
抢占先机
VMware 提供培训和认证,助您加速发展。
了解更多Spring Cloud Data Flow 团队很高兴宣布发布 Data Flow 的 2.0 版本。请遵循以下入门指南,以便在本地、Cloud Foundry 和 Kubernetes 上运行。
同时发布的还有 Spring Cloud Skipper 的 2.0 版本。如果你想将 Skipper 与 Data Flow 分开使用,参考指南中的入门部分是最好的起点。
流部署始终委托给 Skipper
可在所有支持的平台上运行的单一服务器
针对多个平台启动任务
UI 改进
标准化使用 OAuth2 和 OpenID Connect 实现安全性
改进了已部署应用的指标和监控
使用 micrometer 更新分析功能
数据库迁移支持
更新至 Boot 2.1
更新内部实现以使用 JPA
任务/作业执行和性能改进
Data Flow Server 的 1.x 系列允许流由 Data Flow Server 直接部署或委托给 Skipper 部署。这导致了两种操作模式:'经典模式'和'skipper模式'。现在,部署流只有一个选项,即通过 Skipper,它支持在所有支持的平台上部署,并为长期运行的流应用提供滚动升级和降级功能。在架构上,任务仍像以前一样由 Data Flow 服务器部署,但现在可以跨不同平台部署。有关此功能的更多信息,请参阅下文。
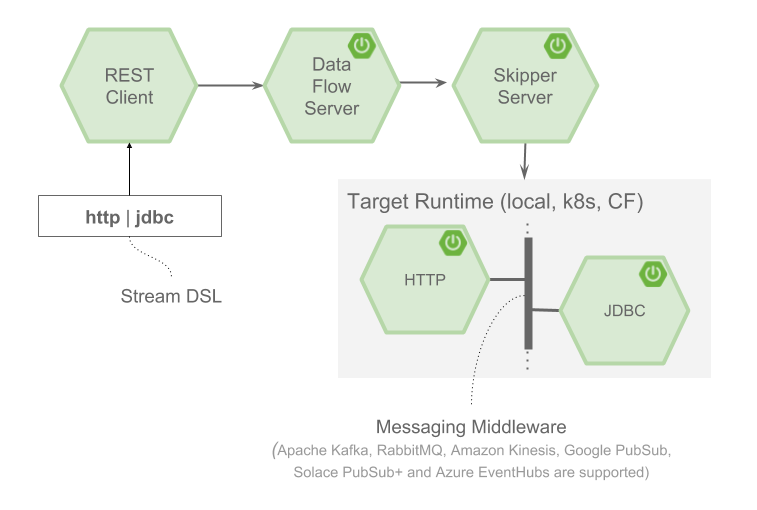
我们将本地、Cloud Foundry 和 Kubernetes 服务器整合到一个单一服务器中,无需根据您想运行的平台选择不同的 jar 或 docker 镜像。每个平台的入门步骤基本保持不变。一个重大变化是任务的配置方式(见下文),因为我们现在支持跨不同平台启动任务的功能。与以前的版本一样,长期运行的应用程序可以部署到不同的平台。
启动任务时,可以指定其执行平台。以前,此功能仅适用于流和应用部署。Data Flow 服务器允许您配置多个 Kubernetes 和 Cloud Foundry 任务平台。当您希望在多个平台上编排数据管道,同时从中心位置管理它们时,此功能特别有用。
例如,如果您在 Cloud Foundry 的 org1/space1 中运行 Data Flow,您可以在 org2/space2 或 Kubernetes 集群的命名空间中启动任务。类似地,如果您在 Kubernetes 的 namespace 中运行 Data Flow,您可以在 namespace2 或 Cloud Foundry 的 org1/space1 中启动任务。如果在本地运行 Data Flow 服务器,您可以指定不同的本地任务平台,例如具有不同的 JVM 属性,以此替代使用任务部署属性。文档描述了如何为 本地、Cloud Foundry 和 Kubernetes 配置多个任务平台
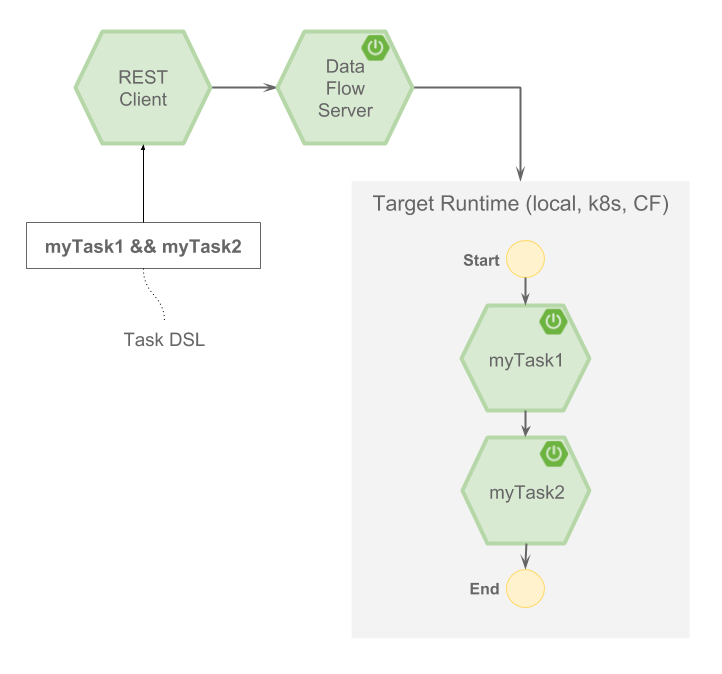
UI 支持针对一系列后端平台启动任务。
UI/UX 为流和任务启动构建了始终如一的体验。
基于另一个重要的功能集,现在可以根据 Data Flow 中定义的细粒度角色自动启用/禁用 Dashboard 功能。
Grafana 启动图标已原生集成到 Dashboard 的 Streams 和 Runtime 页面中。配置 Data Flow 以对接可用的 Micrometer 后端后,只需点击一下即可监控流式管道的指标,例如消息速率、错误计数和延迟!
