
先行一步
VMware 提供培训和认证,为你的进步加速。
了解更多注:代码位于我的 Github 账户:github.com/joshlong/bootiful-spring-boot-2024-blog。
嗨,各位 Spring 粉丝!我是Josh Long,在 Spring 团队工作。很高兴今年能在微软的 JDConf 大会上发表主题演讲和进行分享。我是 Kotlin GDE 和 Java Champion,并且我认为现在是成为 Java 和 Spring Boot 开发人员的最佳时机。我说这话时充分了解我们今天所处的时代。自 Spring Framework 最早发布以来已经超过 21 年,自 Spring Boot 最早发布以来也已超过 11 年。今年是 Spring Framework 诞生 20 周年和 Spring Boot 诞生 10 周年。所以,当我说现在是成为 Java 和 Spring 开发人员的最佳时机时,请记住我已经在其中度过了大半个十年。我热爱 Java 和 JVM,热爱 Spring,这一切都非常棒。
但这确实是最好的时代。从未如此接近。所以,像往常一样,让我们通过访问我在互联网上仅次于生产环境的第二喜欢的地方,start.spring.io,来开发一个新应用,你就会明白我的意思了。点击 Add Dependencies,然后选择 Web, Spring Data JDBC, OpenAI, GraalVM Native Support, Docker Compose, Postgres, 和 Devtools。
给它起一个 artifact 名称。我把我的服务叫做……“service”。我起名字很厉害。这是遗传我爸的。我爸起名字也厉害。我小时候,我们有一只小小的白狗,我爸给它起名叫小白狗。它在我们家养了好几年。但大概十年后,它不见了。我到现在也不知道它到底怎么了。也许它找了份工作吧,我不知道。但后来奇迹般地,另一只小白狗出现在我们家纱门上敲门。所以我们收养了它,我爸给它起名叫也。或者二。我不知道。总之,起名字厉害得很。话说回来,我妈总告诉我,我很幸运是她给我起的名……呃,这可能确实是真的。
总之,选择 Java 21。这部分是关键。如果你不使用 Java 21,你就不能使用 Java 21。所以,你需要 Java 21。但我们还将使用 GraalVM 的原生镜像(native image)能力。
还没安装 Java 21?下载它!使用超棒的 SDKMAN 工具:sdk install java 21-graalce。然后把它设为默认版本:sdk default java 21-graalce。打开新的 shell。下载 .zip 文件。
Java 21 太棒了。它比 Java 8 好得多。它在技术上全面领先。它更快、更健壮、语法更丰富。它在道德上也更优越。当你孩子看到你在生产环境中使用 Java 8 时,你可不想看到他们眼中那种羞愧和耻辱的眼神。别这么做。成为你想在世界上看到的变化。使用 Java 21。
你会得到一个 zip 文件。解压它并在你的 IDE 中打开。
我使用的是 IntelliJ IDEA,它安装了一个命令行工具叫做 idea。
cd service
idea build.gradle
# idea pom.xml if you're using Apache Maven
如果你使用 Visual Studio Code,请务必在 Visual Studio Code Marketplace 上安装 Spring Boot Extension Pack。
这个新应用将与数据库交互;它是一个数据中心的应用。在 Spring Initializr 上,我们添加了对 PostgreSQL 的支持,但现在我们需要连接到它。我们最不希望看到的是一个长长的 README.md,里面有个章节叫做《开发的一百个简单步骤》。我们想要那种 `git clone` & Run 的生活!
为此,Spring Initializr 生成了一个 Docker Compose compose.yml 文件,其中包含了对超赞的 SQL 数据库 Postgres 的定义。
Docker Compose 文件,compose.yaml
services:
postgres:
image: 'postgres:latest'
environment:
- 'POSTGRES_DB=mydatabase'
- 'POSTGRES_PASSWORD=secret'
- 'POSTGRES_USER=myuser'
ports:
- '5432'
更棒的是,Spring Boot 配置为在应用启动时自动运行 Docker Compose (docker compose up) 配置。无需配置连接详情,比如 spring.datasource.url 和 spring.datasource.password 等等。这一切都通过 Spring Boot 令人惊叹的自动配置完成。太赞了!而且,为了不留下烂摊子,Spring Boot 在应用关闭时也会关闭 Docker 容器。
我们希望尽可能快地推进。为此,我们在 Spring Initializr 上选择了 DevTools。它能让我们快速行动。这里的核心理念是重启 Java 相当慢。然而,重启 Spring 真的很快。那么,如果我们有一个进程监控我们的项目文件夹,它可以注意到新编译的 .class 文件,将它们加载到类加载器中,然后创建一个新的 Spring ApplicationContext,丢弃旧的,并给我们一种实时重载的错觉,会怎么样?这正是 Spring DevTools 所做的事情。在开发期间运行它,你会看到你的重启时间大幅缩短!
这之所以有效,是因为 Spring 启动超快……除了,当你在每次重启时都启动一个 PostgreSQL 数据库的时候。我喜欢 PostgreSQL,但呃,是的,它不是用来在你每次调整方法名、修改 HTTP 端点路径或微调一些 CSS 时不断重启的。所以,让我们配置 Spring Boot,让它只启动 Docker Compose 文件一次,然后让它一直运行,而不是每次都重启。
将属性添加到 application.properties
spring.docker.compose.lifecycle-management=start_only
我们将从一个简单的 record 开始。
package com.example.service;
import org.springframework.data.annotation.Id;
// look mom, no Lombok!
record Customer(@Id Integer id, String name) {
}
我爱 Java records!你也应该爱!别忽视 records。这个不起眼的小 record 不仅仅是比 Lombok 的 @Data 注解做类似事情更好的方式,它实际上是 Java 21 中达到顶峰并结合在一起的一些特性的一部分,它们共同支持一种叫做 数据导向编程 的东西。
Java 语言架构师 Brian Goetz 在他 2022 年发表于 InfoQ 的关于数据导向编程的文章中谈到了这一点。
Java 统治了单体应用的世界,理由是其强大的访问控制、良好而快速的编译器、隐私保护等等。Java 使创建相对模块化、可组合的单体应用变得容易。单体应用通常是庞大、散乱的代码库,Java 支持它。确实,如果你想要模块化并想很好地组织你的大型单体代码库,可以看看 Spring Modulith 项目。
但情况变了。如今,我们表达系统变化的方式不再是抽象类型深层层次结构的专门实现(通过动态分派和多态性),而是通过 HTTP/REST、gRPC、Apache Kafka 和 RabbitMQ 等消息传递层发送的那些通常是临时的消息。笨蛋,是数据!
