
领先一步
VMware 提供培训和认证,助您加速进步。
了解更多作为一名探索生成式 AI 世界的 Java 开发者,你可能已经了解一些声称能让 AI 集成变得简单的框架。我相信 Spring AI 脱颖而出,成为自然而然的选择,特别是对于已经在 Spring 生态系统中工作的开发者而言。Spring AI 建立在与 Spring Boot 和 Spring Data 相同的基础之上,它使 为你的应用程序添加 AI 功能 变得无缝且直观,而无需你学习一套全新的范式。
Spring AI 最显著的优势之一是它与 Spring 生态系统的深度集成。如果你已经熟悉 Spring Boot 应用程序的开发,Spring AI 将会让你觉得它只是你已有知识的扩展。驱动 Spring Data 的相同概念,例如依赖注入、注解和清晰的抽象,也同样适用于 Spring AI。这种一致性意味着你可以直接投入到 AI 开发中,而无需重新思考如何开发你的应用程序。
与某些工具不同,Spring AI 不需要复杂的配置或工作流设置即可开始使用。它与你现有的代码库完美契合,允许你重用现有的 Bean、服务和存储库。Spring AI 不是简单地附加一个外部 AI 平台,而是直接与你已构建的业务逻辑和企业服务集成,充分利用你在 Spring 生态系统中的投入。
Spring AI 专注于简化企业级应用的 AI 操作。它非常适合需要向其业务应用添加简单 AI 功能(如文本生成、嵌入和函数调用)的开发人员。Spring AI 的美妙之处在于其简洁性:你可以在不承担管理复杂工作流或协调多步骤流程的开销的情况下,获得生成式 AI 的强大功能。对于大多数企业用例来说,AI 的作用是增强功能而不是驱动整个工作流,Spring AI 正好提供了所需的一切。
Spring AI 的另一个关键优势是其与向量存储的集成。无论你使用带有 pgVector 的 Postgres、Redis,还是任何其他支持向量的数据库,Spring AI 都扩展了 Spring 众所周知的处理向量嵌入和其他 AI 驱动的数据存储需求的能力。
