
领先一步
VMware 提供培训和认证,助力你快速提升。
了解更多我受到 OpenZipkin 贡献者及 Spring Cloud Sleuth 和 Zipkin 贡献者 Adrian Cole 介绍 Zipkin 的史诗级演讲 的启发撰写了这篇文章。那场演讲内容如此丰富,读完这篇后,请务必观看!
技术的进步和云计算使得轻松地部署和启动服务变得更加容易。云计算使我们能够将与启动新服务相关的痛苦(从几天或几周(天哪!)缩短到几分钟!)自动化。这种速度的提高反过来使我们更加敏捷,可以思考更小的独立可部署服务批次。新服务的激增使得推理系统范围和特定请求的性能特征变得复杂。
当应用程序的所有功能都存在于一个*单体*中——我们称之为编写为一个大型、完整的可部署单元(如 `.war` 或 `.ear`)的应用程序——推理问题出在哪里要容易得多。有内存泄漏吗?它在单体中。某个组件没有正确处理请求吗?它在单体中。消息丢失了?很可能也在单体中。分布式改变了一切。
系统在负载下和大规模运行时表现不同。系统行为的规范通常与系统的实际行为存在差异,并且实际行为本身在不同上下文中也可能有所不同。在请求通过系统传输时,对其进行情境化处理非常重要。同样重要的是能够讨论特定请求的性质,并能够理解该特定请求相对于过去一分钟、一小时、一天(或其他任何!)其他有用的时间间隔内类似请求的一般行为。情境有助于我们确定请求是否异常以及是否值得关注。在确定什么是*正常*的基准之前,你无法在系统中追踪 bug。*长*到底有多长?对于某些系统来说可能是微秒,对于另一些系统来说可能是秒或分钟!
在这篇文章中,我们将探讨支持分布式追踪的 Spring Cloud Sleuth 如何帮助我们建立这种情境,并帮助我们更好地理解系统的实际行为,而不仅仅是其规范的行为。
理论上,追踪很简单。当请求在系统中从一个组件流向另一个组件,通过入口和出口点时,**追踪器**会在可能的地方添加逻辑,以延续第一次请求时生成的唯一**追踪 ID**。当请求到达其旅程中的某个组件时,会为该组件分配一个新的 **Span ID** 并添加到追踪中。一个追踪表示请求的整个旅程,而一个 Span 则是沿途的每一个独立跳跃,每一个请求。Span 可以包含**标签**(即元数据),这些标签可用于后续情境化请求。Span 通常包含起始时间戳和结束时间戳等常见标签,不过也很容易将具有语义相关性的标签(如业务实体 ID)与 Span 相关联。
Spring Cloud Sleuth (org.springframework.cloud:spring-cloud-starter-sleuth),一旦添加到 CLASSPATH 中,就会自动对常见的通信通道进行埋点
Spring Cloud Sleuth 为你设置了有用的日志格式,用于打印追踪 ID 和 Span ID。假设你在 spring.application.name 为 `my-service-id` 的微服务中运行启用了 Spring Cloud Sleuth 的代码,你将在微服务的日志中看到如下内容
2016-02-11 17:12:45.404 INFO [my-service-id,73b62c0f90d11e06,73b62c0f90d11e06,false] 85184 --- [nio-8080-exec-1] com.example.MySimpleComponentMakingARequest : ...
在该示例中,`my-service-id` 是 `spring.application.name`,`73b62c0f90d11e06` 是追踪 ID,`73b62c0f90d11e06` 是 Span ID。此信息非常有用。你可以将日志发布到日志分析和操作工具,如 Elasticsearch 和 Splunk。有多种方法可以将数据发送到那里。例如,Logstash 是一个日志发布器,可以写入 ElasticSearch。Cloud Foundry 通过一个名为 Loggregator 的工具自动将服务所有实例的日志聚合到一个统一日志中,然后可以将其转发到任何 Syslog 兼容的服务,包括 Splunk 或 PaperTrail 等工具。无论采用哪种方法,如果你将所有日志和追踪信息集中在一个地方进行查询和分析,就可以进行有趣的查询。
Spring Cloud Sleuth 还通过简单地注入 `SpanAccessor` 使此信息可供任何 Spring Cloud Sleuth 感知的 Spring 应用程序使用。你也可以使用此功能来对未由 Spring Cloud 埋点的自有组件进行埋点,以便它们可以传递追踪信息。当然,每个追踪器都会有所不同,但 Spring Cloud Sleuth 的代码本身(例如:TraceFeignClientAutoConfiguration)暗示了典型追踪器的工作原理。
...
@Autowired
private SpanAccessor spanAccessor;
...
Span span = this.spanAccessor.getCurrentSpan();
...
template.header(Span.TRACE_ID_NAME, Span.toHex(span.getTraceId()));
setHeader(template, Span.SPAN_NAME_NAME, span.getName() );
setHeader(template, Span.SPAN_ID_NAME, Span.toHex(span.getSpanId()));
...
