
领先一步
VMware 提供培训和认证,助您快速进步。
了解更多JVM 可能是一个复杂的“野兽”。幸运的是,大部分复杂性都隐藏在底层,作为应用程序开发者和部署者,我们通常不必为此过多担忧。随着基于容器的部署策略兴起,JVM 的内存占用成为了需要关注的一个复杂领域。
JVM 将其内存分为两个主要类别:堆内存(heap memory)和非堆内存(non-heap memory)。堆内存是人们通常最熟悉的部分。它是应用程序创建的对象存储的地方。它们一直保留在那里,直到不再被引用并被垃圾回收。通常,应用程序使用的堆大小会随当前负载的变化而波动。
JVM 的非堆内存被划分为几个不同的区域。我们可以使用 HotSpot VM 的原生内存跟踪(NMT)来检查其在这些区域的内存使用情况。请注意,虽然 NMT 并不能跟踪所有的原生内存使用(例如,它不跟踪第三方原生代码的内存分配),但对于大多数典型的 Spring 应用程序来说,这已经足够了。可以通过使用 -XX:NativeMemoryTracking=summary 启动应用程序,然后使用 jcmd <pid> VM.native_memory summary 来显示内存使用摘要。
让我们以 Petclinic——我们的老朋友——为例来演示 NMT 的用法。下面的饼状图显示了使用 48MB 最大堆 (-Xmx48M) 启动 Petclinic 时,NMT 报告的 JVM 内存使用情况(减去其自身开销)。
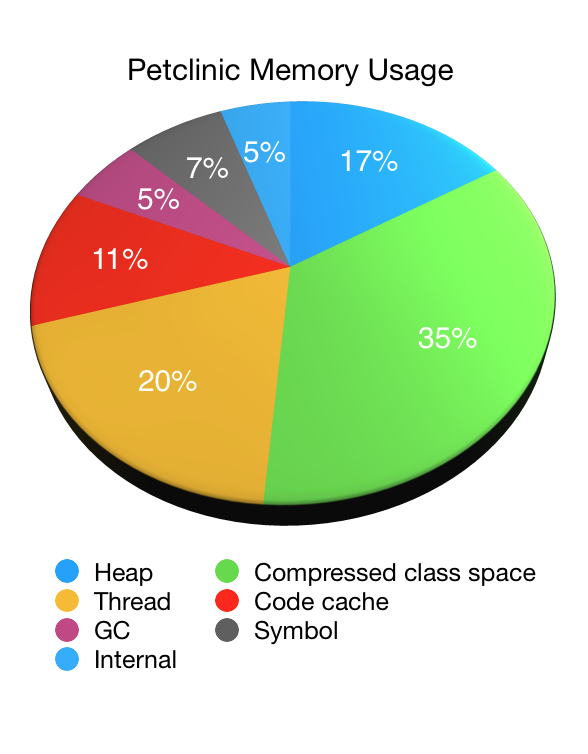
如您所见,非堆内存占用了 JVM 内存使用的绝大部分,而堆内存仅占总量的六分之一。在本例中,堆内存约为 44MB(其中垃圾回收后立即使用了 33MB)。非堆内存总共使用了 223MB。
MaxMetaspaceSize 限制。其大小取决于已加载类的数量。ReservedCodeCacheSize 限制。可以通过调整 JIT 来减小其大小,例如禁用分层编译。与堆内存相比,非堆内存在负载下的波动较小。一旦应用程序加载了所有将使用的类并且 JIT 完全预热后,情况就会稳定下来。要减少压缩类空间的使用,需要对加载类的类加载器进行垃圾回收。这在过去将应用程序部署到 servlet 容器或应用服务器时更为常见——应用程序的类加载器会在应用程序卸载时被垃圾回收——但在现代应用程序部署方法中很少发生。
配置 JVM 以有效利用给定量的可用 RAM 并非易事。如果您使用 -Xmx16M 启动 JVM 并期望它最多使用 16MB RAM,您将会遇到一个令人不快的“惊喜”。
在调整 JVM 大小时,一个有趣的领域是 JIT 的代码缓存。默认情况下,HotSpot JVM 最多会使用 240MB。如果代码缓存太小,JIT 将耗尽空间来存储其输出,从而导致性能下降。如果缓存太大,内存可能会被浪费。调整代码缓存大小时,重要的是要同时关注其对应用程序内存使用和性能的影响。
在 Docker 容器中运行时,最新版本的 Java 现在能够感知容器的内存限制,并尝试相应地调整 JVM 大小。不幸的是,这种调整通常会过度分配非堆内存而分配不足堆内存。假设您的应用程序运行在一个拥有 2 个 CPU 和 512MB 可用内存的容器中。您希望它能够处理更多负载,因此将 CPU 增加到 4 个,内存增加到 1GB。如上所述,堆使用通常会随负载变化,而非堆使用则变化不大。因此,我们希望将额外增加的 512MB 内存的大部分分配给堆,以应对增加的负载。不幸的是,JVM 默认情况下不会这样做,而是会在其堆和非堆区域之间更平均地分配额外的内存。
值得庆幸的是,CloudFoundry 团队在 JVM 的内存占用方面拥有丰富的知识。如果您将应用程序推送到 CloudFoundry,build pack 会自动为您应用这些知识。如果您未使用 CloudFoundry,或者想了解更多关于如何调整 JVM 大小的信息,可以阅读 设计文档,这是 Java buildpack 内存计算器第三版的设计文档,强烈推荐进一步阅读。
Spring 团队投入了大量时间思考性能和内存利用率,同时考虑了堆内存和非堆内存的使用。限制非堆内存使用的一种方法是使框架的某些部分尽可能通用。一个例子是使用反射来创建依赖并将其注入到应用程序的 Bean 中。由于使用了反射,所使用的框架代码量保持不变,无论您的应用程序包含多少 Bean。我们使用基于堆的缓存来优化启动时间,在启动完成后清除此缓存。然后,堆内存可以很容易地被垃圾回收器回收,从而在应用程序处理其工作负载时为您的应用程序提供尽可能多的可用内存。