Spring AI 让在不同向量存储实现之间切换变得异常容易。使用 Spring 开发者熟悉的相同依赖注入模式,你只需更改 Spring Boot Starter 依赖项即可替换一个向量存储,而无需触及核心应用程序逻辑。这种灵活性对于构建需要可扩展、高效存储和检索嵌入或其他 AI 生成数据的 AI 增强应用程序的开发者来说是一个显著优势。
将源数据嵌入向量存储是一项强大的功能,但在嵌入之前,如何处理不同的数据结构呢?借助 Spring AI,你可以访问即用型文档阅读器,它允许你处理各种格式,包括 PDF、Markdown、Microsoft Word 和 PowerPoint 文档、HTML 等。文档阅读器功能确保你可以处理各种源格式。如果不支持特定格式,创建自己的实现也很简单。
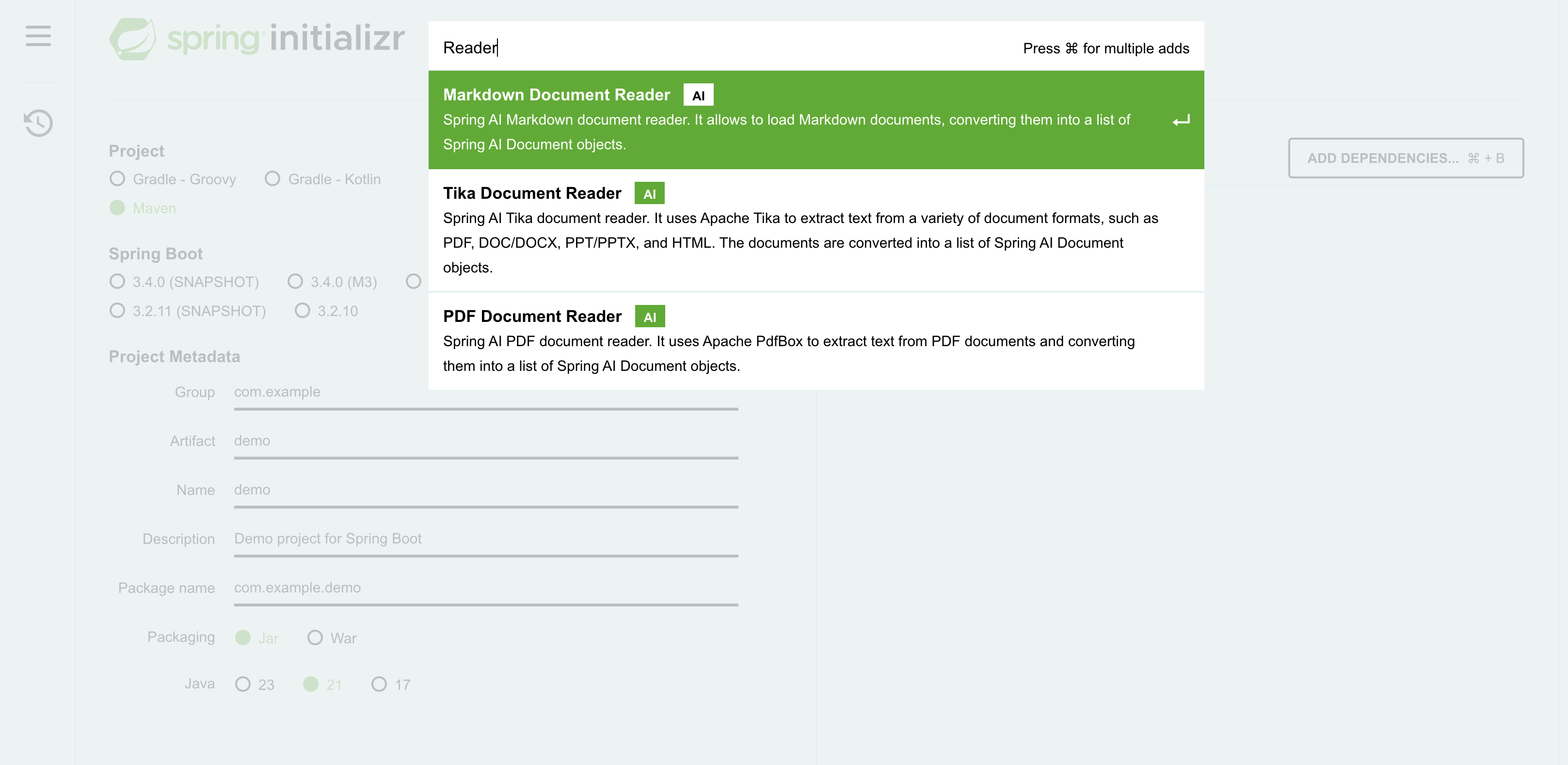
Spring AI 的突出特点之一是它支持嵌入上的元数据过滤,这与底层向量存储实现无关。在典型的 RAG(检索增强生成)应用程序中,对向量存储执行相似性搜索,计算查询与数据集中每个数据点之间的距离度量(例如,余弦相似性)。虽然这种方法对于较小的数据集可能 manageable,但随着数据量的增长,它变得越来越具有挑战性。为了解决这个问题,向量存储实现了各种性能增强算法,例如近似最近邻 (ANN)、局部敏感哈希 (LSH) 或分层可导航小世界 (HNSW)。
为了进一步解决这个挑战,一个额外的有效策略是在执行相似性搜索之前减少要查询的数据量。例如,如果你只对位于波士顿的客户感兴趣,则可以将数据集过滤到只包含居住在那里的客户。这种减少过程称为元数据过滤。
许多向量存储提供了自己的元数据过滤实现,每种实现都有其优点和局限性。然而,Spring AI 提供了一个与供应商无关的解决方案,弥合了各种向量存储之间的差距。这种能力在企业应用程序中特别有价值,因为仅凭语义可能不足够,并且某些个人身份信息 (PII) 数据必须从相似性搜索中排除。通过利用元数据过滤,相似性搜索可以仅在文档的相关子集上执行,而不是扫描整个数据集。
这是一个简单的示例,更多详细信息请参见Spring AI 参考文档
public void example() {
// Assume we have a large dataset of customers.
// Embedding the data is computationally expensive
// but it is typically a one-time / ETL process
List<Document> allMyCustomers = new ArrayList<>();
allMyCustomers.add(new Document("""
{
"customerId": 12345,
"name": "John Doe",
"email": "[email protected]",
"phone": "+1234567890",
"address": "123 Main St, Boston, MA"
}
""", Map.of("city", "Boston"))); // Metadata filter!
// Add more customers...
allMyCustomers.add(...);
// Add all embedded documents and their
// associated metadata to the vector store
vectorStore.add(allMyCustomers);
// Prepare a search query, for example:
// "Which customers are named John?"
SearchRequest searchRequest =
SearchRequest.query("Which customers are named John?");
// This similarity search is computationally intensive
List<Document> results = vectorStore.similaritySearch(
searchRequest.withTopK(5)
.withSimilarityThresholdAll());
// Instead, we'll first filter by city to reduce the dataset size,
// then perform the similarity search on the filtered results
results = vectorStore.similaritySearch(
searchRequest.withTopK(5)
.withSimilarityThresholdAll()
.withFilterExpression("city == 'Boston'"));
}
Spring AI 的突出特点之一是其函数调用能力,它通过解决 AI 交互的最大挑战——与你自己的 API 集成——从而简化了企业应用中的 AI 交互!
我最近读到 Jonathan Schneider 的一篇 LinkedIn 帖子,引起了我的注意。他写道,函数调用对于检索增强生成 (RAG) 来说,就像 IoC 对于 Java 开发一样。IoC 允许开发人员专注于业务逻辑,而 Spring 负责对象创建和依赖项注入。以类似的方式,Spring AI 中的函数调用允许开发人员专注于其函数的功能,而大型语言模型 (LLM) 则负责幕后复杂的交互。
你用自然语言描述你的函数功能,Spring AI 确保 LLM 在需要时理解并执行它。这大大减少了与 AI 模型交互通常所需的样板代码量,让你能够专注于构建功能,而不是管理 AI 过程的复杂性。
以下是Spring AI 参考文档中的一个简单示例
@Configuration
static class Config {
@Bean
@Description("Get the current weather in location")
public Function<WeatherService.Request, WeatherService.Response> currentWeather() {
return new MockWeatherService();
}
}
public class WeatherService implements Function<Request, Response> {
public enum Unit { C, F }
public record Request(String location, Unit unit) {}
public record Response(double temp, Unit unit) {}
public Response apply(Request request) {
// Logic goes here!
