
领先一步
VMware 提供培训和认证,助你快速提升。
了解更多目录
Micrometer 是一个维度优先(dimensional-first)的指标收集外观(facade),旨在通过一个供应商中立的 API 来帮助你对代码进行计时、计数和测量。通过 classpath 和配置,你可以选择一个或多个监控系统来导出你的指标数据。想象一下,它就像 SLF4J,但用于指标!
Micrometer 是 Spring Boot 2 的 Actuator 中包含的指标收集工具。通过添加额外的依赖,它也已被反向移植到 Spring Boot 1.5、1.4 和 1.3 版本。
Micrometer 在 Spring Boot 1 中已有的计数器(counters)和测量器(gauges)基础上添加了更丰富的仪表元语(meter primitives)。例如,一个 Micrometer Timer(计时器)能够生成与吞吐量、总时间、近期样本的最大延迟、预计算的分位数、分位数直方图以及 SLA 边界计数相关的时序数据。
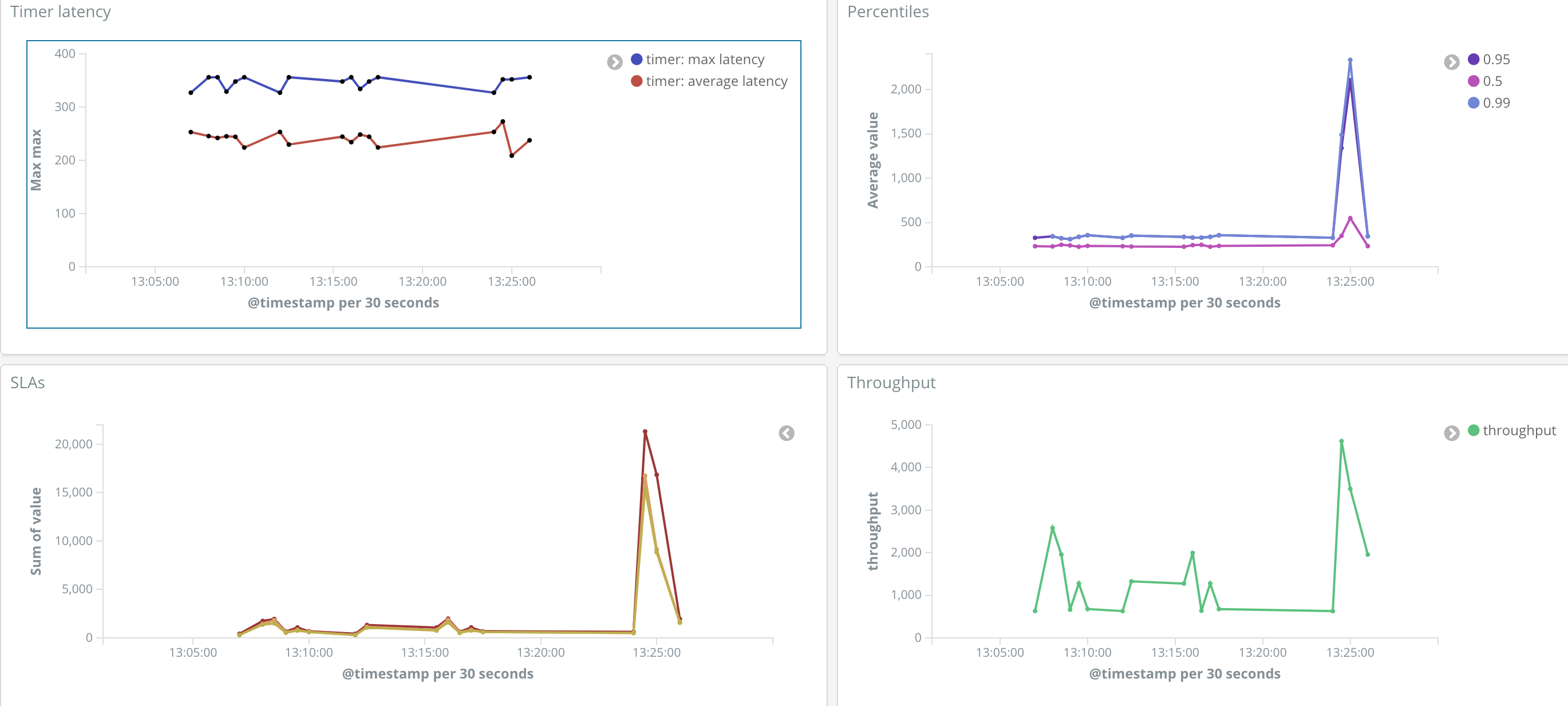
尽管专注于维度指标,Micrometer 仍然可以映射到分层名称,以继续支持像 Ganglia 这样的旧式监控解决方案或像 JMX 这样范围较窄的工具。向 Micrometer 的转变源于更好地服务于一系列维度监控系统(如 Prometheus、Datadog、Wavefront、SignalFx、Influx 等)的需求。Spring 的一个优势是通过抽象实现选择自由。通过与 Micrometer 集成,Spring Boot 使你今天能够选择使用一个或多个监控系统,并且随着需求的改变,将来可以改变选择,而无需重写你的自定义指标检测代码。
在决定开发“又一个”指标收集库之前,我们认真研究了现有或新兴的维度收集器。但当我们研究如何导出到越来越多的监控系统时,名称和数据结构的重要性变得显而易见。Micrometer 构建了命名规范化、时间单位基础缩放以及对直方图数据等结构的专有表达式支持等概念,这些对于使指标在每个目标系统中发挥作用至关重要。在此过程中,我们还添加了仪表过滤功能,让你能够更好地控制上游依赖项的检测。
提示
要了解更多关于 Micrometer 的功能,请参阅其参考文档,特别是概念部分。
Spring Boot 2 自动配置了相当多的指标,包括:
JVM,报告以下利用情况:
各种内存和缓冲池
垃圾回收相关统计信息
线程利用率
加载/卸载的类数量
CPU 使用率
Spring MVC 和 WebFlux 请求延迟
RestTemplate 延迟
缓存利用率
数据源利用率,包括 HikariCP 连接池指标
RabbitMQ 连接工厂
文件描述符使用情况
Logback:记录每个级别记录到 Logback 的事件数量
运行时间:报告一个测量器表示运行时间,以及一个固定测量器表示应用程序的绝对启动时间
Tomcat 使用情况
其中许多指标在 Spring Boot 1 中曾以某种形式存在,但在 Spring Boot 2 中增加了更多细节和标签,得到了丰富。
Micrometer 提供了一个供应商中立的指标收集 API(根植于 io.micrometer.core.instrument.MeterRegistry)以及各种监控系统的实现,包括:
Netflix Atlas
CloudWatch
Datadog
Ganglia
Graphite
InfluxDB
JMX
New Relic
Prometheus
SignalFx
StatsD(Etsy、dogstatsd、Telegraf 和专有格式)
Wavefront
对其他系统的支持正在进行中或计划在定于 2018 年中旬发布的 1.1.0 版本中实现,包括:
AppOptics
Azure Application Insights
Dynatrace
Elasticsearch
StackDriver
Spring Boot 2 配置了一个复合 MeterRegistry,可以向其中添加任意数量的注册表实现,从而允许你将指标发送到多个监控系统。通过 MeterRegistryCustomizer,你可以一次性定制整个注册表集合,或者专门定制单个实现。例如,一种常见的配置是 (1) 将指标导出到 Prometheus 和 CloudWatch,(2) 为流向两者的指标添加一组通用标签(例如,主机和应用程序标识标签),以及 (3) 只将一小部分指标列入 CloudWatch 的白名单。
通过指标(metrics),我们特指那一类信息,它允许你从整体上(跨单个应用的多个组件、集群中的多个实例、不同环境或区域中运行的集群等)理解系统的性能。
值得注意的是,这不包括用于理解单个请求在经过一系列服务时,各个组件对其总延迟贡献的信息;这是分布式追踪收集器(如 Spring Cloud Sleuth、Zipkin 的 Brave 等)的职责。
分布式追踪系统提供关于子系统延迟的详细信息,但为了扩展性通常会进行采样(例如,Spring Cloud Sleuth 默认发送 10% 的样本)。指标数据通常是预先聚合的,因此自然缺乏关联信息,但也不会进行采样。因此,对于在一分钟间隔内有 10 万个请求,其中包含与服务 A 的交互,并可能根据输入包含与服务 B 的交互的情况:
指标数据会告诉你,总体而言,服务 A 的观察吞吐量为 10 万请求,服务 B 的观察吞吐量为 6 万请求。此外,在那一分钟内,服务 A 的最大总体平均延迟为 100ms,服务 B 的最大总体平均延迟为 50ms。它还会提供该时间段内的最大延迟和其他分布统计信息。
分布式追踪系统会告诉你,对于某个特定请求(但不是所有请求的总集,因为记住正在进行采样),服务 A 花费了 50ms,服务 B 花费了 90ms。
你可能可以从指标数据合理地推断出,在最差用户体验中花费的时间大约一半在 A 服务中,一半在 B 服务中,但你无法确定,因为你看到的是聚合数据,完全有可能在最差情况下,所有 100ms 都花在了服务 A 中,而服务 B 根本没有被调用。
反之,从追踪数据中你无法推断出某个时间间隔内的吞吐量或最差的用户体验。
Spring Boot 1 的指标接口本质上是分层的。这意味着发布的指标完全由其名称标识。所以你可能会有一个名为 jvm.memory.used 的指标。
当你查看单个应用程序实例的指标时,这似乎很合适。但是,如果你有 10 个实例都将 jvm.memory.used 发布到同一个监控系统怎么办?如果某个实例的内存消耗意外飙升,我们如何区分它们?
