
领先一步
VMware 提供培训和认证,助您加速进步。
了解更多我谨代表团队,很高兴地宣布 Spring Cloud Data Flow 1.2 的第一个候选发布版。
注意:开始使用此新版本的一个好方法是遵循参考文档中的 入门指南。
本次发布引入了组合任务!此功能提供了将任务流编排为内聚的“工作单元”的能力。复杂的 ETL 管道可能包括顺序执行、并行执行、条件转换或以上所有方式的组合。组合任务功能提供了 DSL 原语和一个交互式图形界面,可以更轻松地快速构建此类拓扑。您可以从参考指南中了解更多信息。
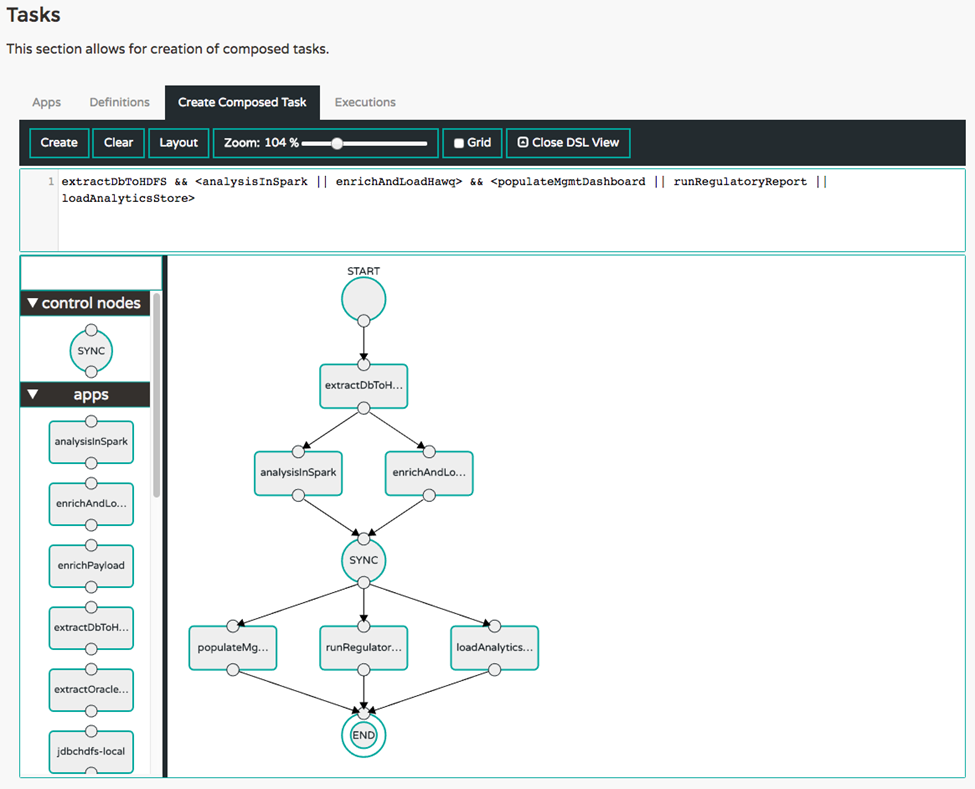
例如,ETL 作业可能包含多个步骤。拓扑中的每个步骤都可以构建为有限的、短期的 Spring Cloud Task 应用程序。借助 Data Flow Task DSL,可以轻松定义将多个任务编排为步骤。
task create simple-etl --definition "extractDbToHDFS && <analysisInSpark || enrichAndLoadHawq> && <populateMgmtDashboard || runRegulatoryReport || loadAnalyticsStore>"
这将首先运行 extractDbToHDFS,然后并行运行 analysisInSpark 和 enrichAndLoadHawq,等待它们都完成后再并行运行剩余的三个任务,并等待它们全部完成后作业结束。此拓扑的图形表示如下所示。
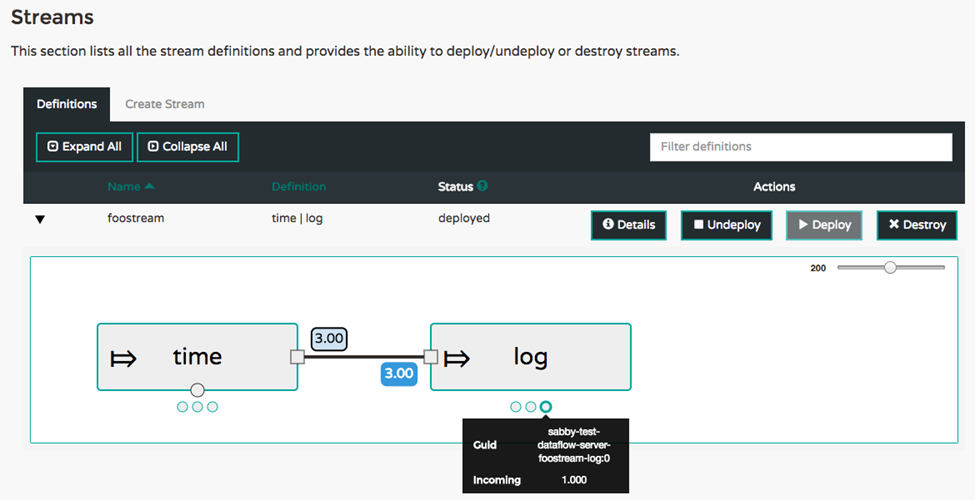