}
}
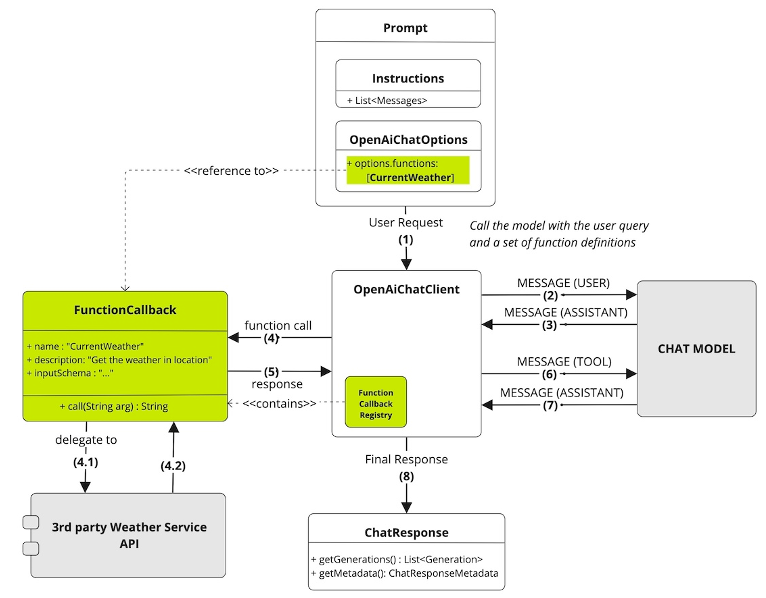
目前没有 AI 模型能够为特定位置提供实时天气数据。因此,LLM 可能会回答它不知道答案——或者更糟的是,它可能会返回一个幻觉响应。
然而,通过注册如上所示的函数,Spring AI 允许 LLM 从 `@Description` 注解推断该函数可以提供实时天气数据。然后,LLM 可以根据用户的输入,以正确的格式构建 WeatherService.Request 的请求。例如,如果用户询问“波士顿天气如何?”,LLM 将自动使用位置和单位填充 `Request` 对象,要求 Spring AI 调用该函数,从 `WeatherService` 检索实际天气数据,然后根据该数据为用户格式化一个易于阅读的响应。
以下是调用流程的分步说明
向量存储通过将你的数据嵌入到 LLM 可以理解的格式中来预处理数据,而函数调用则使 LLM 能够实时与你现有的事务性 API 交互,从而根据需要生成有意义的响应。
Spring AI 引入了 Advisors,这是一种在 AI 应用程序中处理横切关注点的强大机制。如果你熟悉面向切面编程 (AOP) 拦截器或Spring MVC 拦截器,这个概念是相似的。然而,考虑到并非所有开发人员都熟悉这些术语,Spring AI 团队选择使用“Advisor”来强调其目的——增强请求/响应提示流——而不是其操作的技术细节,这涉及拦截请求/响应和应用过滤器。Advisors 简化了日志记录、消息转换和聊天内存管理等任务的管理,同时保持你的应用程序代码整洁。
通过卸载这些例行任务,Advisors 确保你的应用程序保持专注于业务逻辑,而基本的 AI 相关操作在后台无缝运行。这种方法保持了代码库的清晰性,同时有效地解决了必要的运营问题。
以下是一个简单的示例
this.chatClient = builder
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
new SimpleLoggerAdvisor())
.build();
此聊天客户端集成了两个 Advisor:一个内存 Advisor,用于将以前的用户提示附加到当前消息以提供上下文和连续性;一个日志记录 Advisor,用于捕获发送到 LLM 和从 LLM 收到的请求和响应,并将其输出到应用程序的日志中,以实现有效的故障排除。
在使用生成式 AI 模型时经常出现的一个挑战是,每个模型都有其自身的怪癖。例如,要求大型语言模型提供结构化响应(例如 JSON)并不像看起来那么简单。LLM 经过训练可以生成对话文本,它们通常喜欢以更像人类的方式“聊天”。这可能导致不可预测或过于冗长的输出,这在你期望机器可读格式时并不理想。
Spring AI 为你抽象了这些细微差别。它通过根据所使用的特定 LLM 附加适当的用户提示或指令来自动处理这些变化。因此,无论你使用的是 OpenAI 的 GPT4-o、Anthropic 的 Claude 还是不同的 LLM,Spring AI 都能确保你收到所需结构的响应。此功能消除了开发人员试错提示工程的需要,让你能够专注于利用 AI,而不是与它的怪癖作斗争。
这是 Spring AI 的 `BeanOutputConverter` 实现的一个示例,旨在从 LLM 中检索 JSON 格式的响应,该响应遵循给定数据类的模式。请注意,要达到所需结果,对 LLM 的提示需要多么详细和具体
@Override
public String getFormat() {
String template = """
Your response should be in JSON format.
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.
Do not include markdown code blocks in your response.
Remove the ```json markdown from the output.
Here is the JSON Schema instance your output must adhere to:
```%s```
""";
return String.format(template, this.jsonSchema);
}
Spring AI 完成了繁重的工作,所以你无需亲自去做。
可观测性在任何企业应用程序中都至关重要,而用生成式 AI 增强的应用程序也不例外。Spring AI 提供内置可观测性功能,可无缝监控 AI 服务的健康状况和性能。这包括全面的指标、跟踪和日志记录,为你的生成式 AI 应用程序提供端到端的可视性。这不仅适用于聊天模型,还适用于整个堆栈,包括嵌入模型和向量数据库。这种能力再次突出了 Spring 这种集成解决方案的强大之处,因为可观测性功能由Micrometer启用,就像其他 Spring 项目一样
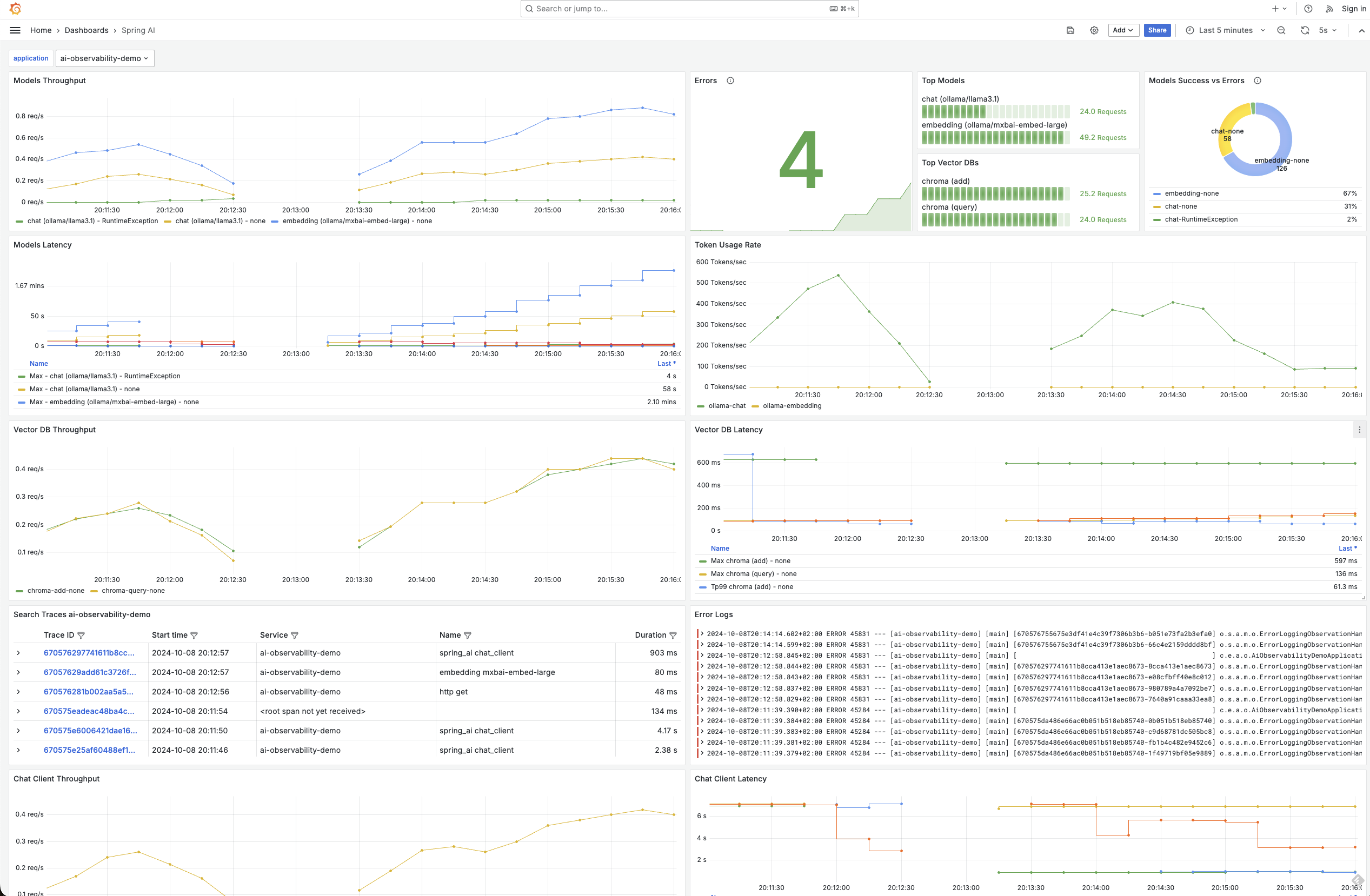
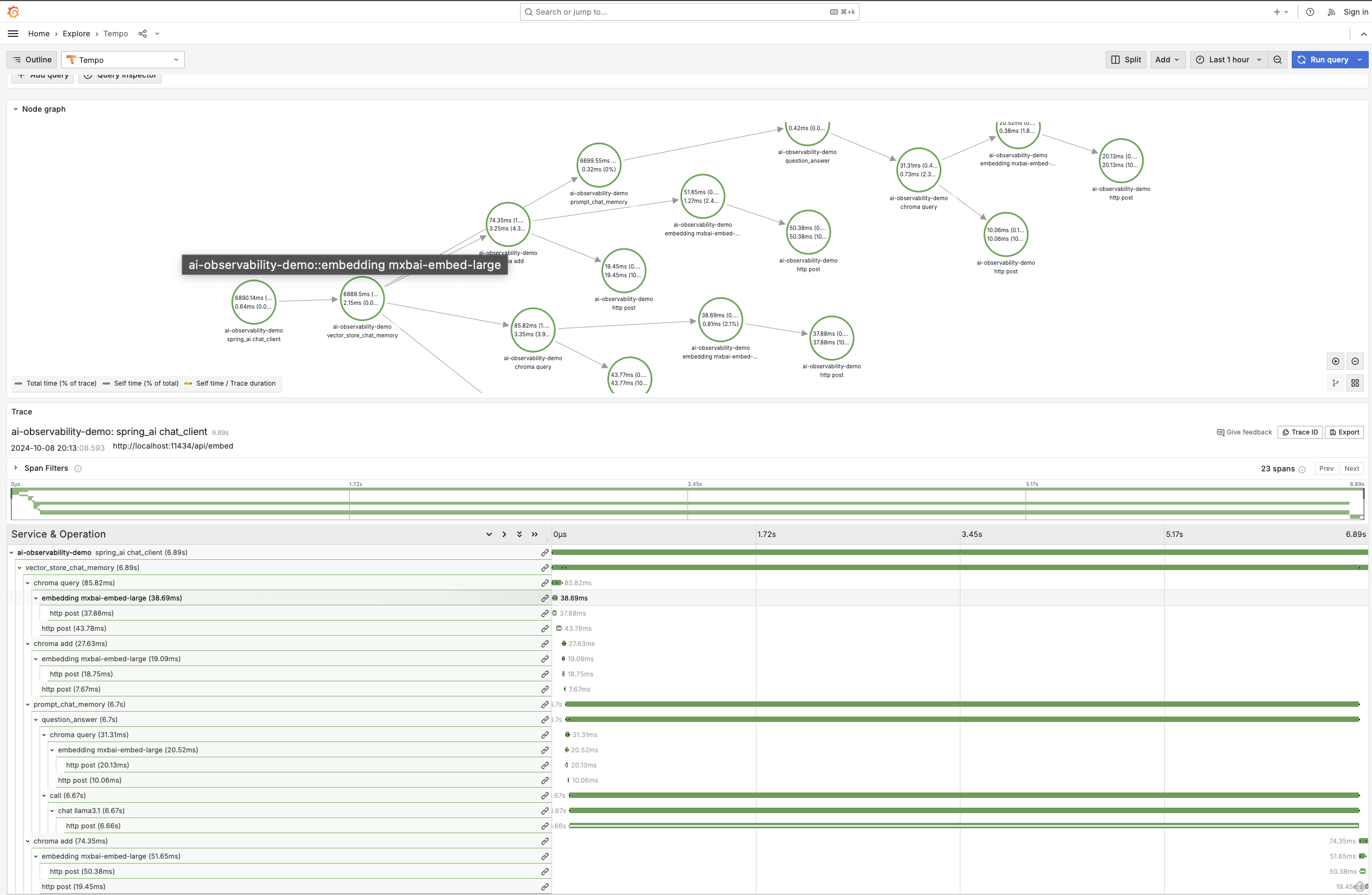
通过 Spring AI,你可以深入了解关键指标,例如令牌使用率,这对于管理与根据处理的令牌数量收费的模型进行交互时的成本至关重要。此外,你还可以监控向量存储延迟、错误率,甚至跟踪请求如何流经你的 AI 增强服务。这种级别的可观测性确保你可以快速识别性能瓶颈或潜在问题,然后在它们影响你的应用程序之前,就像你习惯于处理其他基于 Spring 的服务一样。
使用 Spring AI 的另一个显著优势是,你可以轻松地在不同的 LLM 提供商之间进行 A/B 测试。为了在成本和响应质量之间取得最佳平衡,能够比较多个模型是无价的。
借助 Spring AI,你只需替换 Spring Boot Starter 依赖项并更改属性文件中的几行代码,即可轻松地在各种 LLM 之间切换。这种直接的方法使你能够评估不同模型的性能,而无需进行大量的重新配置或编码开销。无论你是在评估准确性、响应时间还是成本效率,Spring AI 都提供了工具来无缝地促进这些比较。
通过将 A/B 测试直接集成到你的工作流中,你可以就哪个 LLM 提供商最适合你的应用程序需求做出数据驱动的决策。此功能不仅增强了你的 AI 实现的整体有效性,还允许随着生成式 AI 领域中新模型和功能的出现进行持续优化。