通常的答案是修改名称,例如通过在名称中添加前缀或后缀。因此我们可以将名称更改为 ${HOST}.jvm.memory.used,其中用 ${HOST} 替换主机名。重新部署所有 10 个实例后,我们现在可以确定哪个实例正面临内存压力。在典型的分层监控系统中,我们可以通过某种方式使用通配符来计算所有实例的总内存使用量,例如:
*.jvm.memory.used
现在假设我们在 3 个部署区域中,每个区域都有 10 个应用程序实例。此外,我们希望按区域分析应用程序的平均或最大内存占用。现在,如果我们为指标名称添加额外的分区前缀(使其看起来像 ${REGION}.${HOST}.jvm.memory.used),我们就会破坏现有的查询。我们可以更新查询来计算所有实例的总内存使用量,例如:
*.*.jvm.memory.used
不幸的是,这会使我们无法看到现有基础设施的数据,直到所有实例都使用新的前缀重新部署完毕。这只是分层命名方法的一个局限性的例子。
我们已经提到,Micometer 是一个维度优先(dimensional-first)的指标收集器。在 Micrometer 中,同样的指标会使用标签(tag,也称为维度 dimension)进行记录,例如:
Gauge.builder("jvm.memory.used", ..)
.tag("host", "MYHOST")
.tag("region", "us-east-1")
.register(registry);
维度监控系统自然会汇总所有标签下的 jvm.memory.used 指标,直到你进一步细化查询一个或多个标签。在维度监控系统中,查询会首先选择名称(jvm.memory.used),然后允许按标签进行后续过滤。在我们上面的场景中,如果之前有一个基于主机内存消耗飙升的图表/警报,然后后来添加了区域标签,那么基于主机的查询将继续不间断地工作,同时新的包含区域信息的指标也在你的基础设施中推广。
仪表过滤器允许你控制仪表的注册方式和时间以及它们发出的统计信息类型。仪表过滤器主要有三个基本功能:
拒绝(或接受)仪表的注册。
转换仪表 ID(例如,更改名称、添加或删除标签、更改描述或基本单位)。
配置某些仪表类型的分布统计信息(例如,计时器和分布摘要的分位数、直方图、SLA)。
Spring Boot 2 将一系列属性绑定到一个开箱即用的仪表过滤器,允许你通过属性控制指标的发出。例如:
management.metrics.enable.jvm=false
management.metrics.distribution.percentiles-histogram.http.server.requests=true
management.metrics.distribution.sla.http.server.requests=1ms,5ms
上述配置关闭了所有以“jvm”为前缀的指标,为 Spring Boot 自动配置的 http 服务器请求指标发布分位数直方图,并发送小于等于 1ms 和 5ms SLA 边界的请求计数,这样你就可以准确地看到有多少请求符合你的预期。SLA 分布配置也是使你能够可视化更复杂测量指标(如 Apdex 分数)的核心功能。
你可以在根级别完全切换指标的启用状态,只为你想要的一小部分指标生成白名单。假设你只想要 JVM 指标,而不需要其他指标,可以这样配置:
management.metrics.enable.all=false
management.metrics.enable.jvm=true
在 Spring Boot 1 中提供一个列出所有指标的单个 REST 端点是很简单的,因为我们只有计数器和测量器,并且它们都是分层的。更复杂的类型如计时器(timers)代表多个时间序列(它们至少包含一个计数、一个最大值和一个总和)。此外,我们的指标变成了维度的。很快就清楚了,无法在一个单一的载荷中输出所有这些信息。即使对于一个维度计数器,我们是否要显示每个标签组合的聚合数据?为了简洁起见,将其扁平化为分层名称,就会变成这样:
http.server.requests.method.GET.response.200.uri./foo=100
http.server.requests.method.GET.response.500.uri./foo=1
http.server.requests.method.GET.response.200.uri./bar=5
http.server.requests.method.GET.response.400.uri./foo=1
# and now the aggregates...
http.server.requests.method.GET=107
http.server.requests.method.GET.response.200=105
http.server.requests.method.GET.uri./foo=101
http.server.requests.response.200.uri./foo=100
http.server.requests.response.500.uri./foo=1
http.server.requests.response.200.uri./bar=5
...
正如你所见,这很快就变得难以维护。例如,如果你想基于 MeterRegistry 的内容构建一个自定义 UI,并且你知道你的 UI 只关心按 URI 划分的 http 吞吐量,而忽略方法、状态等信息,那么输出可以大幅精简。对于这类情况,我们建议创建一个组件,只向你的 UI 提供所需的数据。将 MeterRegistry 注入到你的组件中,并使用它的 find 和 get 方法搜索你需要暴露的指标。然后以适合你用途的格式对其进行序列化。
你可以在 slack.micrometer.io 的 Slack、Twitter 上的 @micrometerio 以及 Github 上获得 Micrometer 支持。如有问题、建议或困扰,请随时联系我们!