
领先一步
VMware 提供培训和认证,助您加速进步。
了解更多我谨代表 Spring Batch 团队,非常高兴地宣布 Spring Batch 4.2.0.RC1 的发布。我们一直在对核心框架进行一些性能改进,本文将重点介绍主要的变更。
我们进行了一些性能改进,包括:
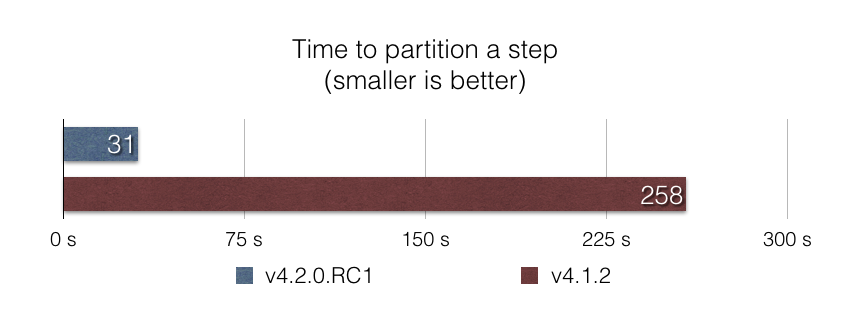
启动一个分区(partitioned)的 Step 是框架优化不足的领域之一。在此版本中,我们深入研究了分区过程,以找出此性能问题的根本原因。分区过程的主要步骤之一是查找最后一次 Step 执行(以查看当前执行是否是重新启动)。我们发现查找最后一次 Step 执行涉及到在内存中加载给定 Job 实例的所有 Job 执行的所有 Step 执行,这显然效率低下!
我们用一个 SQL 查询替换了这段代码,该查询在数据库级别进行查找,只返回最后一次 Step 执行。结果非常出色:根据我们的基准测试 partitioned-step-benchmark,使用此方法将 Step 执行分区到 5000 个分区,速度提高了近 10 倍。
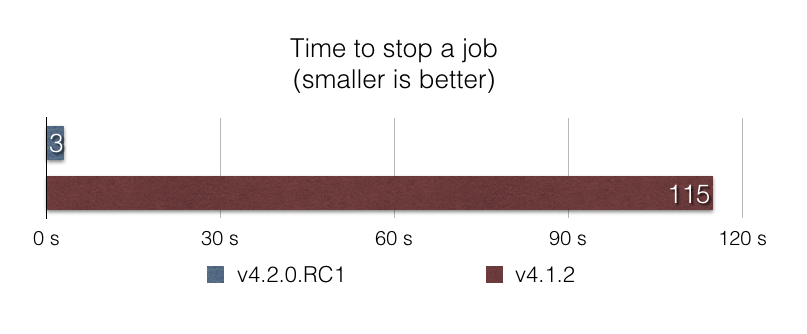
运行 Job 时可能会出现问题… 而优雅地停止一个破坏性的 Job 应该快速高效,以避免数据损坏。在 v4.1 之前,使用 CommandLineJobRunner 停止 Job 的性能很差,因为需要加载所有 Job 执行以查找 Job 执行当前是否正在运行。通过这种方法,在拥有数千个 Job 执行的生产数据库中,停止 Job 可能需要数分钟!
在此版本中,我们通过使用 SQL 查询优化了停止过程,该查询在数据库级别进行过滤。同样,结果令人印象深刻:根据我们的基准测试 stop-benchmark,当数据库中有 100,000 个给定 Job 的 Job 执行时,使用此方法停止 Job 的速度快了近 40 倍。
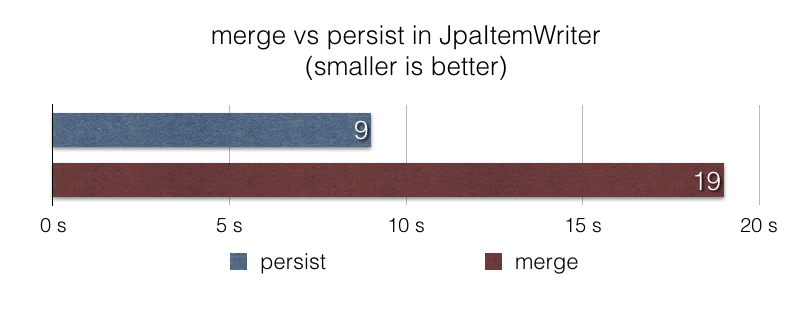
JpaItemWriter 实现更快的写入JpaItemWriter 使用 javax.persistence.EntityManager#merge 函数将项写入 JPA 持久化上下文。当项的持久化状态未知或已知是更新时,这很合理。然而,在许多文件摄取 Job 中,数据被认为是新的并且应该被视为插入,使用 javax.persistence.EntityManager#merge 效率不高。
在此版本中,我们在 JpaItemWriter 中引入了一个新选项,以便在这些场景中使用 persist 而不是 merge。使用这个新选项,一个使用 JpaItemWriter 向数据库插入 100 万个项的文件摄取 Job,根据我们的基准测试 jpa-writer-benchmark,速度提高了 2 倍。
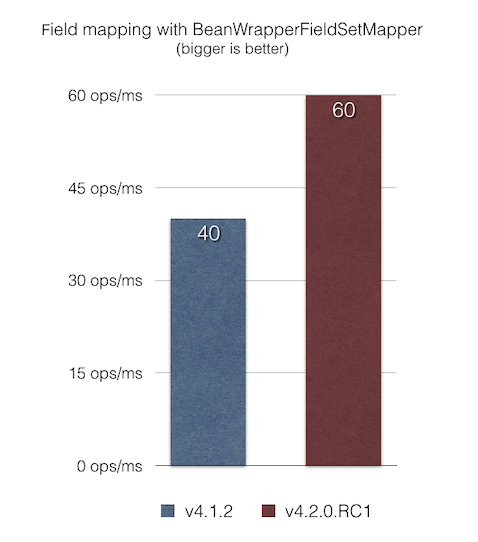
BeanWrapperFieldSetMapper 优化 Bean 映射BeanWrapperFieldSetMapper 提供了一个方便的功能,它允许我们使用模糊匹配给定 JavaBean 的字段名(驼峰命名法、嵌套属性等)。但是,当字段名与列名匹配时,可以通过将 distanceLimit 参数设置为 0 来启用精确匹配。
在此版本中,我们修复了 BeanWrapperFieldSetMapper 中的一个性能问题,该问题在每次迭代时都通过反射进行字段名内省,即使请求了精确匹配(通过设置 distanceLimit=0)。根据我们的 JMH 基准测试 bean-mapping-benchmark,项映射现在比以前的版本快 1.5 倍。
请注意,这些数字在您的实际情况中可能会有所不同。我们鼓励您尝试 Spring Batch 4.2.0.RC1(可以与 Spring Boot 2.2.0.M6 一起使用),并分享您的反馈。有关更改的完整列表,请参阅版本 4.2.0.RC1 和 4.2.0.M3 的变更日志。
欢迎在 Twitter 上随时提及 @michaelminella 或 @b_e_n_a_s,或在 StackOverflow 或 Gitter 上提问。如果您发现任何问题,请在 Jira 上创建一个工单。
我们计划稳定这个新的候选版本,用于即将发布的 Spring Batch 4.2.0.RELEASE,计划于 2019 年 9 月 30 日发布。敬请期待!
所有基准测试均在 Macbook Pro 16GB RAM, 2.9 GHz Intel Core i7 CPU, MacOS Mojave 10.14.5, Oracle JDK 1.8.0_201 上进行。您可以在以下链接中找到所有基准测试的源代码: