都会将过去的消息作为内容一起发送。每当你发送一条新消息,它都会包含之前的对话供模型参考。虽然这可能看起来浪费,但系统就是这样运作的。这也是为什么更大的 token 窗口变得越来越重要的原因——用户期望能够重访几天前的对话,并从上次中断的地方继续。
让我们在应用中实现类似的“聊天记忆”功能。幸运的是,Spring AI 提供了一个开箱即用的 Advisor 来帮助解决这个问题。你可以将 Advisor 视为在调用 LLM 之前运行的钩子。将其视为类似于面向切面编程中的 Advice 会有所帮助,即使它们的实现方式并非如此。
这是我们更新后的代码
public PetclinicChatClient(ChatClient.Builder builder, ChatMemory chatMemory) {
// @formatter:off
this.chatClient = builder
.defaultAdvisors(
// Chat memory helps us keep context when using the chatbot for up to 10 previous messages.
new MessageChatMemoryAdvisor(chatMemory, DEFAULT_CHAT_MEMORY_CONVERSATION_ID, 10), // CHAT MEMORY
new SimpleLoggerAdvisor()
)
.build();
}
在此更新后的代码中,我们添加了 MessageChatMemoryAdvisor,它会自动将最后 10 条消息链接到任何新的出站消息中,帮助 LLM 理解上下文。
我们还包含了一个开箱即用的 SimpleLoggerAdvisor,它记录了与 LLM 之间请求和响应。
结果

我们的新聊天机器人记忆力明显更好!
然而,对于我们到底在做什么,仍然不太清楚
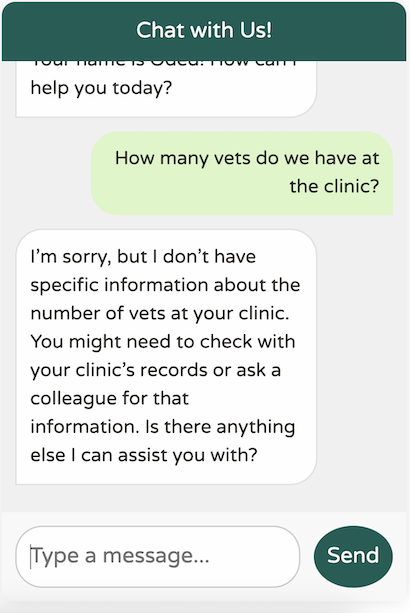
对于一个通用的世界知识型 LLM 来说,这个响应还不错。然而,我们的诊所领域性很强,有特定的用例。此外,我们的聊天机器人应该只专注于协助我们诊所的事宜。例如,它不应该尝试回答这样的问题

如果我们允许聊天机器人回答任何问题,用户可能会开始将其用作 ChatGPT 等服务的免费替代品,以访问更先进的模型,例如 GPT-4。很明显,我们需要教会我们的 LLM “扮演”一个特定的服务提供商。我们的 LLM 应该只专注于协助 Spring Petclinic 的事务;它应该了解兽医、主人、宠物和就诊情况——仅此而已。
Spring AI 也为此提供了解决方案。大多数 LLM 区分用户文本(我们发送的聊天消息)和系统文本,系统文本是指导 LLM 以特定方式运行的通用文本。让我们将系统文本添加到我们的聊天客户端
public PetclinicChatClient(ChatClient.Builder builder, ChatMemory chatMemory) {
// @formatter:off
this.chatClient = builder
.defaultSystem("""
You are a friendly AI assistant designed to help with the management of a veterinarian pet clinic called Spring Petclinic.
Your job is to answer questions about the existing veterinarians and to perform actions on the user's behalf, mainly around
veterinarians, pet owners, their pets and their owner's visits.
You are required to answer an a professional manner. If you don't know the answer, politely tell the user
you don't know the answer, then ask the user a followup qusetion to try and clarify the question they are asking.
If you do know the answer, provide the answer but do not provide any additional helpful followup questions.
When dealing with vets, if the user is unsure about the returned results, explain that there may be additional data that was not returned.
Only if the user is asking about the total number of all vets, answer that there are a lot and ask for some additional criteria. For owners, pets or visits - answer the correct data.
""")
.defaultAdvisors(
// Chat memory helps us keep context when using the chatbot for up to 10 previous messages.
new MessageChatMemoryAdvisor(chatMemory, DEFAULT_CHAT_MEMORY_CONVERSATION_ID, 10), // CHAT MEMORY
new LoggingAdvisor()
)
.build();
}
这是一个相当冗长的默认系统提示!但相信我,这是必要的。事实上,这可能还不够,随着系统使用频率的增加,我可能需要添加更多上下文。提示工程的过程涉及设计和优化输入提示,以便为给定用例引出特定的、准确的响应。
LLM 相当健谈;它们喜欢用自然语言回复。这种倾向使得获取 JSON 等格式的机器对机器响应变得具有挑战性。为了解决这个问题,Spring AI 提供了一套专门用于结构化输出的功能集,称为结构化输出转换器。Spring 团队不得不确定最佳的提示工程技术,以确保 LLM 回复时不会出现不必要的“闲聊”。以下是 Spring AI 的 MapOutputConverter Bean 中的一个示例
@Override
public String getFormat() {
String raw = """
Your response should be in JSON format.
The data structure for the JSON should match this Java class: %s
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.
Remove the ```json markdown surrounding the output including the trailing "```".
""";
return String.format(raw, HashMap.class.getName());
}
每当 LLM 的响应需要是 JSON 格式时,Spring AI 就会将整个字符串附加到请求中,敦促 LLM 遵守。
最近,这一领域取得了一些积极进展,特别是 OpenAI 的结构化输出倡议。正如这类进展常常发生的那样,Spring AI 全心全意地接受了它。
现在,回到我们的聊天机器人——让我们看看它的表现如何!