实时指标现已成为已部署流的运行视图的一部分。流中的应用程序会发布其 Spring Boot /metrics 执行器端点中包含的指标。这包括发送和接收消息的速率。一个新服务器,即Spring Cloud Data Flow Metrics Collector,收集这些指标并计算聚合消息速率。Data Flow 服务器会查询 Metrics Collector 以支持在 UI 和 shell 中显示消息速率。有关架构的更多详细信息,请参阅参考指南中的监控已部署应用程序部分。
下图显示了具有三个 time 和 log 应用程序实例的 time | log 流的聚合消息速率。主应用程序框下方的每个点都显示了每个单独应用程序的消息速率以及一个 guid 值,该值可用于标识其正在运行的平台上的应用程序。
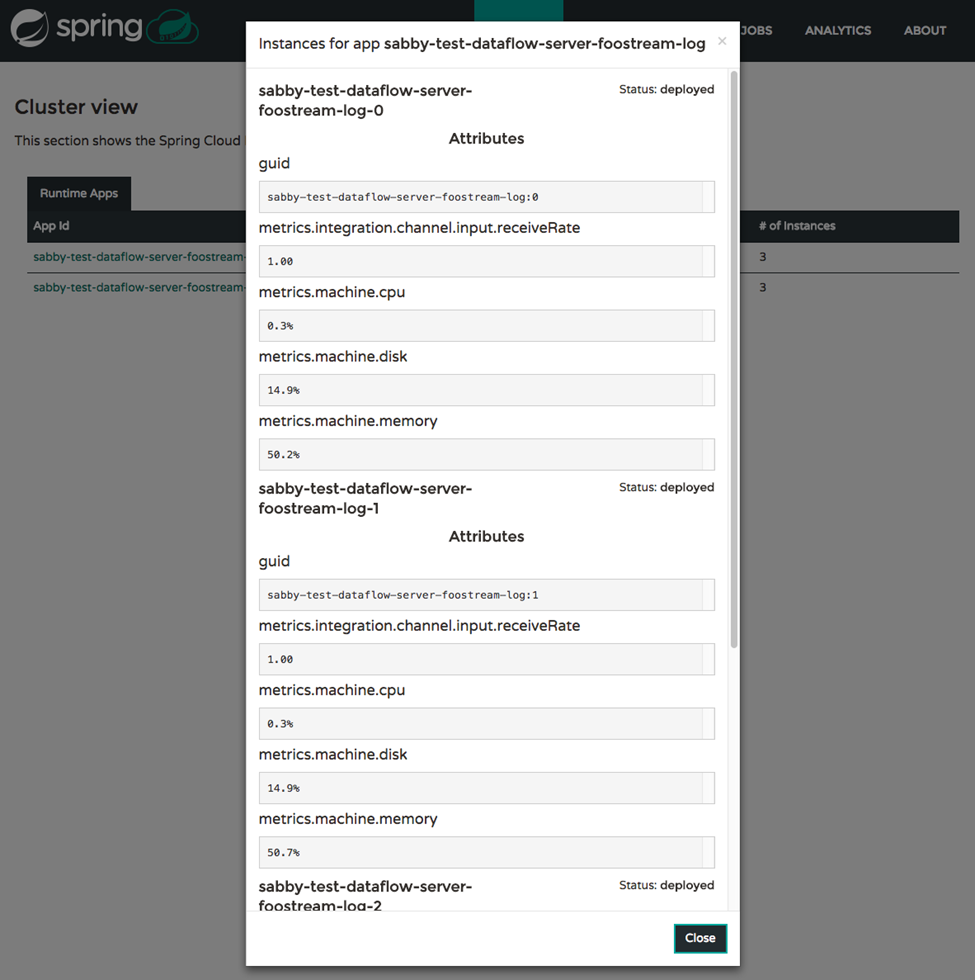
下图中显示的运行时选项卡在显示消息速率和平台暴露的任何其他指标方面也有所改进。对于精通脚本的用户,shell 体验也通过 runtime apps 命令包含这些详细信息。
伴生构件支持 在 1.2 M3 中引入,已得到一些改进。批量注册工作流程现在会主动解析并下载所有开箱即用应用程序的元数据构件。这在使用 Shell 或 UI 查看每个应用程序的受支持属性时非常方便。
此更改将为 REST-API 用户提供额外的选项。用户不再需要通过 BasicAuth 提供 username:password 组合,现在他们可以直接从其 OAuth2 提供程序检索 OAuth2 访问令牌,然后在调用受保护的 Spring Cloud Data Flow 设置的 RESTful 调用时,将访问令牌提供在 HTTP 标头中。
Bacon.RELEASE 现已正式发布。所有开箱即用的流应用程序都建立在 Spring Cloud Stream Chelsea.RELEASE 和 Spring Cloud Dalston.RELEASE 的基础上。对现有应用程序进行了一些增强和错误修复,此发行版本还带来了新的应用程序,如 MongoDB-sink、Aggregator-processor、Header-Enricher-processor 和 PGCopy-sink。
为了方便起见,我们已生成了bit.ly 链接,其中包含最新版本的 docker 和 maven 构件坐标。
App Starters Belmont.RC1 版本现已完成。为了支持 Spring Cloud Data Flow 中的组合任务功能,我们添加了一个名为Composed Task Runner 的新开箱即用应用程序。这是一个任务,它会按照通过 --graph 命令行参数传递的 DSL 指定,以有向图的方式执行其他任务。
Belmont.RC1 基于Spring Cloud Task 1.2 RC1 和 Spring Cloud Dalston.RELEASE 的基础。
为了方便起见,我们已生成了bit.ly 链接,其中包含最新版本的 docker 和 maven 构件坐标。
1.2.0.RELEASE 版本即将发布。我们计划在接下来的 2-3 周内完成。Spring Cloud Data Flow 的运行时实现将在核心版本发布后不久跟进并适应此基础。
您的反馈非常重要。如有任何问题或功能需求,请通过StackOverflow和GitHub联系我们。我们也欢迎贡献!任何有助于改进Spring Cloud Data Flow生态系统的帮助都将不胜感激。