现在支持新增一个按钮,用于回滚到流的上一版本。
分析选项卡已被移除,并替换为指向由 micrometer 提供数据的 Grafana 面板的链接。
Angular 已升级到 7.2.4
根据用户反馈,在作业执行页面内添加了一个作业重启按钮。
UI 和 Data Flow 服务器现在支持按日期搜索审计记录。

我们在改进安全性方面投入了大量精力,将 OAuth2 和 OpenID Connect 作为默认安全实现。传统的安全选项已被移除。基于令牌的授权、密码授权类型验证和 LDAP 集成是一些可选方案,它们在 UAA 作为后端时得到了持续支持。
新增了新的细粒度角色来管理流/任务部署操作。这种细粒度更好地与预期的操作对齐,并且客户端工具(Shell 和 Dashboard)也会自动适应。
提供了一个示例应用程序,演示了如何将 Spring Cloud Data Flow 与基于 LDAP 安全的 Cloud Foundry 用户账户和认证 (UAA) 服务器结合使用。还提供了文档和示例代码,展示了如何配置 DataFlowTemplate 以使用 OAuth2.0。报告了近期 CVE 的依赖库已更新。
以下视频演示了新的 OAuth2 安全功能以及使用 LDAP 支持的 UAA 构建的组合任务示例
Data Flow 2.0 引入了一种新的架构来收集和显示流的应用指标。Data Flow 1.4 中引入的 Data Flow Metrics Collector 已被移除。
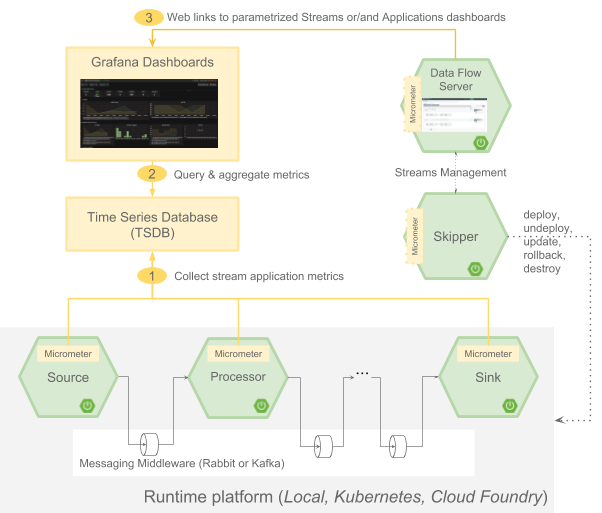
这种新架构基于在已部署的应用中使用 Micrometer 库将指标发送到流行的监控系统,然后使用 Grafana 可视化指标。应用启动器 Einstein 发布列车中的每个应用都包含了用于 Prometheus、InfluxDB 和 DataDog 的 Micrometer 库。
我们提供了如何开始使用 Prometheus 和 InfluxDB 作为在您的笔记本电脑上本地运行 Data Flow 时的监控系统的说明。还提供了如何开始使用 Prometheus 作为在 Kubernetes 上运行 Data Flow 时的监控系统的说明。
还提供了从 Data Flow UI 到 Grafana 面板的链接。还提供了两个 Grafana 面板,一个显示更侧重于应用的视图,另一个显示更侧重于流的视图。以下是基于 Prometheus 的 Grafana 面板截图,显示了流中应用的消息速率。