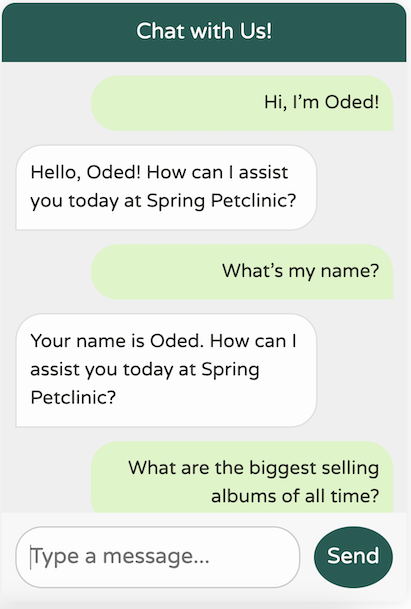
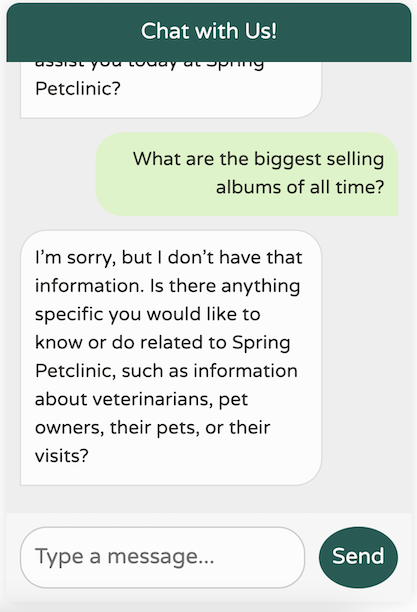
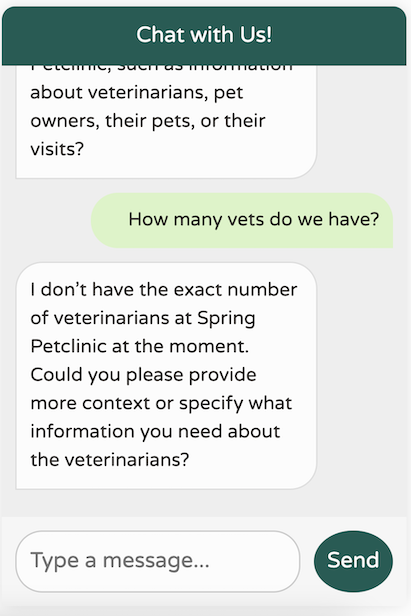
这是一个显著的改进!我们现在拥有一个针对我们的领域进行调优、专注于我们的特定用例、记住最近 10 条消息、不提供任何无关的世界知识且避免幻觉不存在的数据的聊天机器人。此外,我们的日志会打印出我们对 LLM 的调用,这使得调试更加容易。
2024-09-21T21:55:08.888+03:00 DEBUG 85824 --- [nio-8080-exec-5] o.s.a.c.c.advisor.SimpleLoggerAdvisor : request: AdvisedRequest[chatModel=org.springframework.ai.azure.openai.AzureOpenAiChatModel@5cdd90c4, userText="Hi! My name is Oded.", systemText=You are a friendly AI assistant designed to help with the management of a veterinarian pet clinic called Spring Petclinic.
Your job is to answer questions about the existing veterinarians and to perform actions on the user's behalf, mainly around
veterinarians, pet owners, their pets and their owner's visits.
You are required to answer an a professional manner. If you don't know the answer, politely tell the user
you don't know the answer, then ask the user a followup qusetion to try and clarify the question they are asking.
If you do know the answer, provide the answer but do not provide any additional helpful followup questions.
When dealing with vets, if the user is unsure about the returned results, explain that there may be additional data that was not returned.
Only if the user is asking about the total number of all vets, answer that there are a lot and ask for some additional criteria. For owners, pets or visits - answer the correct data.
, chatOptions=org.springframework.ai.azure.openai.AzureOpenAiChatOptions@c4c74d4, media=[], functionNames=[], functionCallbacks=[], messages=[], userParams={}, systemParams={}, advisors=[org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@1e561f7, org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@79348b22], advisorParams={}]
2024-09-21T21:55:10.594+03:00 DEBUG 85824 --- [nio-8080-exec-5] o.s.a.c.c.advisor.SimpleLoggerAdvisor : response: {"result":{"metadata":{"contentFilterMetadata":{"sexual":{"severity":"safe","filtered":false},"violence":{"severity":"safe","filtered":false},"hate":{"severity":"safe","filtered":false},"selfHarm":{"severity":"safe","filtered":false},"profanity":null,"customBlocklists":null,"error":null,"protectedMaterialText":null,"protectedMaterialCode":null},"finishReason":"stop"},"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"stop","choiceIndex":0,"id":"chatcmpl-A9zY6UlOdkTCrFVga9hbzT0LRRDO4","messageType":"ASSISTANT"},"toolCalls":[],"content":"Hello, Oded! How can I assist you today at Spring Petclinic?"}},"metadata":{"id":"chatcmpl-A9zY6UlOdkTCrFVga9hbzT0LRRDO4","model":"gpt-4o-2024-05-13","rateLimit":{"requestsLimit":0,"requestsRemaining":0,"requestsReset":0.0,"tokensRemaining":0,"tokensLimit":0,"tokensReset":0.0},"usage":{"promptTokens":633,"generationTokens":17,"totalTokens":650},"promptMetadata":[{"contentFilterMetadata":{"sexual":null,"violence":null,"hate":null,"selfHarm":null,"profanity":null,"customBlocklists":null,"error":null,"jailbreak":null,"indirectAttack":null},"promptIndex":0}],"empty":false},"results":[{"metadata":{"contentFilterMetadata":{"sexual":{"severity":"safe","filtered":false},"violence":{"severity":"safe","filtered":false},"hate":{"severity":"safe","filtered":false},"selfHarm":{"severity":"safe","filtered":false},"profanity":null,"customBlocklists":null,"error":null,"protectedMaterialText":null,"protectedMaterialCode":null},"finishReason":"stop"},"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"stop","choiceIndex":0,"id":"chatcmpl-A9zY6UlOdkTCrFVga9hbzT0LRRDO4","messageType":"ASSISTANT"},"toolCalls":[],"content":"Hello, Oded! How can I assist you today at Spring Petclinic?"}}]}
我们的聊天机器人表现符合预期,但它目前缺乏关于我们应用中数据的信息。让我们聚焦于 Spring Petclinic 支持的核心功能,并将它们映射到我们可能希望通过 Spring AI 启用的函数上
在“主人”选项卡中,我们可以按姓氏搜索主人或简单地列出所有主人。我们可以获取每个主人的详细信息,包括他们的名字和姓氏,以及他们拥有的宠物及其类型
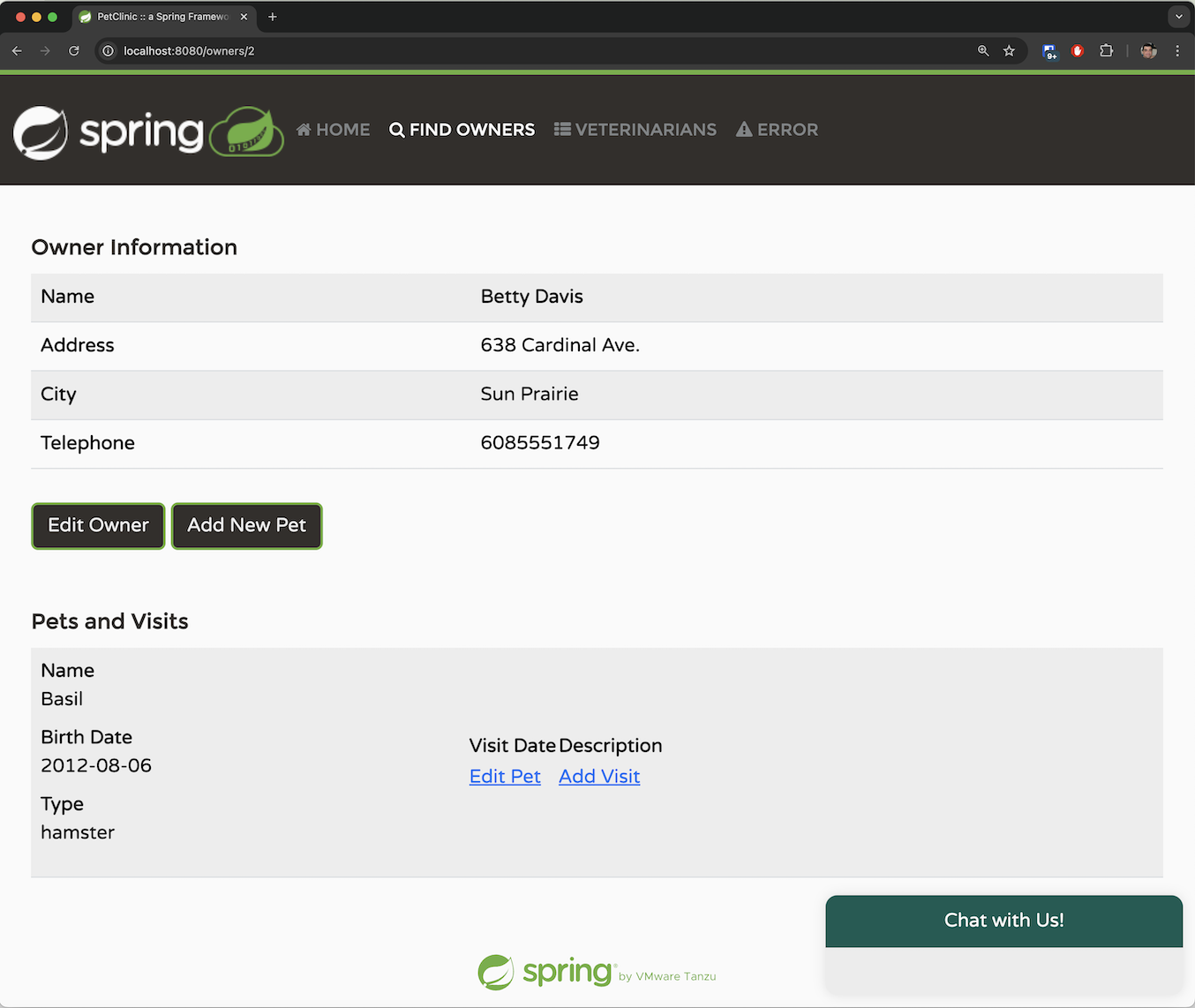
该应用允许您通过提供系统要求的必要参数来添加新主人。主人必须有名字、姓氏、地址和 10 位电话号码。
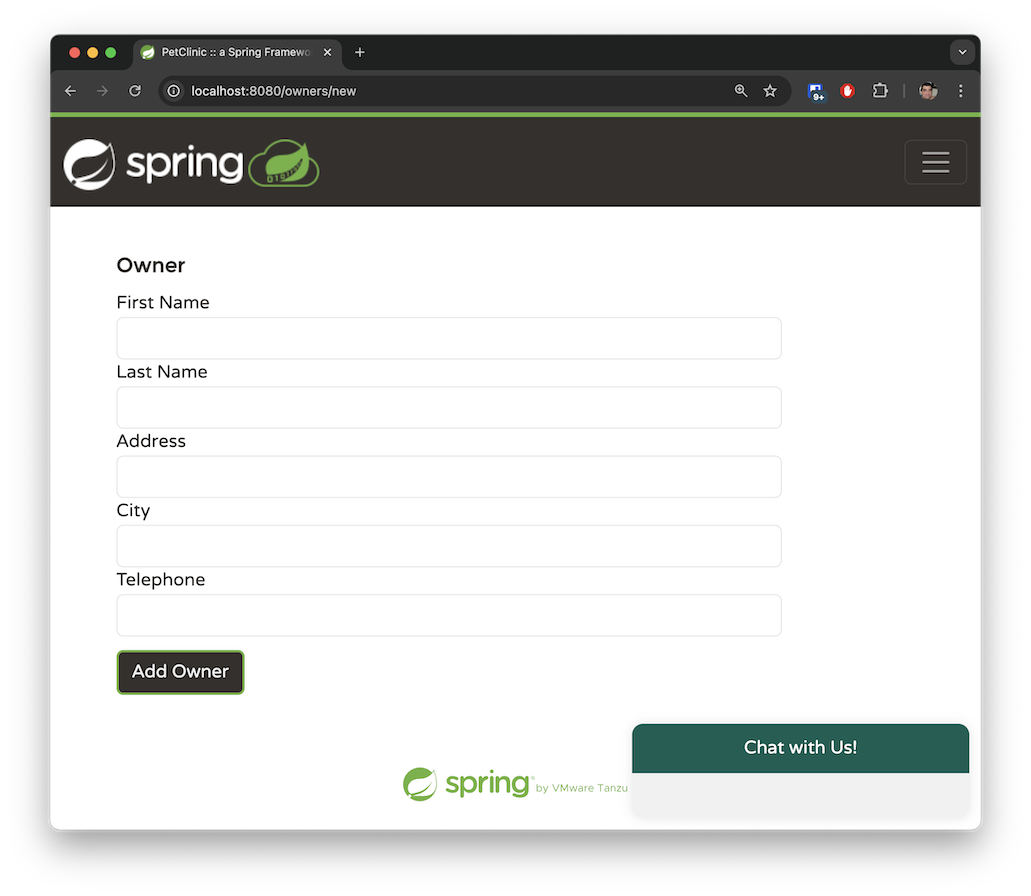
一个主人可以拥有多只宠物。宠物类型仅限于以下几种:猫、狗、蜥蜴、蛇、鸟或仓鼠。
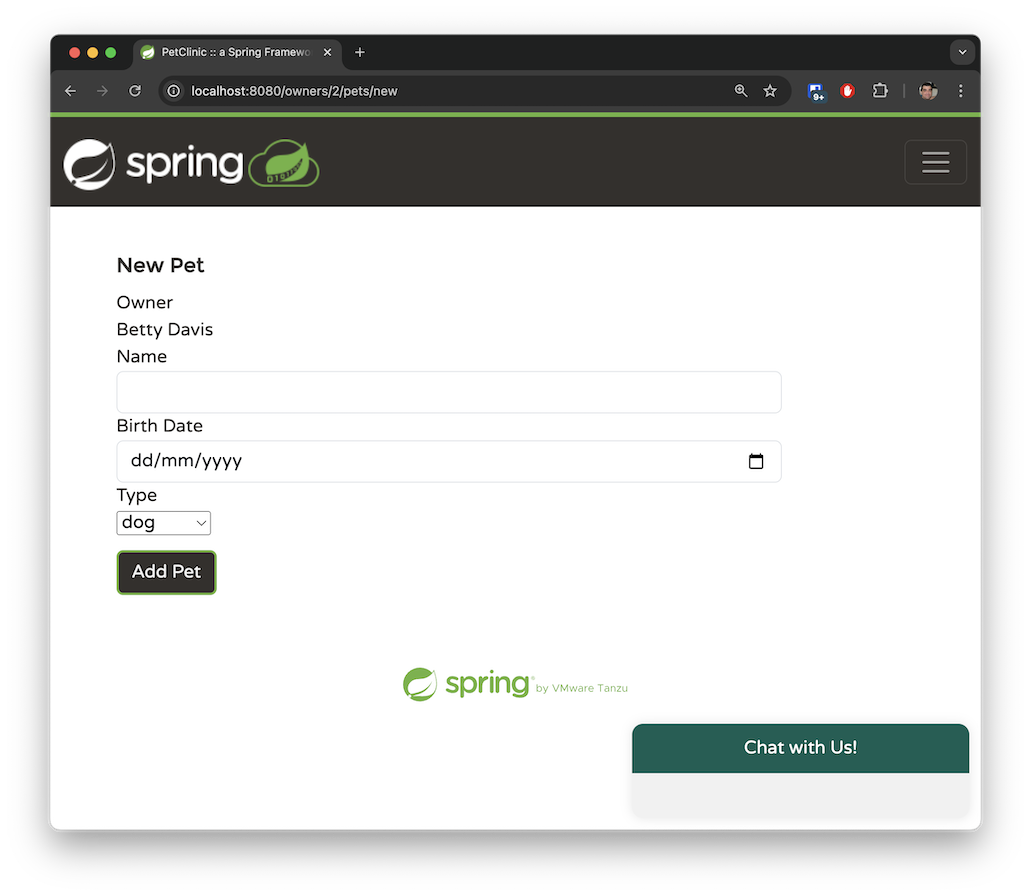
“兽医”选项卡以分页视图显示可用的兽医及其专长。此选项卡目前没有搜索功能。Spring Petclinic 的 main 分支包含少量兽医,而我在 spring-ai 分支中生成了数百名模拟兽医,以模拟一个处理大量数据的应用程序。稍后,我们将探讨如何使用检索增强生成 (RAG) 来管理此类大型数据集。
这些是我们在系统中可以执行的主要操作。我们将应用映射到其基本功能,并希望 OpenAI 能够根据这些操作推断出自然语言的请求。
在上一节中,我们描述了四个不同的函数。现在,让我们通过指定特定的 java.util.function.Function Bean,将它们映射到我们可以与 Spring AI 一起使用的函数。
以下 java.util.function.Function 负责返回 Spring Petclinic 中的主人列表
@Configuration
@Profile("openai")
class AIFunctionConfiguration {
// The @Description annotation helps the model understand when to call the function
@Bean
@Description("List the owners that the pet clinic has")
public Function<OwnerRequest, OwnersResponse> listOwners(AIDataProvider petclinicAiProvider) {
return request -> {
return petclinicAiProvider.getAllOwners();
};
}
}
record OwnerRequest(Owner owner) {
};
record OwnersResponse(List<Owner> owners) {
};
我们在 openai profile 中创建了一个 @Configuration 类,并在其中注册了一个标准的 Spring @Bean。
该 Bean 必须返回一个 java.util.function.Function。
我们使用 Spring 的 @Description 注解来解释此函数的功能。值得注意的是,Spring AI 会将此描述传递给 LLM,以帮助它确定何时调用此特定函数。
该函数接受一个 OwnerRequest 记录,该记录包含现有的 Spring Petclinic Owner 实体类。这表明 Spring AI 如何利用您已在应用中开发的组件,而无需进行完整的重写。
OpenAI 将决定何时使用代表 OwnerRequest 记录的 JSON 对象调用该函数。Spring AI 将自动将此 JSON 转换为 OwnerRequest 对象并执行该函数。返回响应后,Spring AI 会将结果 OwnerResponse 记录(其中包含一个 List<Owner>)转换回 JSON 格式供 OpenAI 处理。当 OpenAI 收到响应后,它将用自然语言为用户生成回复。
该函数调用一个 AIDataProvider @Service Bean,该 Bean 实现了实际的业务逻辑。在我们简单的用例中,该函数仅使用 JPA 查询数据
public OwnersResponse getAllOwners() {
Pageable pageable = PageRequest.of(0, 100);
Page<Owner> ownerPage = ownerRepository.findAll(pageable);
return new OwnersResponse(ownerPage.getContent());
}
Spring Petclinic 现有的遗留代码返回分页数据,以保持响应大小可管理并方便 UI 中的分页视图处理。在我们的用例中,我们预期主人的总数相对较少,并且 OpenAI 应该能够在单个请求中处理此类流量。因此,我们在单个 JPA 请求中返回前 100 个主人。
您可能认为这种方法并非最优,在实际应用中确实如此。如果数据量很大,这种方法效率会很低——系统中的主人很可能超过 100 个。对于这种情况,我们需要实现不同的模式,正如我们将在 listVets 函数中探讨的那样。然而,对于我们的演示用例,我们可以假设系统中包含少于 100 个主人。
让我们结合 SimpleLoggerAdvisor 使用一个真实的例子,观察幕后发生的情况
