
领先一步
VMware 提供培训和认证,助您加速进步。
了解更多我代表团队,非常高兴地宣布 Spring Cloud Data Flow 1.0 GA 版本发布!
注意
开始使用此新版本的一个好方法是遵循参考文档的“入门”部分。它使用在您的计算机上运行的 Data Flow 服务器,并为每个应用程序部署一个新进程。
Spring Cloud Data Flow (SCDF) 是用于在现代运行时上编排数据微服务的服务。SCDF 允许您描述数据管道,这些管道可以由长期运行的流应用程序或短期运行的任务应用程序组成,然后将这些管道部署到您今天可能已经使用的平台运行时,例如 Cloud Foundry、Apache YARN、Apache Mesos 和 Kubernetes。我们提供了广泛的流和任务应用程序,因此您可以立即开始开发用于数据摄取、实时分析和数据导入/导出等用例的解决方案。
流使用受Unix 管道语法启发的 DSL 定义。例如,从 http 端点摄取数据并写入 Apache Cassandra 数据库的流的 DSL 定义为 http | cassandra。反过来,此 DSL 的每个元素都映射到一个专注于数据处理的 Spring Boot 微服务应用程序,该应用程序使用Spring Cloud Stream 编程模型。此编程模型允许您专注于处理应用程序的输入和输出,而 SCDF 配置这些输出和输入如何映射到消息中间件,这就是应用程序通信的方式。通过 Spring Cloud Stream 中的绑定器抽象支持多个消息代理。目前 RabbitMQ 和 Kafka 可用于生产。Spring Cloud Stream 还支持消费者组和数据分区,并可以在部署流时进行配置。
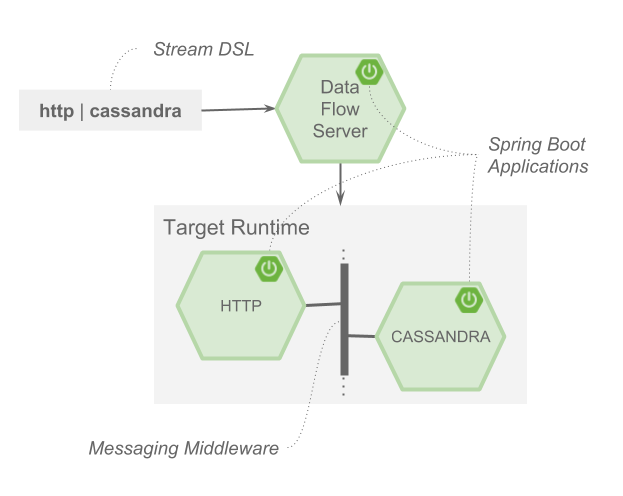
Unix 哲学“编写只做一件事并做好它的程序”、“编写协同工作的程序”和“编写处理文本流的程序,因为那是一个通用接口”与 SCDF 中的微服务架构和 Spring Cloud Stream 绑定器结合在一起,这非常酷。
今天我们还宣布发布
Spring Cloud Data Flow 的Apache YARN Server 1.0 GA
Spring Cloud Data Flow 的Kubernetes Server 1.0 GA
Spring Cloud Data Flow 的Cloud Foundry Server 1.0 M4
对 Apache Mesos 的支持正在开发中。我们也很高兴看到社区为其他运行时做出贡献,例如OpenShift。您可以在我们的参考手册中找到有关 SCDF 架构的更多信息。
此版本中的显着功能有
一种流 DSL,它将数据管道描述为单个应用程序的有向图。
对命名目标的支持,允许您从流定义中的任何“管道”消费事件。这被称为窃听流。您还可以组合来自多个流的输出。
一个部署清单,允许您定义单个应用程序的资源使用(CPU、磁盘、内存)以及应用程序实例计数和如何分区数据。您还可以在部署时传递任意应用程序属性。
支持将应用程序打包为 Spring Boot uber-jar 或 Docker 镜像。
支持使用 Spring Cloud Stream 部署数据微服务,用于处理无界数据量的长期运行的流应用程序,以及使用 Spring Cloud Task 部署处理有限数据集然后终止的应用程序。反过来,这些都建立在 Spring Boot 之上。
一个带有 tab 补全功能的 shell 应用程序,用于创建、部署和监控流和任务。
一个 HTML5 仪表板,允许您创建、部署和监控已部署的流和任务。
Flo for Spring Cloud Data Flow:一个流定义的可视化设计器,它还支持一个可脚本化的转换处理器,接受 Ruby、Groovy、Python 或 Javascript 代码用于运行时计算逻辑。
支持基本的 HTTP 和 OAuth 2.0 认证。
使用 Field Value 和 Aggregate Counters 进行“NoSql”风格的实时分析,服务器上带有 HTTP 端点以访问计数器值。计数器数据由 Redis 支持。
Spring Cloud Stream 应用程序支持 RabbitMQ 和 Kafka 0.8
Spring Boot 应用程序属性白名单为 shell/UI 提供信息,以显示一组首选的引导属性,用于代码完成和应用程序信息。
Spring Cloud Data Flow 已经开发了大约一年,它从之前的项目 Spring XD 演变而来,该项目也有类似的目标,即简化流和批处理应用程序的开发。我们从那次经验中学到了很多,Sabby Anandan 在这篇博客文章中很好地描述了这一点。
一个主要的架构变化是使用可插拔的部署器服务提供商接口替换我们自己的应用程序运行时。虽然 Spring Cloud Data Flow 1.0 GA 中花费的大部分工程时间都花在了这种架构转变上,但我们现在处于一个非常有利的位置,可以继续在此基础上添加更高层次的价值,而不必花费时间开发核心运行时功能。以下是团队集体思考的一些想法
通过将流或任务应用程序的组件视为“普通应用程序”,我们可以利用许多其他 Spring Cloud 项目,例如 Spring Cloud Sleuth 来收集分布式应用程序中的响应时间。
与Spinnaker集成以处理应用程序的持续部署/升级职责,因为 Spinnaker 将“应用程序”作为其基本单位,并且可以使用响应时间等数据来做出自动化决策,以升级到应用程序的新版本。
多语言部署,我们希望部署更多非 Java Spring Boot 应用程序。我们将首先考虑部署 Python 应用程序,因为许多数据科学团队使用 Python 开发需要实时评估的模型。
从 Spring XD 中带回 Task DSL 和 UI Designer。
由于 Spring Cloud Data Flow 与 Spring Cloud Stream 和 Spring Cloud Task 的发布生命周期解耦,因此这些项目发布新功能时,SCDF 可以立即使用它们。Spring Cloud Stream 中值得一提的一些激动人心的功能包括对 Project Reactor 和 Kafka Streams API 的支持,以及对 Kafka 0.9、Google Cloud Pub/Sub、Azure Event Hubs 和 JMS 的绑定支持。对于 Spring Cloud Task,计划支持 Cloud Foundry 上的最新任务功能。有关详细信息,请查看这两个项目的路线图
有关功能、错误修复和改进的完整列表,请参阅已关闭的 1.0 RELEASE GitHub 问题。
我们欢迎反馈和贡献!如果您有任何问题、评论或建议,请通过 GitHub Issues、StackOverflow 或在 Twitter 上使用 #SpringCloudDataFlow 标签告诉我们。
SpringOne Platform 即将到来。除了涵盖 Spring Cloud Data Flow 及相关项目的多个会议外,还将有一个为期两天的培训课程。整个 Spring Cloud Data Flow 团队都将在那里,期待在那里见到您!