Java 已经发展到支持这些新模式。让我们看看四个关键特性——records、模式匹配、智能 switch 表达式和 sealed types——来了解我的意思。假设我们在一个受到严格监管的行业工作,比如金融。
想象一下我们有一个叫做 Loan 的接口。显然,贷款是受到严格监管的金融工具。我们不希望有人随便添加一个 Loan 接口的匿名内部类实现,绕过我们辛辛苦苦构建到系统中的验证和保护。
所以,我们将使用 sealed types。Sealed types 是一种新的访问控制或可见性修饰符。
package com.example.service;
sealed interface Loan permits SecuredLoan, UnsecuredLoan {
}
record UnsecuredLoan(float interest) implements Loan {
}
final class SecuredLoan implements Loan {
}
在示例中,我们明确规定系统中有两个 Loan 的实现:SecuredLoan 和 UnsecuredLoan。类默认是开放给子类继承的,这违反了 sealed 层次结构所隐含的保证。所以,我们明确地将 SecuredLoan 设为 final。UnsecuredLoan 实现为一个 record,它是隐式 final 的。
Records 是 Java 对元组的回应。它们就是元组。只不过 Java 是一种命名语言:事物有名字。这个元组也有名字:UnsecuredLoan。如果我们同意 records 所蕴含的契约,records 会给我们很多力量。records 的核心理念是,对象的身份等于 record 中字段(它们被称为“组件”)的身份。所以在这个例子中,record 的身份等于 interest 变量的身份。如果同意这一点,那么编译器可以给我们一个构造函数,它可以为每个组件提供存储空间,它可以给我们一个 toString 方法、一个 hashCode 方法和一个 equals 方法。它还会给我们构造函数中的组件访问器。不错!而且,它支持解构!语言知道如何提取 record 的状态。
现在,假设我想为每种 Loan 类型显示一条消息。我将编写一个方法。这是最初的简单实现。
@Deprecated
String badDisplayMessageFor(Loan loan) {
var message = "";
if (loan instanceof SecuredLoan) {
message = "good job! ";
}
if (loan instanceof UnsecuredLoan) {
var usl = (UnsecuredLoan) loan;
message = "ouch! that " + usl.interest() + "% interest rate is going to hurt!";
}
return message;
}
这行得通,某种程度上。但它并未物尽其用。
我们可以清理一下。让我们利用模式匹配,像这样
@Deprecated
String notGreatDisplayMessageFor(Loan loan) {
var message = "";
if (loan instanceof SecuredLoan) {
message = "good job! ";
}
if (loan instanceof UnsecuredLoan usl) {
message = "ouch! that " + usl.interest() + "% interest rate is going to hurt!";
}
return message;
}
更好。注意,我们使用模式匹配来匹配对象的形状,然后将确定可转换的东西提取到一个变量 usl 中。虽然我们甚至不需要 usl 变量,对吧。相反,我们想解引用 interest 变量。所以我们可以改变模式匹配来提取那个变量,像这样。
@Deprecated
String notGreatDisplayMessageFor(Loan loan) {
var message = "";
if (loan instanceof SecuredLoan) {
message = "good job! ";
}
if (loan instanceof UnsecuredLoan(var interest) ) {
message = "ouch! that " + interest + "% interest rate is going to hurt!";
}
return message;
}
如果我注释掉其中一个分支会发生什么?什么也不会!编译器不在乎。我们没有处理代码可能经过的关键路径之一。
同样,我将这个值存储在一个变量 message 中,并将其作为某个条件的副作用进行赋值。如果我能去掉中间值并直接返回某个表达式,岂不是更好?让我们来看看使用智能 switch 表达式这种 Java 中另一个巧妙的新特性的更简洁实现。
String displayMessageFor(Loan loan) {
return switch (loan) {
case SecuredLoan sl -> "good job! ";
case UnsecuredLoan(var interest) -> "ouch! that " + interest + "% interest rate is going to hurt!";
};
}
这个版本使用智能 switch 表达式来返回值和模式匹配。如果你注释掉其中一个分支,编译器会报错,因为——得益于 sealed types——它知道你还没有穷尽所有可能的选项。太棒了!编译器为我们做了很多工作!结果既更简洁又更具表现力。大部分如此。
好了,回到我们正常的编程日程。为 Spring Data JDBC repository 添加一个接口,并添加一个 Spring MVC controller 类。然后启动应用。注意,这会花费非常长的时间!那是因为在幕后,它正在使用 Docker daemon 启动 PostgreSQL 实例。
但从现在起,我们将使用 Spring Boot 的 DevTools。你只需要重新编译。如果应用正在运行,并且你使用的是 Eclipse 或 Visual Studio Code,你只需要保存文件:在 macOS 上按 CMD+S。IntelliJ IDEA 没有 Save 选项;在 macOS 上按 CMD+Shift+F9 强制构建。不错。
好了,我们有了一个照看着数据库的 HTTP web 端点,但数据库里什么也没有,所以肯定会失败。让我们用一些 schema 和一些示例数据来初始化我们的数据库。
添加 schema.sql 和 data.sql。
我们应用的 DDL,schema.sql
create table if not exists customer (
id serial primary key ,
name text not null
) ;
应用的一些示例数据,data.sql
delete from customer;
insert into customer(name) values ('Josh') ;
insert into customer(name) values ('Madhura');
insert into customer(name) values ('Jürgen') ;
insert into customer(name) values ('Olga');
insert into customer(name) values ('Stéphane') ;
insert into customer(name) values ('Dr. Syer');
insert into customer(name) values ('Dr. Pollack');
insert into customer(name) values ('Phil');
insert into customer(name) values ('Yuxin');
insert into customer(name) values ('Violetta');
确保通过将以下属性添加到 application.properties 来告诉 Spring Boot 在启动时运行 SQL 文件
spring.sql.init.mode=always
重新加载应用:在 macOS 上按 CMD+Shift+F9。在我的电脑上,这次重新加载的时间大约是重启 JVM 和应用本身所需时间的 1/3,或者说减少了 66%。巨大提升。
应用已经启动并运行了。访问 https://:8080/customers 查看结果。成功了!当然,它成功了。这是一个演示。它注定会成功。
这都是相当标准的常规操作。十年前你也可以做类似的事情。请注意,代码会啰嗦得多。从那时起,Java 已经取得了飞跃性的进步。当然,速度也无法相比。而且,抽象也更好了。但你确实可以做类似的事情——一个照看着数据库的 web 应用。
事情在变化。总有新的领域。现在,新的领域是人工智能,或称 AI。AI:显然,寻找老一套的智能还不够难。
AI 是一个庞大的产业,但大多数人想到 AI 时,他们想到的是利用 AI。你不需要使用 Python 来使用大型语言模型(LLMs),就像大多数人不需要使用 C 来使用 SQL 数据库一样。你只需要与 LLMs 集成,而在这方面,Java 在选择和能力上首屈一指。
在我们 2023 年的上一场重要开发者活动 SpringOne 上,我们宣布了 Spring AI,这是一个旨在让集成和使用 AI 尽可能简单的全新项目。
你可能想摄取数据,比如来自账户、文件、服务,甚至是 PDF 文件集。你可能想将它们存储在向量数据库中以便于检索,以支持相似性搜索。然后你可能想与 LLM 集成,将来自该向量数据库的数据提供给它。
当然,你可以找到任何你想要的 LLMs 的客户端绑定——Amazon Bedrock、Azure OpenAI、Google Vertex 以及 Google Gemini、Ollama、HuggingFace,当然还有 OpenAI 本身,但这仅仅是个开始。
驱动 LLM 的所有知识都内置在模型中,该模型随后影响 LLM 对世界的理解。但该模型有一定的“保质期”,过期后其知识就会过时。如果模型是两周前构建的,它就不会知道昨天发生的事情。所以,如果你想构建一个自动助理,例如,处理用户关于银行账户的请求,那么该 LLM 在处理时就需要获知世界最新的状态。
你可以在请求中添加信息,并将其用作上下文来指导响应。如果事情就这么简单,那倒也没什么。但还有另一个问题。不同的 LLMs 支持不同的令牌窗口大小(token window sizes)。令牌窗口决定了你在给定请求中可以发送和接收多少数据。窗口越小,你可以发送的信息就越少,LLM 在响应中的信息量也就越少。
这里你可能要做的一件事是将数据放入向量存储(vector store)中,例如 pgvector、Neo4j、Weaviate 等等,然后将你的 LLM 连接到该向量数据库。向量存储使你能够在给定一个词或一组词的情况下,找到与它们相似的其他事物。它将数据存储为数学表示,并允许你查询相似的事物。
这个摄取、丰富、分析和消化数据以指导 LLM 响应的整个过程被称为检索增强生成(Retrieval Augmented Generation,RAG),Spring AI 支持所有这些。更多信息,请参阅我关于 Spring AI 的这个 Spring Tips 视频。然而,我们在这里不会利用所有这些功能。只利用其中一个。
我们在 Spring Initializr 上添加了 OpenAI 支持,所以 Spring AI 已经在 classpath 中。添加一个新的 controller,像这样
一个由 AI 驱动的 Spring MVC controller
package com.example.service;
import org.springframework.ai.chat.ChatClient;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.Map;
@Controller
@ResponseBody
class StoryController {
private final ChatClient singularity;
StoryController(ChatClient singularity) {
this.singularity = singularity;
}
@GetMapping("/story")
Map<String, String> story() {
var prompt = """
Dear Singularity,
Please write a story about the good folks of San Francisco, capital of all things Artificial Intelligence,
and please do so in the style of famed children's author Dr. Seuss.
Cordially,
Josh Long
""";
var reply = this.singularity.call(prompt);
return Map.of("message", reply);
}
}
相当直接!注入 Spring AI 的 ChatClient,用它向 LLM 发送请求,获取响应,并将其作为 JSON 返回给 HTTP 客户端。
你需要通过一个属性来配置与 OpenAI API 的连接,例如 spring.ai.openai.api-key=。我在运行程序之前将其导出为一个环境变量,SPRING_AI_OPENAI_API_KEY。我不会在这里泄露我的密钥。请原谅我不会泄露我的 API 凭据。
按 CMD+Shift+F9 重新加载应用,然后访问端点:https://:8080/story。LLM 可能需要几秒钟来生成响应,所以准备好你的咖啡、水或别的什么,以便快速而满意地喝一口。
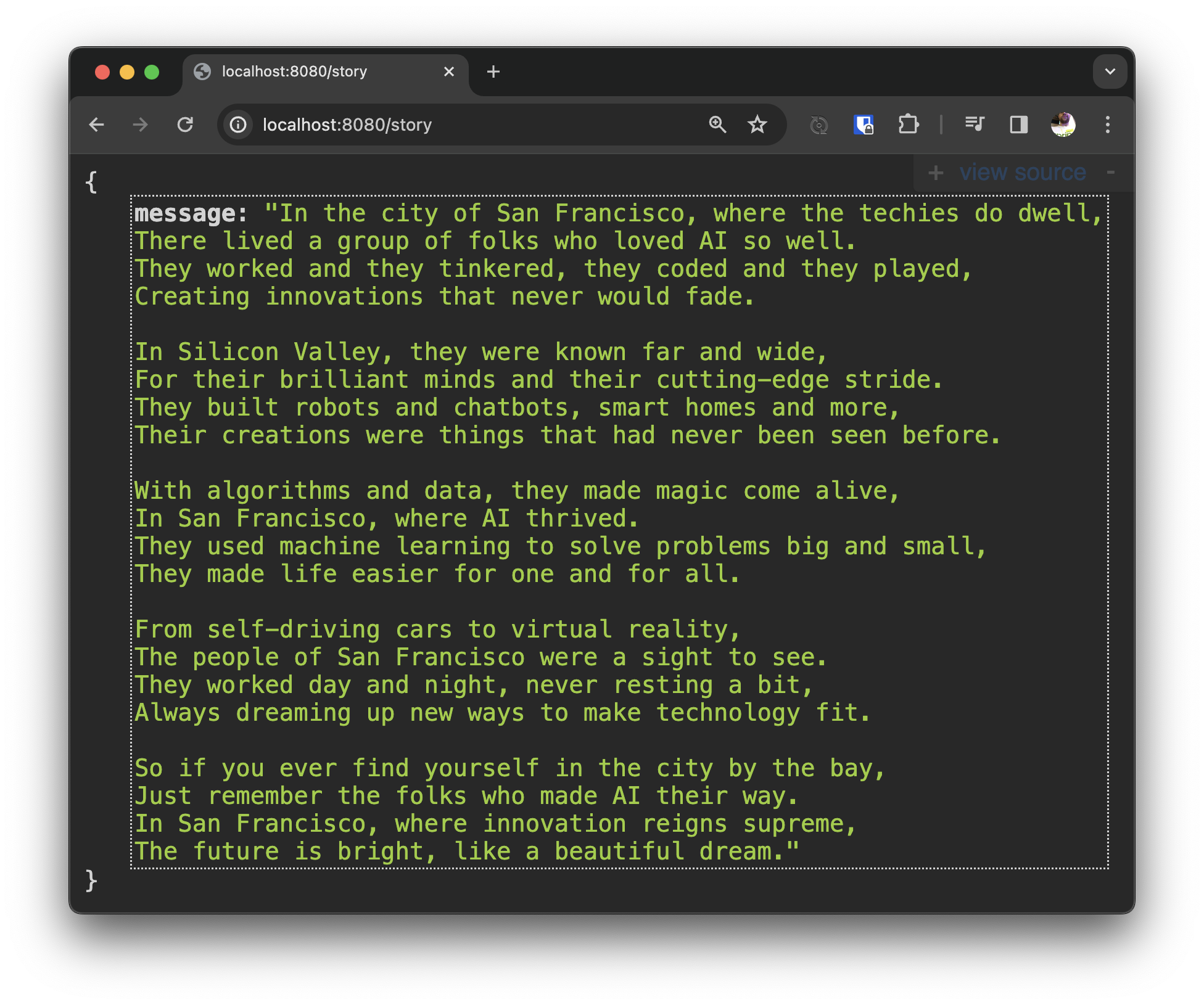
看!我们生活在一个奇迹时代!该死的奇点时代!你现在什么都能做。
但确实花了几秒钟,不是吗?我不怪电脑花这点时间!它做得太棒了!我可快不了那么多。看看它生成的故事吧!简直是艺术品。
但确实花了一段时间。这对我们的应用的可伸缩性有影响。我们在幕后调用 LLM 时,正在进行网络调用。在代码深处某个地方,有一个 java.net.Socket,我们从中获取了一个 java.io.InputStream,它表示来自服务的 byte 数组数据。我不知道你是否还记得直接使用 InputStream。这里有一个例子
try (var is = new FileInputStream("afile.txt")) {
var next = -1;
while ((next = is.read()) != -1) {
next = is.read();
// do something with read
}
}
看到我们在调用 InputStream.read 从 InputStream 中读取字节的那部分了吗?我们称之为阻塞操作(blocking operation)。如果我们在第四行调用 InputStream.read,那么我们必须等待该调用返回后才能执行第五行。
如果我们要连接的服务返回了太多数据怎么办?如果服务宕机了怎么办?如果它永远不返回怎么办?如果我们永远被困在等待中怎么办?如果……?
如果只发生一次,这只是令人厌烦。但如果它可能发生在系统中用于处理 HTTP 请求的每个线程上,那将是对我们服务的生存威胁。这种情况经常发生。这就是为什么可以登录到一个本应无响应的 HTTP 服务,却发现 CPU 基本处于休眠状态——空闲!——什么都没做或几乎没做什么。线程池中的所有线程都卡在等待状态,等待着永远不会来的东西。
这是对我们花钱购买的宝贵 CPU 容量的巨大浪费。而且即使是最好的情况也不好。即使方法最终会返回,仍然意味着处理该请求的线程对系统中的其他任何东西都不可用。该方法独占了该线程,因此系统中的其他任何人都无法使用它。如果线程便宜且充裕,这不是问题。但它们并非如此。在 Java 的大部分生命周期中,每个新线程都与一个操作系统线程一一对应。这并不便宜。每个线程都有一定量的簿记开销。一到两兆字节。所以你无法创建很多线程,而且你在浪费你仅有的那点线程。太可怕了!反正谁需要睡觉了?
一定有更好的办法。
你可以使用非阻塞 IO。比如那些会让人痔疮发作般复杂的 Java NIO 库。这是一种选择,就像和一窝臭鼬一起住是一种选择一样:太臭了!反正我们大多数人思考问题时也不是非阻塞 IO 或常规 IO 的角度。我们生活在抽象层次更高的层级。我们可以使用反应式编程。我热爱反应式编程。我甚至写了一本关于它的书——Reactive Spring。但如果你不习惯像函数式程序员那样思考,就不太清楚如何让它工作。它是一个不同的范式,意味着需要重写你的代码。
如果我们既能得到非阻塞的好处,又能保留传统的编程模式呢?使用 Java 21,现在可以了!有一个叫做虚拟线程(virtual threads)的新特性,让这一切变得超级简单!如果你在这些新的虚拟线程上做了阻塞的事情,运行时会检测到你正在进行阻塞操作——比如 java.io.InputStream.read、java.io.OutputStream.write 和 java.lang.Thread.sleep——并将那个阻塞的、空闲的活动从线程上移开,放入 RAM 中。然后,它会为睡眠设置一个定时器,或者监控 IO 的文件描述符,同时让运行时将该线程用于其他任务。当阻塞操作完成后,运行时会将其移回线程,让它从暂停的地方继续执行,而你的代码几乎无需修改。这有点难以理解,所以我们来看一个例子。我毫不脸红地借用了 Oracle 开发者布道师 José Paumard 的这个例子。
这个例子演示了创建 1,000 个线程并在每个线程上休眠 400 毫秒,同时记录这 1,000 个线程中第一个线程的名称。
package com.example.service;
import org.springframework.boot.ApplicationRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.ArrayList;
import java.util.Set;
import java.util.concurrent.ConcurrentSkipListSet;
@Configuration
class Threads {
private static void run(boolean first, Set<String> names) {
if (first)
names.add(Thread.currentThread().toString());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Bean
ApplicationRunner demo() {
return args -> {
// store all 1,000 threads
var threads = new ArrayList<Thread>();
// dedupe elements with Set<T>
var names = new ConcurrentSkipListSet<String>();
// merci José Paumard d'Oracle
for (var i = 0; i < 1000; i++) {
var first = 0 == i;
threads.add(Thread.ofPlatform().unstarted(() -> run(first, names)));
}
for (var t : threads)
t.start();
for (var t : threads)
t.join();
System.out.println(names);
};
}
}
我们使用 Thread.ofPlatform 工厂方法创建普通的平台线程(platform threads),其性质与 Java 在 20 世纪 90 年代首次亮相以来我们创建的线程基本相同。程序创建了 1,000 个线程。在每个线程中,我们休眠 100 毫秒,重复四次。期间,我们测试是否是这 1000 个线程中的第一个,如果是,我们通过将其添加到集合(set)中来记录当前线程的名称。集合会去除重复元素;如果同一个名字出现多次,集合中仍然只有一个元素。
运行程序(CMD+Shift+F9!)你会看到程序的物理特性没有改变。Set<String> 中只有一个名字。为什么会这样呢?我们只是反复测试了同一个线程。
现在,将构造函数更改为使用虚拟线程:Thread.ofVirtual。这是超级简单的更改。现在运行程序。CMD+Shift+F9。
你会看到集合中不止一个元素。你完全没有改变代码的核心逻辑。事实上,你只需要改变一个地方,但现在,在幕后,编译器和运行时无缝地重写了你的代码,以便当虚拟线程上发生阻塞时,运行时会无缝地将你移开,并在阻塞事情完成后将你移回线程。这意味着你之前所在的线程现在可供系统的其他部分使用。你的可伸缩性将 skyrocketing!
你可能会抗议说,我不想改变所有代码。首先,这是个荒谬的论点,改动微不足道。你可能会抗议:我也不想自己去创建线程。好观点。Tony Hoare 在 20 世纪 70 年代写道,NULL 是价值 10 亿美元的错误。他错了。实际上是 PHP。但是,他也详细谈论了使用线程构建系统是多么不可行。你肯定想使用更高阶的抽象,比如 sagas、actors,或者至少是一个 ExecutorService。
还有一个新的虚拟线程执行器:Executors.newVirtualThreadPerTaskExecutor。不错!如果你使用 Spring Boot,覆盖该类型的默认 bean 并在系统中使用它非常简单。Spring Boot 会将其引入并转而使用它。很容易。但如果你使用 Spring Boot 3.2——你肯定在用 Spring Boot 3.2,对吧?你意识到每个版本大概只支持一年,对吧?务必查看给定Spring 项目的支持策略。如果你正在使用 3.2,那么你只需在 application.properties 中添加一个属性,我们就会为你插入虚拟线程支持。
spring.threads.virtual.enabled=true
不错!无需更改代码。现在你应该能看到显著提升的可伸缩性,如果你的服务是 IO 密集型的,你可能可以减少负载均衡器中的一些实例。我的建议?告诉你老板你要为公司节省一大笔钱,但坚持要把这笔钱加到你的工资里。然后部署这个改动。瞧!
好了,我们进展很快。我们有 git clone 即运行的能力。我们有 Docker compose 支持。我们有 DevTools。我们有一种非常好的语言和语法。我们有了该死的奇点。我们进展很快。我们有了可伸缩性。在构建中添加 Spring Boot Actuator,现在你就有了可观测性。我觉得是时候转向生产环境了。
我想把这个应用打包,并使其尽可能高效。各位朋友,这里有几件事需要考虑。首先,我们如何容器化这个应用?简单。使用 Buildpacks。很容易。记住,朋友不会让朋友写 Dockerfiles。使用 Buildpacks。Spring Boot 也原生支持它们:./gradlew bootBuildImage 或 ./mvnw spring-boot:build-image。但这也不是新东西了,所以下一个问题。
我们如何让这东西尽可能高效和优化?朋友们,在深入讨论之前,重要的是要记住 Java 已经非常非常非常高效了。我喜欢这篇来自 2018 年、COVID 大流行之前(也就是 BC)的博客文章。
它考察了哪些语言使用的能源最少,或者说能效最高。C 是能效最高的。它使用的电最少。1.0。这是基准。它对机器来说是高效的。对人可不是!绝对不是人。
然后是 Rust 和它的零成本抽象。做得好。
然后是 C++... 
C++ 太恶心了!继续……
然后是 Ada 语言,但是……谁在乎?
然后我们有 Java,接近 2.0。我们就四舍五入说 2.0 吧。Java 的效率是 C 的一半,或者说比 C 低两倍!
目前为止还不错吧?太棒了。不过它仍在能效最高的前 5 种语言之列!
如果你向下滚动列表,会看到一些惊人的数字。Go 和 C# 大约在 3.0+ 的范围。再向下滚动,我们有 JavaScript 和 TypeScript,其中一种——令我百思不得其解的是——比另一种效率低四倍!
然后是 PHP 和 Hack,这两个越少提及越好。继续!
然后是 JRuby 和 Ruby。朋友们,记住 JRuby 是用 Java 写的 Ruby。而 Ruby 是用 C 写的 Ruby。然而,JRuby 的效率几乎比 Ruby 高三分之一!仅仅因为它是用 Java 写的,并且运行在 JVM 上。JVM 是一个了不起的工具。绝对非凡。
然后……我们有 Python。这可真是让我很难过!我热爱 Python!我从 20 世纪 90 年代就开始使用 Python 了!我第一次学 Python 时,比尔·克林顿还是总统!但这些数字可不好。想想看。75.88。我们四舍五入到 76。我数学不太好。但你知道谁数学好吗?该死的 Python!我们来问它。
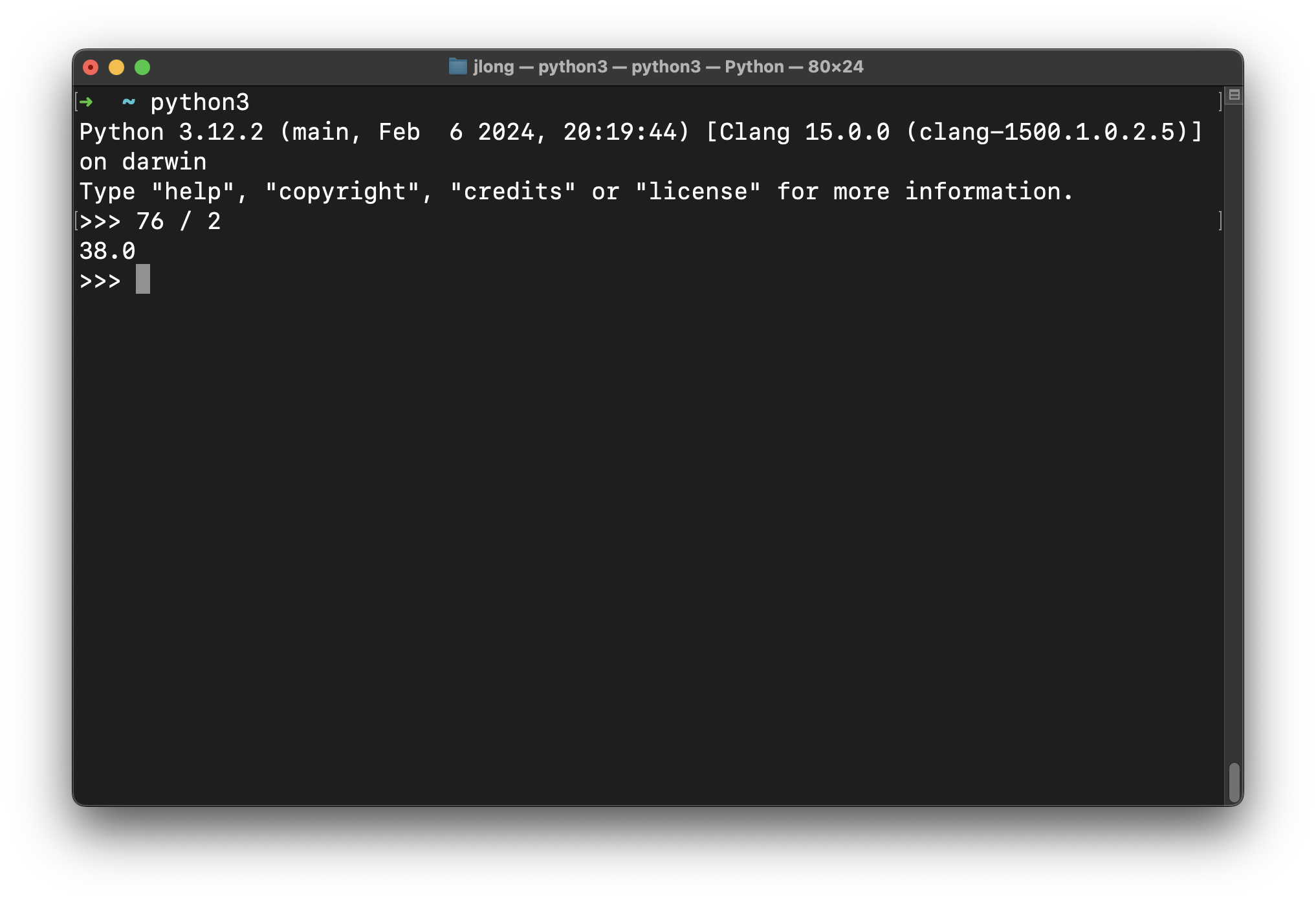
38!这意味着如果你用 Java 运行一个程序,生成所需能量会产生一些碳排放,这些碳会滞留在大气中,升高温度,而这个升高的温度反过来会杀死一棵树,那么用 Python 运行等效的程序将杀死三十八棵树!那是一片森林!这比比特币还糟糕!我们必须尽快对此采取行动。我不知道具体该做什么,但必须做点什么。
总之,我想说的是,Java 已经非常棒了。我认为这是因为人们习以为常的两件事:垃圾回收(garbage collection)和即时(Just In Time,JIT)编译器。
垃圾回收(Garbage collection),嗯,我们都知道它是什么。说实在的,甚至白宫也在其最近关于保障软件以保障网络空间基石的报告中赞赏垃圾回收、内存安全的语言,比如 Java。
Java 编程语言的垃圾回收器让我们编写平庸的软件,并且某种程度上可以“蒙混过关”。太厉害了!话虽如此,我确实不同意它是最初的 Java 垃圾回收器这种说法!那个荣誉属于别处,比如可能属于Jesslyn。
JIT 是另一个很棒的工具。它分析应用程序中经常访问的代码路径,并将它们转换成特定于操作系统和架构的原生代码。但它只能对部分代码这样做。它需要知道编译代码时涉及的类型是运行时唯一会涉及的类型。而 Java 中一些东西——一种运行时更类似于 JavaScript、Ruby 和 Python 的高度动态语言——允许 Java 程序做一些会违反这个限制的事情。比如序列化(serialization)、JNI、反射(reflection)、资源加载(resource loading)和 JDK 代理(JDK proxies)。记住,使用 Java,你可以有一个 String,其内容是 Java 源代码文件,将这个字符串编译成文件系统上的一个 .class 文件,将 .class 文件加载到 ClassLoader 中,通过反射创建该类的一个实例,然后——如果该类是一个接口——创建一个该类的 JDK 代理。如果该类实现了 java.io.Serializable,则可以通过网络 socket 写入该类实例,并在另一个 JVM 上加载它。所有这些都可以在不显式使用 java.lang.Object 之外的任何类型引用的情况下完成!这是一种了不起的语言,这种动态特性使其成为一种非常有生产力的语言。它也阻碍了 JIT 的优化尝试。
尽管如此,JIT 在力所能及的地方做得非常出色。结果不言自明。所以,人们会想:为什么我们不能预先(ahead of time)主动 JIT 整个程序呢?我们可以的。有一个叫做 GraalVM 的 OpenJDK 分发版,它包含许多好东西,用额外的工具(比如 native-image 编译器)扩展了 OpenJDK 发布版。原生镜像编译器很棒。但这个原生镜像编译器有同样的限制。它对非常动态的东西无能为力。这就是一个问题。因为大多数代码——你的单元测试库、你的 web 框架、你的 ORM、你的日志库……一切!——都使用了这些动态行为中的一个或全部。
有一个应急方案(escape hatch)。你可以在一个知名目录下以 .json 文件的形式向 GraalVM 编译器提供配置:src/main/resources/META-INF/native-image/$groupId/$artifactId/\*.json。这些 .json 文件有两个问题。
首先,“JSON”这个词听起来很蠢。我不喜欢说“JAY-SAWN”。作为一个成年人,我不敢相信我们竟然会对彼此说这样的话。我会法语,在法语里,你会把它发音成 jeeesã。所以,.gison。好听多了。闽南语里有个词——gingsong(幸福),这个发音也行。所以你可以用 .gingsong。站队吧!不管怎样,.json 都不应该再用了。我站队 .gison,但这其实不重要。
第二个问题是,咳,它要求的东西实在太多了!再说一次,想想你的程序在多少地方做了这些有趣、动态的事情,比如反射、序列化、JDK 代理、资源加载和 JNI!简直没完没了。你的 Web 框架。你的测试库。你的数据访问技术。我没时间为每个程序手工编写配置。我连写完这篇博客的时间都不够!
所以,我们将转而使用 Spring Boot 3.0 中引入的预编译(AOT)引擎。AOT 引擎会分析 Spring 应用中的 Bean,并为你发出必需的配置文件。太好了!甚至还有一个完整的组件模型,你可以用它来扩展 Spring 到编译时。我在这里不会深入讲解所有这些,但你可以阅读我的免费电子书或观看我的免费 YouTube 视频,其中介绍了所有与Spring 和 AOT相关的内容。内容基本相同,只是消费方式不同。
所以让我们用 Gradle 启动构建,./gradlew nativeCompile,或者如果你使用 Apache Maven,则使用 ./mvnw -Pnative native:compile。你可能想跳过这次的测试… 这个构建会花一点时间。记住,它正在分析代码库中的所有东西——无论是在 classpath 上的库、JRE,还是你自己代码中的类——来确定哪些类型应该保留,哪些应该丢弃。结果是一个精简、高效、速度极快的运行时机器,但代价是编译时间非常、非常慢。
事实上,它花的时间实在太长了,以至于它有点阻碍了我的流畅性。它让我彻底停下了脚步,等着。我就像这篇博客前面提到的平台线程一样:阻塞了!我感到无聊。等着。等着。我现在终于理解了这个著名的 XKCD 漫画。
有时我开始哼歌。或者主题曲。或者电梯音乐。你知道电梯音乐听起来是什么样的,对吧?永不停歇,没完没了。所以我想,如果大家都能听到电梯音乐,那不是很好吗?于是我问了。得到了一些很棒的回复。
有人建议,我们的朋友建议我们播放来自任天堂 64 视频游戏的配乐中的电梯音乐,这款游戏是皮尔斯·布鲁斯南首次出演詹姆斯·邦德的《黄金眼》(Goldeneye)。我喜欢这个主意。

另一个回复建议说,有哔哔声会很有用。再同意不过了。我那愚蠢的微波炉完成时会发出 ding! 的一声。我的百万行编译器为什么不能呢?

然后我们收到了这个回复,来自我另一位最喜欢的博士,Niephaus 博士,他在 GraalVM 团队工作。他说,添加电梯音乐只会解决症状,而不是问题的根源,根源在于如何让 GraalVM 在时间和内存方面更加高效。
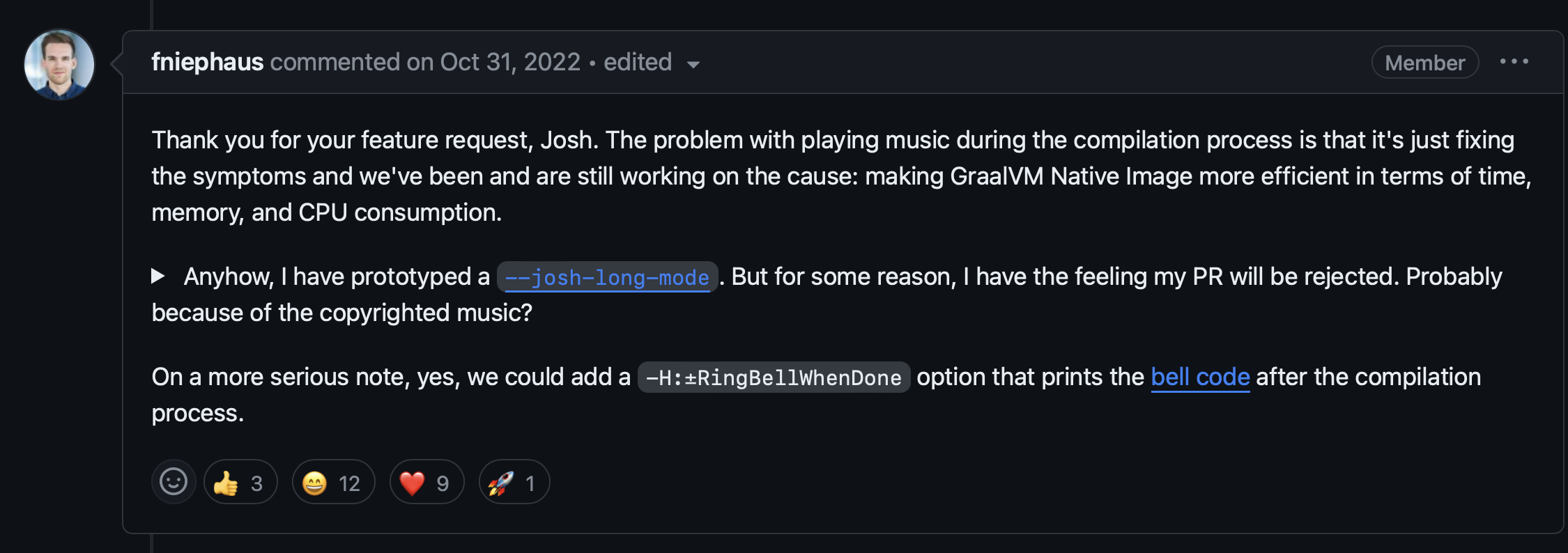
好的。但他确实分享了这个有希望的原型!

我相信它随时都会合并进去...
总之!如果你查看编译情况,现在应该已经完成了。它在 ./build/native/nativeCompile/ 文件夹里,名字叫 service。在我的机器上,编译花了 52 秒。天哪!
运行它。它会失败,因为,再说一次,我们过的是 git clone 然后运行的生活方式!我们没有指定任何连接凭据!所以,通过环境变量指定你的 SQL 数据库连接详情来运行它。这是我在我的机器上使用的脚本。这只适用于 Unix 类的操作系统,Maven 和 Gradle 都适用。
#!/usr/bin/env bash
export SPRING_DATASOURCE_URL=jdbc:postgresql:///mydatabase
export SPRING_DATASOURCE_PASSWORD=secret
export SPRING_DATASOURCE_USERNAME=myuser
SERVICE=.
MVN=$SERVICE/target/service
GRADLE=$SERVICE/build/native/nativeCompile/service
ls -la $GRADLE && $GRADLE || $MVN
在我的机器上,它在大约 100 毫秒内启动!像火箭一样快!而且,显然,如果我使用 Spring Cloud Function 来构建 AWS Lamba 风格的函数即服务,它会更快得多,因为我例如就不需要打包一个 HTTP 服务器。事实上,如果我真正想要的只是纯粹的启动速度,那我甚至可能会使用 Spring 对Project CRaC 的出色支持。这也不是这里要说的重点。我不太关心这个,因为它是一个独立的、长期运行的服务。我关心的是资源使用情况,以驻留集大小(RSS)表示。记下进程标识符(PID)——它会在日志中。如果 PID 是,比如说,55,那么你可以像这样使用几乎所有 Unix 系统上都有的 ps 工具来获取 RSS
ps -o rss 55
它会输出一个以千字节为单位的数字;除以一千,你就会得到以兆字节为单位的数字。在我的机器上,它运行只需要略多于 100MB 的内存。你不能在这么小的内存里运行 Slack!我敢打赌你的 Chrome 浏览器里随便一个标签页占用的内存都比这个多,甚至更多!
所以,我们有了一个程序,它既简洁,又易于开发和迭代。它使用虚拟线程为我们提供了无与伦比的可伸缩性。它作为一个独立的、自包含的、特定于操作系统和架构的本机映像运行。哦!而且,它竟然支持奇点(singularity)!
我们生活在一个令人惊叹的时代。现在是成为 Java 和 Spring 开发人员的最佳时机。我希望我也说服了你。
我,以及 Spring 团队的其他成员,将在微软的 JDConf 2024 大会上发表演讲!
注册并参加我在 JDConf 的会议:Bootiful Spring Boot 3
在 JDConf 上可以参加的其他 Spring 会议:
如果你喜欢这篇博客,我希望你会订阅我们的YouTube 频道,我在其中每周都有新视频在Spring Tips 播放列表里。当然,你可以在Biodrop上找到我的 Twitter/X、网站、YouTube 频道、书籍、播客等等。谢谢!