Spring AI 专门旨在为 Java 开发人员提供一种无缝高效的方式,将 AI 集成到其应用程序中。这不仅仅是添加 AI 功能,更是以一种自然地融入现有系统的方式进行。将生成式 AI 应用于应用程序主要是一个集成挑战,而这正是 Spring 框架的优势所在。Spring AI 是 Spring 生态系统的自然延伸,旨在轻松处理企业应用程序集成的复杂性。
如果你的目标是使用生成模型、函数调用和向量嵌入来增强企业应用程序,Spring AI 是理想的选择。它与 Spring 生态系统的深度集成,以及对广泛的大型语言模型和向量存储的访问,使其在 AI 开发中既强大又简单。它非常适合将 AI 与现有业务逻辑相结合,消除了管理多步工作流或链式模型的复杂性。
总而言之,Spring AI 的一些突出优势是
无缝集成:轻松将 AI 功能嵌入现有 Spring 应用程序中。
为 RAG 而生:简化数据嵌入和运行相似性搜索的过程,同时支持强大的元数据过滤器。
函数调用:实现与事务性 API 的实时交互。
Advisors: 使用内置的 Advisor 处理横切关注点,或在需要时编写自己的 Advisor。
供应商无关:利用各种向量存储和 LLM 提供商,而不会被锁定在特定解决方案中,为你的数据和模型管理提供灵活性。
A/B 测试:轻松进行 A/B 测试以优化 AI 性能。
内置可观测性:访问监控、日志记录和跟踪功能,以提高透明度。
通过选择 Spring AI,你的企业应用程序将获得先进的 AI 功能,从而推动创新并增强用户体验。