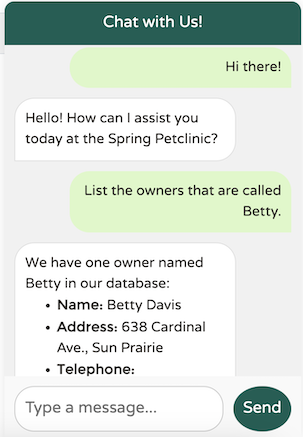
这里发生了什么?让我们查看 SimpleLoggerAdvisor 的日志输出进行调查
request:
AdvisedRequest[chatModel=org.springframework.ai.azure.openai.AzureOpenAiChatModel@18e69455,
userText=
"List the owners that are called Betty.",
systemText=You are a friendly AI assistant designed to help with the management of a veterinarian pet clinic called Spring Petclinic.
Your job...
chatOptions=org.springframework.ai.azure.openai.AzureOpenAiChatOptions@3d6f2674,
media=[],
functionNames=[],
functionCallbacks=[],
messages=[UserMessage{content='"Hi there!"',
properties={messageType=USER},
messageType=USER},
AssistantMessage [messageType=ASSISTANT, toolCalls=[],
textContent=Hello! How can I assist you today at Spring Petclinic?,
metadata={choiceIndex=0, finishReason=stop, id=chatcmpl-A99D20Ql0HbrpxYc0LIkWZZLVIAKv,
messageType=ASSISTANT}]],
userParams={}, systemParams={}, advisors=[org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@1d04fb8f,
org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@2fab47ce], advisorParams={}]
请求包含发送给 LLM 的有趣数据,包括用户文本、历史消息、代表当前聊天会话的 ID、要触发的 advisor 列表以及系统文本。
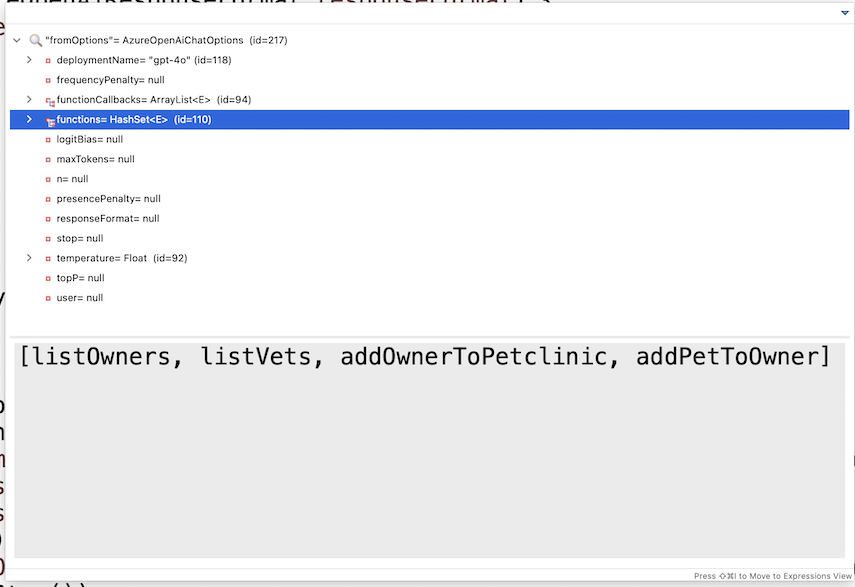
您可能想知道上面的日志请求中的函数在哪里。函数并未明确记录;它们封装在 AzureOpenAiChatOptions 的内容中。在调试模式下检查该对象会显示模型可用的函数列表
OpenAI 将处理请求,确定需要从主人列表中获取数据,并向 Spring AI 返回一个 JSON 回复,请求从 listOwners 函数获取额外信息。然后,Spring AI 将使用 OpenAI 提供的 OwnersRequest 对象调用该函数,并将响应发送回 OpenAI,同时保持会话 ID 以协助无状态连接上的会话连续性。OpenAI 将根据提供的额外数据生成最终响应。让我们查看日志中记录的响应
response: {
"result": {
"metadata": {
"finishReason": "stop",
"contentFilterMetadata": {
"sexual": {
"severity": "safe",
"filtered": false
},
"violence": {
"severity": "safe",
"filtered": false
},
"hate": {
"severity": "safe",
"filtered": false
},
"selfHarm": {
"severity": "safe",
"filtered": false
},
"profanity": null,
"customBlocklists": null,
"error": null,
"protectedMaterialText": null,
"protectedMaterialCode": null
}
},
"output": {
"messageType": "ASSISTANT",
"metadata": {
"choiceIndex": 0,
"finishReason": "stop",
