
领先一步
VMware 提供培训和认证,助您快速进步。
了解更多我们很高兴地宣布 Spring AI 的 1.0.0 M3 版本发布。
此版本在多个领域带来了显著的增强和新功能。
此版本对可观测性堆栈进行了许多改进,特别是针对聊天模型的流式响应。非常感谢 Thomas Vitale 和 Dariusz Jedrzejczyk 在此领域的帮助!
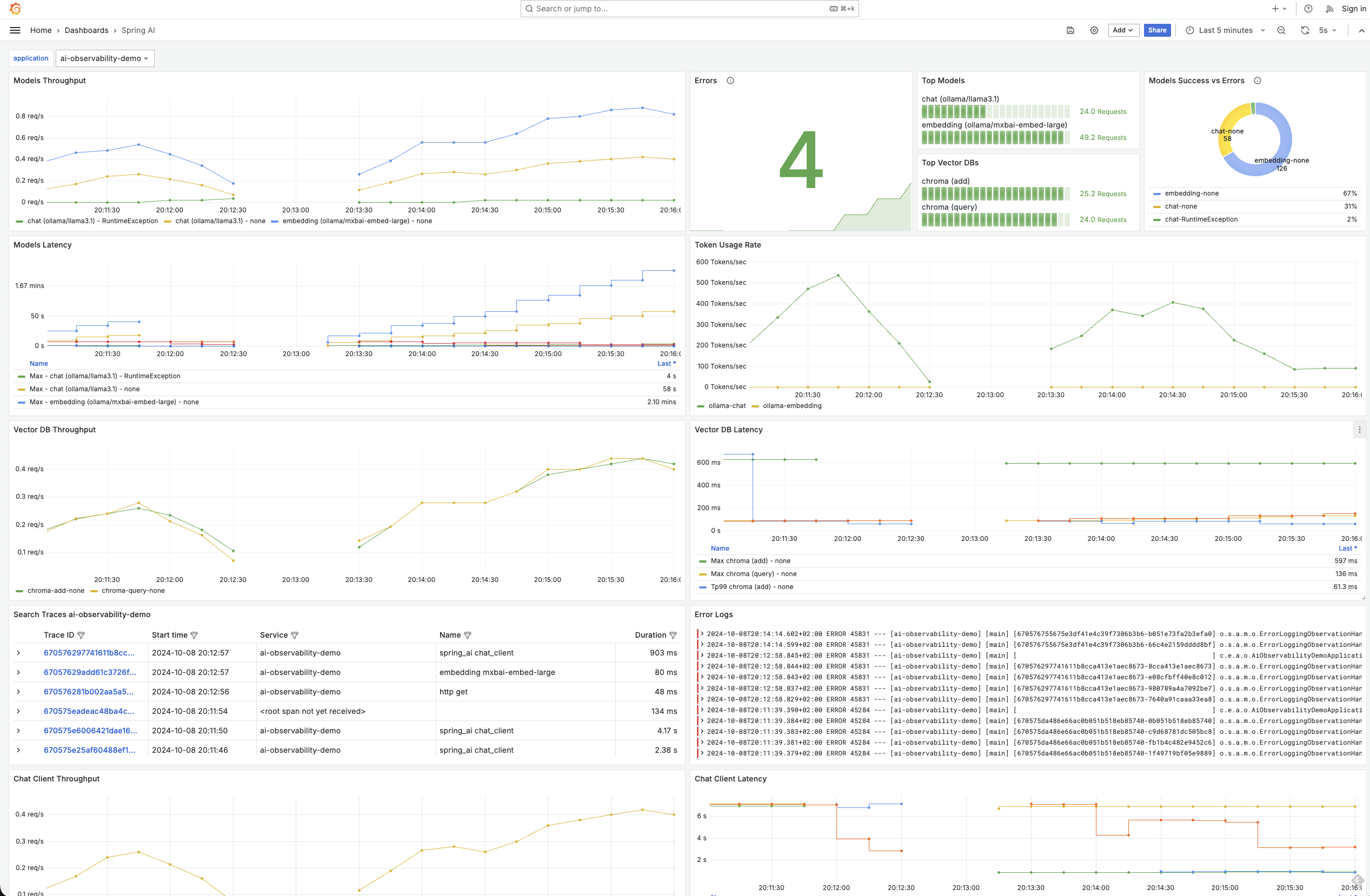
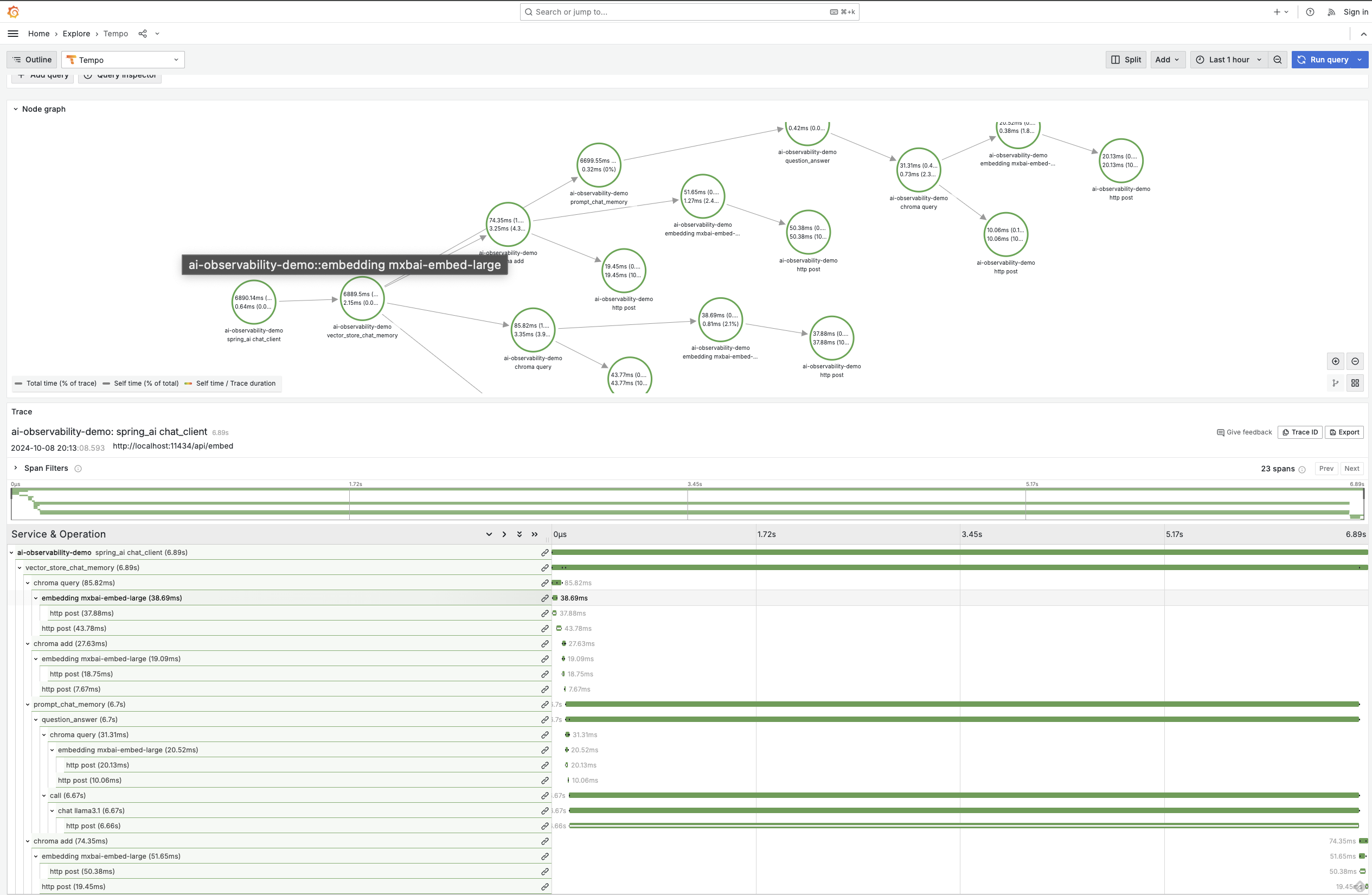
可观测性涵盖了 ChatClient、ChatModel、嵌入模型和向量存储,使您能够精细地查看与 AI 基础设施的所有接触点。
在 M2 版本中,我们引入了对 OpenAI、Ollama、Mistral 和 Anthropic 模型的可观测性支持。现在,我们已将其扩展到包括对以下模型的支持:
感谢 Geng Rong 为中文模型实现可观测性。
您可以在可观测性参考文档中找到有关可用指标和跟踪的更详细信息。这里有一些图表展示了可能实现的效果。
Spring AI Advisors 是用于拦截和潜在修改 AI 应用程序中聊天完成请求和响应流程的组件。Advisors 还可以选择通过不调用链中的下一个 Advisor 来阻止请求。
这个系统中的关键角色是 AroundAdvisor,它允许开发人员在此类交互中动态地转换或利用信息。
使用 Advisors 的主要优势包括
我们重新审视了 Advisor API 模型,并进行了许多设计更改,提高了其应用于流式请求和响应的能力。您还可以使用 Spring 的 Ordered 接口显式定义 Advisor 的顺序。
根据您使用的 API 区域,可能存在破坏性更改,请参阅文档了解更多详细信息。
around advisor 的流程如下所示。

您可以阅读 Christian Tzolov 的近期博客文章 使用 Spring AI Advisors 加速您的 AI 应用程序,了解更多详细信息。