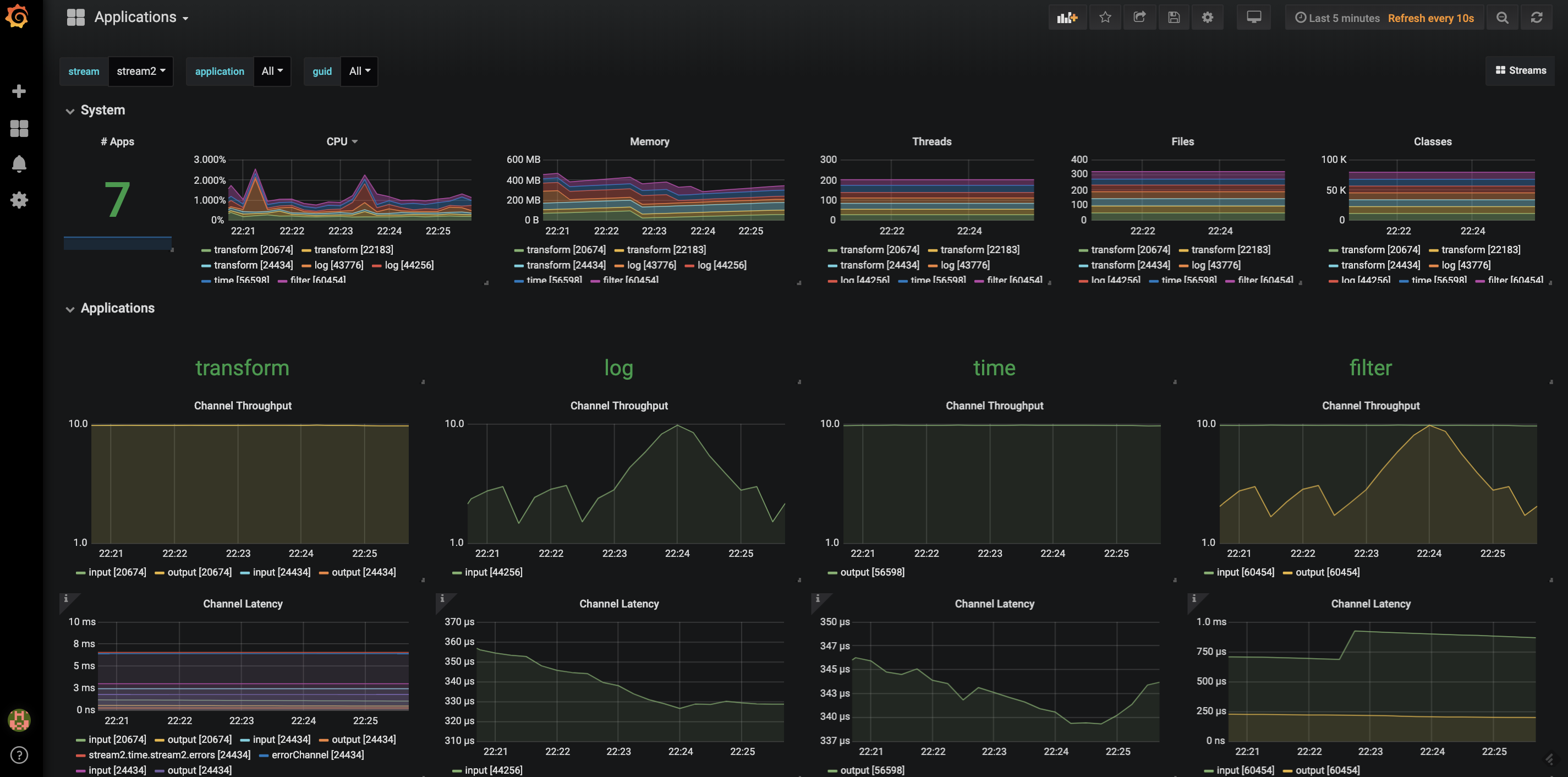
应用和流的选择器使您能够导航到特定感兴趣的区域。
这是一个展示流监控实际运行的短视频。
在 Data Flow 2.0 中,Redis 计数器的使用已被 Micrometer 库提供的计数器取代。应用启动器 Einstein 发布列车现在提供了 计数器处理器(Counter Processor) 和 计数器 Sink(Counter Sink)。Twitter 分析示例应用已更新为使用新的计数器实现,并提供了一个 Grafana 面板,显示了 Data Flow Analytics UI 之前显示内容的等效视图。

这是一个展示新分析功能实际运行的短视频。
Flyway 迁移代码已得到改进,并使用一套基于 Docker 的集成测试在所有支持的数据库上进行了测试。
Data Flow Server 2.0 版本现在基于 Spring Boot 2.1。随着这一基础的转变,我们花了一些时间来解决技术债务并采用 Spring Boot 的新功能。随着 Data Flow 2.0 GA 的发布,我们将继续解决技术债务领域的问题并进行一些额外的内部重构。
从 Spring XD 迁移到 Data Flow 1.x 时,我们保留了一些类似 'key-value' 的表,并通过 Spring JDBC API 进行管理。现在我们更新为使用 Spring Data JPA。
感谢社区成员 Nicolas Widart 提交的关于任务执行及其相关性能问题的详尽错误报告。
新增了一个端点,以避免对客户端工具中后台使用的现有 REST 资源造成破坏性更改。通过这些更改,任务/批处理执行历史查询速度提高了近 10 倍,在批处理作业包含数百个步骤时尤其有帮助。
虽然我们对 2.1 有一些功能计划,但未来几个月的重点将放在文档、入门指南、视频和整体用户体验上。Data Flow 的新站点也在计划中。
另请注意,Spring Cloud Data Flow 的 1.x 系列将从本 2.0 GA 发布日期(2020年3月7日)起十二个月内停止维护。
一如既往,我们欢迎反馈和贡献,请通过 Stackoverflow、GitHub 或 Gitter 与我们联系。