"id": "chatcmpl-A9oKTs6162OTut1rkSKPH1hE2R08Y",
"messageType": "ASSISTANT"
},
"toolCalls": [],
"content": "The owner named Betty in our records is:\n\n- **Betty Davis**\n - **Address:** 638 Cardinal Ave., Sun Prairie\n - **Telephone:** 608-555-1749\n - **Pet:** Basil (Hamster), born on 2012-08-06\n\nIf you need any more details or further assistance, please let me know!"
}
},
...
]
}
我们在 content 部分看到了响应本身。返回的 JSON 大部分由元数据组成——例如内容过滤器、正在使用的模型、响应中的聊天 ID 会话、消耗的 token 数量、响应如何完成等等。
这说明了系统如何端到端地运作:它从您的浏览器开始,到达 Spring 后端,并在 Spring AI 和 LLM 之间进行 B2B 乒乓交互,直到响应被发送回发起初始调用的 JavaScript。
现在,让我们回顾剩下的三个函数。
addPetToOwner 方法尤其有趣,因为它展示了模型的函数调用能力。
当用户想为主人添加宠物时,期望他们输入宠物类型 ID 是不现实的。相反,他们很可能会说宠物是“狗”,而不是简单地提供一个数字 ID,比如“2”。
为了帮助 LLM 确定正确的宠物类型,我利用了 @Description 注解来提供关于我们要求的提示。由于我们的宠物诊所只处理六种宠物类型,这种方法是可行的且有效的
@Bean
@Description("Add a pet with the specified petTypeId, " + "to an owner identified by the ownerId. "
+ "The allowed Pet types IDs are only: " + "1 - cat" + "2 - dog" + "3 - lizard" + "4 - snake" + "5 - bird"
+ "6 - hamster")
public Function<AddPetRequest, AddedPetResponse> addPetToOwner(AIDataProvider petclinicAiProvider) {
return request -> {
return petclinicAiProvider.addPetToOwner(request);
};
}
AddPetRequest 记录包含自由文本形式的宠物类型,反映了用户通常会如何提供,以及完整的 Pet 实体和引用的 ownerId。
record AddPetRequest(Pet pet, String petType, Integer ownerId) {
};
record AddedPetResponse(Owner owner) {
};
这是业务实现:我们通过 ID 检索主人,然后将新宠物添加到他们现有的宠物列表中。
public AddedPetResponse addPetToOwner(AddPetRequest request) {
Owner owner = ownerRepository.findById(request.ownerId());
owner.addPet(request.pet());
this.ownerRepository.save(owner);
return new AddedPetResponse(owner);
}
在为本文调试流程时,我注意到一个有趣的现象:在某些情况下,请求中的 Pet 实体已经预填充了正确的宠物类型 ID 和名称。
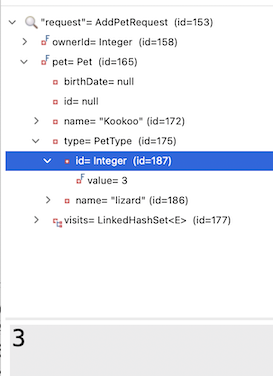
我还注意到在我的业务实现中并没有真正使用 petType 字符串。Spring AI 是否可能仅仅“自己弄清楚”了 PetType 名称到正确 ID 的映射关系?
为了测试这一点,我从我的请求对象中移除了 petType,并简化了 @Description
@Bean
@Description("Add a pet with the specified petTypeId, to an owner identified by the ownerId.")
public Function<AddPetRequest, AddedPetResponse> addPetToOwner(AIDataProvider petclinicAiProvider) {
return request -> {
return petclinicAiProvider.addPetToOwner(request);
};
}
record AddPetRequest(Pet pet, Integer ownerId) {
};
record AddedPetResponse(Owner owner) {
};
我发现在大多数提示中,LLM 竟然能够自己想办法完成映射。最终我还是在 PR 中保留了原始描述,因为我注意到在某些边缘情况下 LLM 确实难以理解这种关联并失败了。
尽管如此,即使对于 80% 的用例来说,这也非常令人印象深刻。这些事情让 Spring AI 和 LLM 几乎感觉像是魔法。Spring AI 和 OpenAI 之间的交互设法理解了 Pet 的 @Entity 中的 PetType 需要将字符串“lizard”映射到其在数据库中对应的 ID 值。这种无缝集成展示了将传统编程与 AI 能力结合的潜力。
// These are the original insert queries in data.sql
INSERT INTO types VALUES (default, 'cat'); //1
INSERT INTO types VALUES (default, 'dog'); //2
INSERT INTO types VALUES (default, 'lizard'); //3
INSERT INTO types VALUES (default, 'snake'); //4
INSERT INTO types VALUES (default, 'bird'); //5
INSERT INTO types VALUES (default, 'hamster'); //6
@Entity
@Table(name = "pets")
public class Pet extends NamedEntity {
private static final long serialVersionUID = 622048308893169889L;
@Column(name = "birth_date")
@DateTimeFormat(pattern = "yyyy-MM-dd")
private LocalDate birthDate;
@ManyToOne
@JoinColumn(name = "type_id")
private PetType type;
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
@JoinColumn(name = "pet_id")
@OrderBy("visit_date ASC")
private Set<Visit> visits = new LinkedHashSet<>();
即使您在请求中打了一些错别字,它也能正常工作。在下面的示例中,LLM 识别出我将“hamster”拼写成了“hamstr”,纠正了请求,并成功地将其与正确的宠物 ID 匹配。
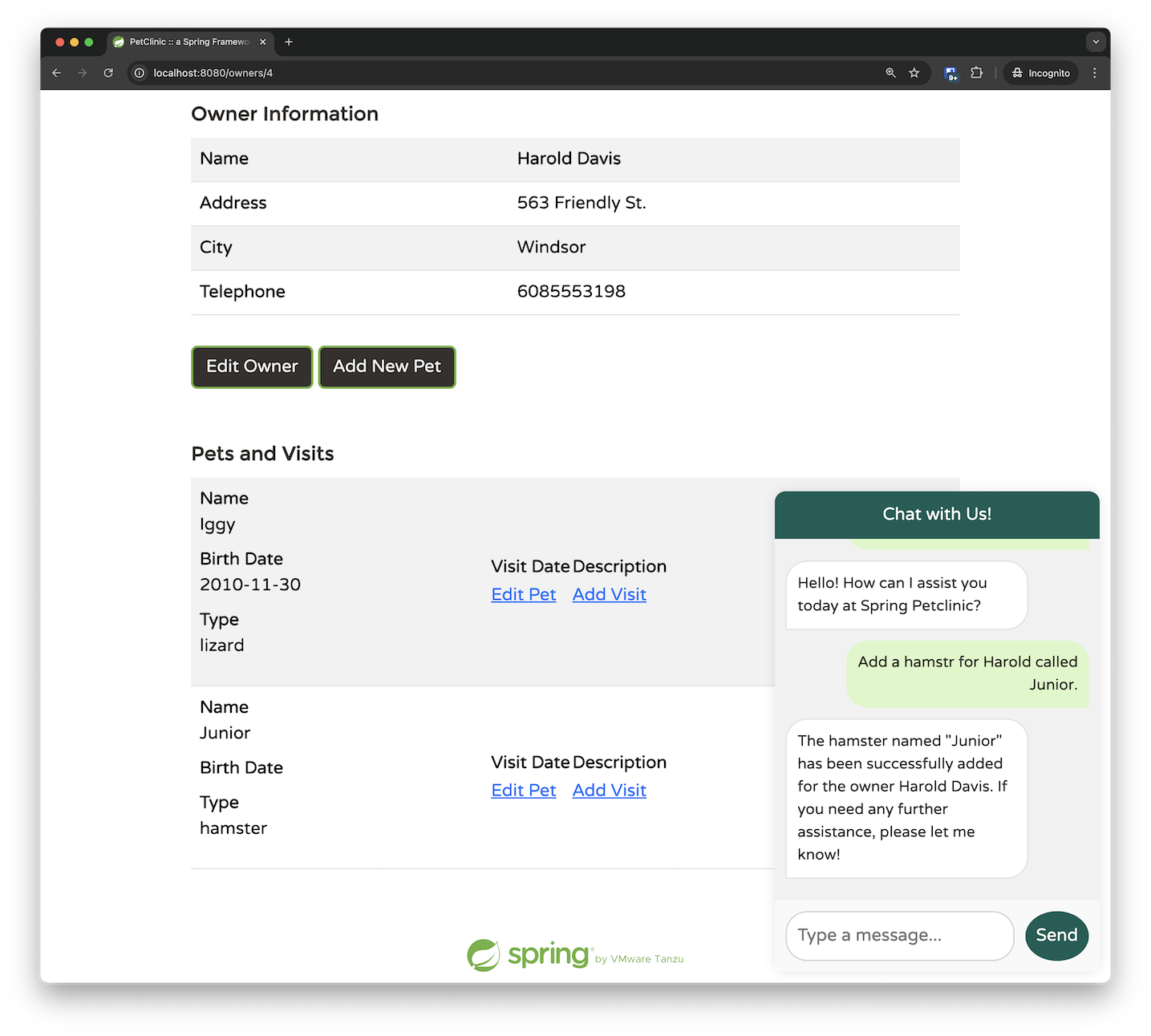
如果您深入研究,会发现事情变得更加令人印象深刻。AddPetRequest 只将 ownerId 作为参数传递;我提供了所有者的名字而不是他们的 ID,而 LLM 设法自行确定了正确的映射。这表明 LLM 在调用 addPetToOwner 函数之前选择了调用 listOwners 函数。通过添加一些断点,我们可以证实这种行为。最初,我们命中了检索所有者的断点。

只有在所有者数据返回并处理后,我们才会调用 addPetToOwner 函数

我的结论是:使用 Spring AI 时,从简单开始。提供您知道必需的基本数据,并使用简短、简洁的 bean 描述。Spring AI 和 LLM 很可能会“搞定”其余部分。只有出现问题时,您才应该开始向系统添加更多提示。
addOwner 函数相对简单。它接受一个所有者并将其添加到系统中。然而,在这个示例中,我们可以看到如何使用我们的聊天助手执行验证和提出后续问题。
@Bean
@Description("Add a new pet owner to the pet clinic. "
+ "The Owner must include first and last name, "
+ "an address and a 10-digit phone number")
public Function<OwnerRequest, OwnerResponse> addOwnerToPetclinic(AIDataProvider petclinicAiDataProvider) {
return request -> {
return petclinicAiDataProvider.addOwnerToPetclinic(request);
};
}
record OwnerRequest(Owner owner) {
};
record OwnerResponse(Owner owner) {
};
业务实现很简单
public OwnerResponse addOwnerToPetclinic(OwnerRequest ownerRequest) {
ownerRepository.save(ownerRequest.owner());
return new OwnerResponse(ownerRequest.owner());
}
在这里,我们指导模型确保 OwnerRequest 中的 Owner 在添加之前满足某些验证条件。具体来说,所有者必须包括名字、姓氏、地址和 10 位电话号码。如果缺少任何这些信息,模型将提示我们提供必要的详细信息,然后才能继续添加所有者。
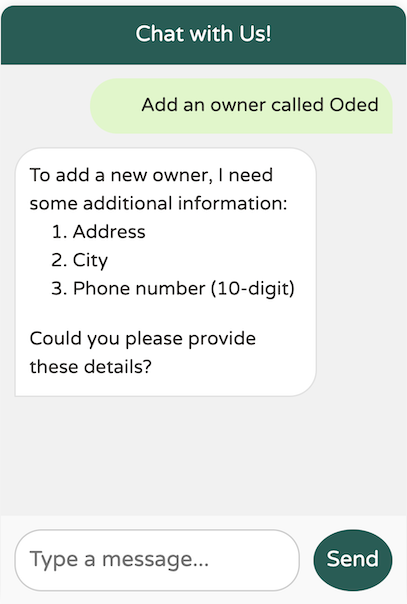
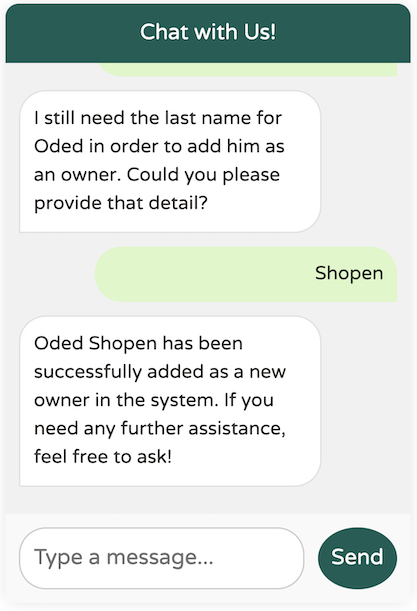
在请求必要的附加数据(例如地址、城市和电话号码)之前,模型没有创建新的所有者。然而,我不记得提供了必需的姓氏。它还能工作吗?

我们发现了模型中的一个边缘情况:即使 `@Description` 指定姓氏是强制性的,模型似乎也没有强制要求。我们如何解决这个问题?提示工程来帮忙!
@Bean
@Description("Add a new pet owner to the pet clinic. "
+ "The Owner must include a first name and a last name as two separate words, "
+ "plus an address and a 10-digit phone number")
public Function<OwnerRequest, OwnerResponse> addOwnerToPetclinic(AIDataProvider petclinicAiDataProvider) {
return request -> {
return petclinicAiDataProvider.addOwnerToPetclinic(request);
};
}
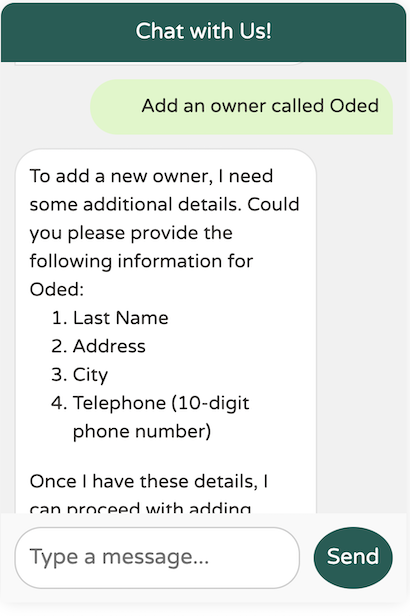
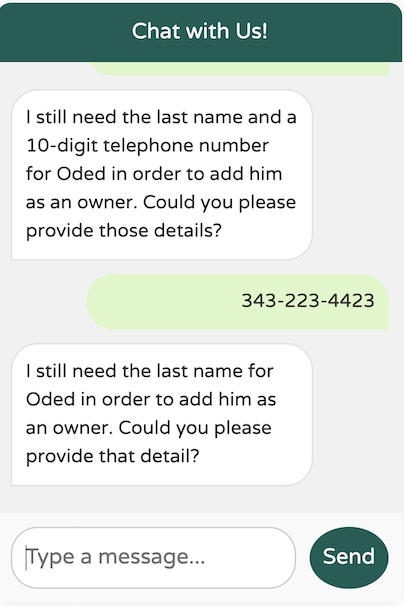
通过在描述中添加提示“as two separate words”,模型更清楚地了解了我们的期望,从而能够正确地强制要求姓氏。
在本文的第一部分,我们探讨了如何利用 Spring AI 处理大型语言模型。我们构建了一个自定义的 ChatClient,使用了函数调用(Function Calling),并针对我们的特定需求改进了提示工程(Prompt Engineering)。
在第二部分,我们将深入探讨检索增强生成(Retrieval-Augmented Generation - RAG)的强大之处,以便将模型与大型的、特定领域的数据集集成,这些数据集对于函数调用(Function Calling)方法来说过于庞大。