Spring AI 现在支持通过包含键值对的 ToolContext 类向函数回调传递额外的上下文信息。此功能允许您提供可在函数执行中使用的额外数据。
在此示例中,我们传递了 sessionId,以便上下文感知到该值。
String content = chatClient.prompt("What's the weather like in San Francisco, Tokyo, and Paris?")
.functions("weatherFunctionWithContext")
.toolContext(Map.of("sessionId", "123"))
.call()
.content();
另请注意,您可以在 prompt 方法中传递用户文本,作为使用 user 方法的替代方案。
ToolContext 可通过使用 java.util.BiFunction 获取。这是 bean 定义:
@Bean
@Description("Get the weather in location")
public BiFunction<WeatherService.Request, ToolContext, WeatherService.Response> weatherFunctionWithContext() {
return (request, toolContext) -> {
String sessionId = (String) toolContext.getContext().get("sessionId");
// use session id as appropriate...
System.out.println(sessionId);
return new WeatherService().apply(request);
};
}
如果您更喜欢自己处理函数调用对话,可以设置 proxyToolCalls 选项。
PortableFunctionCallingOptions functionOptions = FunctionCallingOptions.builder()
.withFunction("weatherFunction")
.withProxyToolCalls(true)
.build();
通过 ChatModel 或 ChatClient 调用模型并传递这些选项,将返回一个 ChatResponse,其中包含 AI 模型函数调用对话开始时发送的第一个消息。
在事实评估领域有一些显著的创新,出现了一个名为 LLM-AggreFact 的新排行榜。目前在基准测试中领先的模型是由 Bespoke Labs 开发的“bespoke-minicheck”。这个模型引人注目的一部分原因是,与 GPT4o 等所谓的“旗舰”模型相比,它更小巧且运行成本更低。您可以在论文“MiniCheck: Efficient Fact-Checking of LLMs of Grounding Documents”中阅读更多关于该模型背后的研究。
Spring AI FactCheckingEvaluator 基于这项工作,可以与部署在 Ollama 上的 Bespoke-minicheck 模型一起使用。请参阅文档了解更多信息。感谢 Eddú Meléndez 在此领域的工作。
以前,嵌入文档列表需要逐项进行调用,性能不高。Spring AI 现在支持将多个文档批量处理,以便在一次模型调用中计算多个嵌入。由于嵌入模型有 token 限制,文档会被分组,以确保每个批次不超过嵌入模型的 token 限制。
新的类 TokenCountingBatchingStrategy 考虑了 token 大小,并分配了 10% 的保留缓冲区,因为 token 估算不是精确的科学。您可以自定义实现 BatchingStrategy 接口。
此外,基于 JDBC 的嵌入模型现在可以更容易地自定义执行批量插入时使用的批次大小。
感谢 Soby Chacko 在此领域的工作以及作为 Spring AI 团队新成员的其他贡献。
Azure AI
Vertex AI
广泛的贡献者进行了大量的重构、bug 修复和文档增强。如果您的 PR 尚未处理,请耐心等待,我们会处理的。感谢: