
保持领先
VMware 提供培训和认证,助你飞速进步。
了解更多Spring Data JPA 的一个便捷功能是通过其 @Query 注解让你插入自定义 JPA 查询。
这提供了一些灵活性,因为你仍然能够向应用程序的消费者提供排序参数。请看下面的示例
interface SampleRepository extends CrudRepository<Employee, Long> {
@Query("select e from Employee e where e.firstName = :firstName")
List<Employee> findCustomEmployees(String firstName, Sort sort);
}
当不仅提供标准 (firstName) 还通过 findCustomEmployees("Alice", Sort.by("lastName")) 提供自定义排序时,Spring Data JPA 会将此自定义查询转化为一个完整的 JPA 查询,如下所示
select e
from Employee e
where e.firstName = :firstName
order by e.lastName
除此之外,Spring Data JPA 支持分页,这需要能够计算结果集。
过去,随着查询越来越复杂,我们“做正确的事情”并应用能正确指向主 SELECT 子句别名值的“order by”子句的能力,至少可以说是一项挑战。
用一个合适的 count() 函数包装投影也很棘手。想象一下当有子查询、case 语句和其他深度查询时做这件事!
我们很高兴地宣布 HQL 和 JPQL 解析器均已发布,这将使你更容易在 Spring Data JPA 应用程序中定制查询。
我们利用 JPA 和 Hibernate 规范,开发了基于 ANTLR 的查询解析引擎,并使用它们更恰当地应用服务你所需定制。
我们不仅能找到放置 count() 函数的“正确位置”并获取主 FROM 表达式的别名,还能检测语义情况。
有了查询解析器,更容易识别有效与无效查询。有时,在弄清楚如何正确处理查询之前,我们花费更多时间来确定查询是否正确。
好消息是……它会自动应用。
使用 @Query 注解时,有一个关键参数:isNative。这个布尔标志让你指明你是在编写原生 SQL (isNative=true) 还是 JPA 查询 (默认为 isNative=false)。
如果你有一个 JPA 查询 (isNative=false) 并且 Hibernate 在类路径上,它将使用我们的新 HQL 解析器。如果 Hibernate 不在类路径上,它将回退到功能有限的 JPQL 解析器。(受规范限制,而非我们的实现。)
因此,你只需要获取 Spring Data 发布列车的最新快照版本(Spring Data 3.1 snapshots)或 Spring Boot 的下一个里程碑版本即可。
还有更多功能待添加。例如,可以有更复杂的别名,例如
select AVG(e.timeToCloseTickets) as avg
from Employee e
当你对此类查询应用 Sort.by("avg") 时,不应产生 order by e.avg,而应仅为 order by avg。我们正在研究添加支持其他场景。但有了这些查询解析器,支持这些情况变得容易得多。
我们还有一些与查询解析相关的积压工单,现在可以着手解决了。
额外提示:如果你想预先检查我们自己的自定义查询,使用现有工具可以一窥究竟。
如果你使用 IntelliJ IDEA,有一个 ANTLR 插件(https://plugins.jetbrains.com/plugin/7358-antlr-v4),安装后可以运行任何 ANTLR 语法文件并对其进行测试。
src/main/antlr4/org/springframework/data/jpa/repository/query/Hql.g4。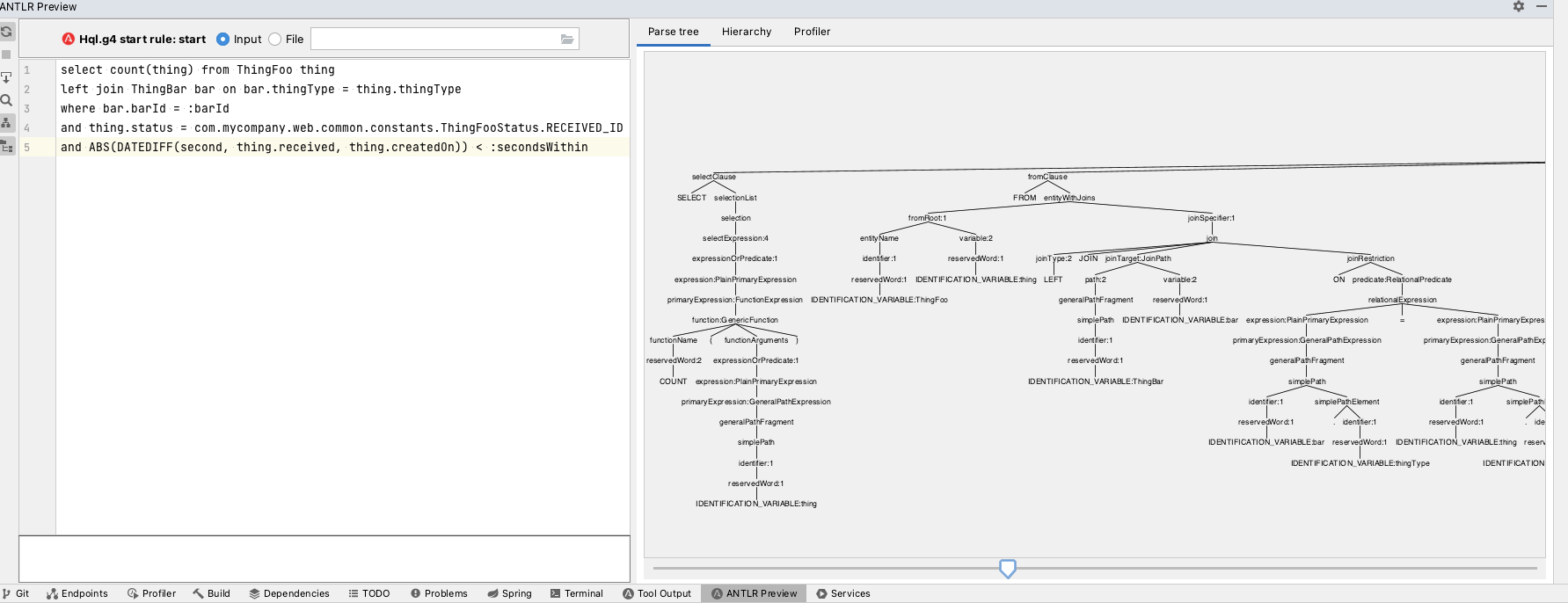
(我们最近向大家征集最疯狂的 JPA 查询,这是其中之一。一眼看上去,这个查询是有效的,你甚至可以放大查看更多细节。)
敬礼,——Greg Turnquist