应该追踪哪些请求?理想情况下,你会希望有足够的数据来反映实际运营流量的趋势。但是,你也不想让你的日志和分析基础设施不堪重负。有些组织可能每千个请求只保留一个,或者每十个,甚至每百万个!默认情况下,阈值为 10% 或 0.1,但你可以通过指定采样百分比来覆盖它
spring.sleuth.sampler.percentage = 0.2
或者,你可以注册自己的 `Sampler` bean 定义,通过编程方式决定哪些请求应该被采样。你可以更智能地选择要追踪的内容,例如,忽略成功的请求,或许检查某个组件是否处于错误状态,或任何其他情况。作为参数给定的 `Span` 表示较大追踪中当前正在进行的请求的 Span。如果你愿意,可以进行有趣的、特定于请求类型的采样。例如,你可以决定只采样 HTTP 状态码为 500 的请求。例如,以下 `Sampler` 将追踪大约一半的请求
@Bean
Sampler customSampler() {
return new Sampler() {
@Override
public boolean isSampled(Span span) {
return Math.random() > .5 ;
}
};
}
确保为你的应用程序和基础设施设定现实的期望。你的应用程序的使用模式很可能需要更高或更低的敏感度来检测趋势和模式。这是运营数据;大多数组织不会将这些数据存储超过几天,最多不超过一周。
数据收集只是一个开始,但目标是理解数据,而不仅仅是收集。为了领会全局,我们需要超越单个事件。
为此,我们将使用 OpenZipkin 项目。OpenZipkin 是 Zipkin 的完全开源版本,该项目于 2010 年起源于 Twitter,并基于 Google Dapper 论文。
此前,Zipkin 的开源版本与 Twitter 内部使用的版本发展速度不同。OpenZipkin 代表了这些工作的同步:OpenZipkin *就是* Zipkin,本文中我们提及 Zipkin 时,指的是 OpenZipkin 中反映的版本。
Zipkin 提供了一个 REST API,客户端可以直接与其通信。Zipkin 甚至支持基于 Spring Boot 实现此 REST API。使用它就像直接使用 Zipkin 的 `@EnableZipkinServer` 一样简单。Zipkin 服务器通过 `SpanStore` 将写入操作委托给持久化层。目前,原生支持使用 MySQL 或内存中的 `SpanStore`。作为 REST 的替代方案,我们也可以通过 Spring Cloud Stream 绑定器(如 RabbitMQ 或 Apache Kafka)向 Zipkin 服务器发布消息。我们将使用此选项,以及 `org.springframework.cloud`:`spring-cloud-sleuth-zipkin-stream` 的 `@EnableZipkinStreamServer`,将传入的基于 Spring Cloud Stream 的 Sleuth `Span` 转换为 Zipkin 的 `Span`,然后使用 `SpanStore` 进行持久化。你可以使用任何喜欢的 Spring Cloud Stream 绑定,但在本例中,我们将使用 Spring Cloud Stream RabbitMQ (`org.springframework.cloud`:`spring-cloud-starter-stream-rabbitmq`)。
package com.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
@EnableZipkinStreamServer
@SpringBootApplication
public class ZipkinQueryServiceApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinQueryServiceApplication.class, args);
}
}
在 `application.properties` 中指定端口,将 Zipkin 服务器绑定到一个周知端口,以便后续 UI 可以与其通信
server.port=9411
我的示例代码使用了在 `eureka-servie` 中的 Spring Cloud Netflix 支持的 Eureka 服务注册中心用于服务注册和发现,所以接下来先启动它。
我们的微服务(message-client 和 message-service)是典型的 Spring Cloud 微服务。我只添加了 org.springframework.cloud:spring-cloud-sleuth-stream 和相应的 Spring Cloud Stream 绑定器,使其 Sleuth 追踪信息以带外方式发布到 Zipkin 进行分析。
Zipkin Web UI 使得分析和查询 Zipkin 数据变得容易。你可以运行 Zipkin Web 在我示例中的构建脚本 或者直接从 Zipkin 项目的构建中获取最新版本 然后运行它
java -jar lib/zipkin-web-all.jar -zipkin.web.port=:9412 -zipkin.web.rootUrl=/ -zipkin.web.query.dest=localhost:9411
当 `message-service` 接收到请求时,它通过 Spring Cloud Stream 绑定器将回复消息发送*回* `message-client`,客户端然后接受并使用 Spring Integration 消息端点记录该消息。这是一个刻意设计的调用序列,用于演示 Spring Cloud Sleuth 的部分能力。
启动 UI,然后查找所有最近的追踪。你可以按最新、最长等方式排序,以便更精细地控制你看到的结果。
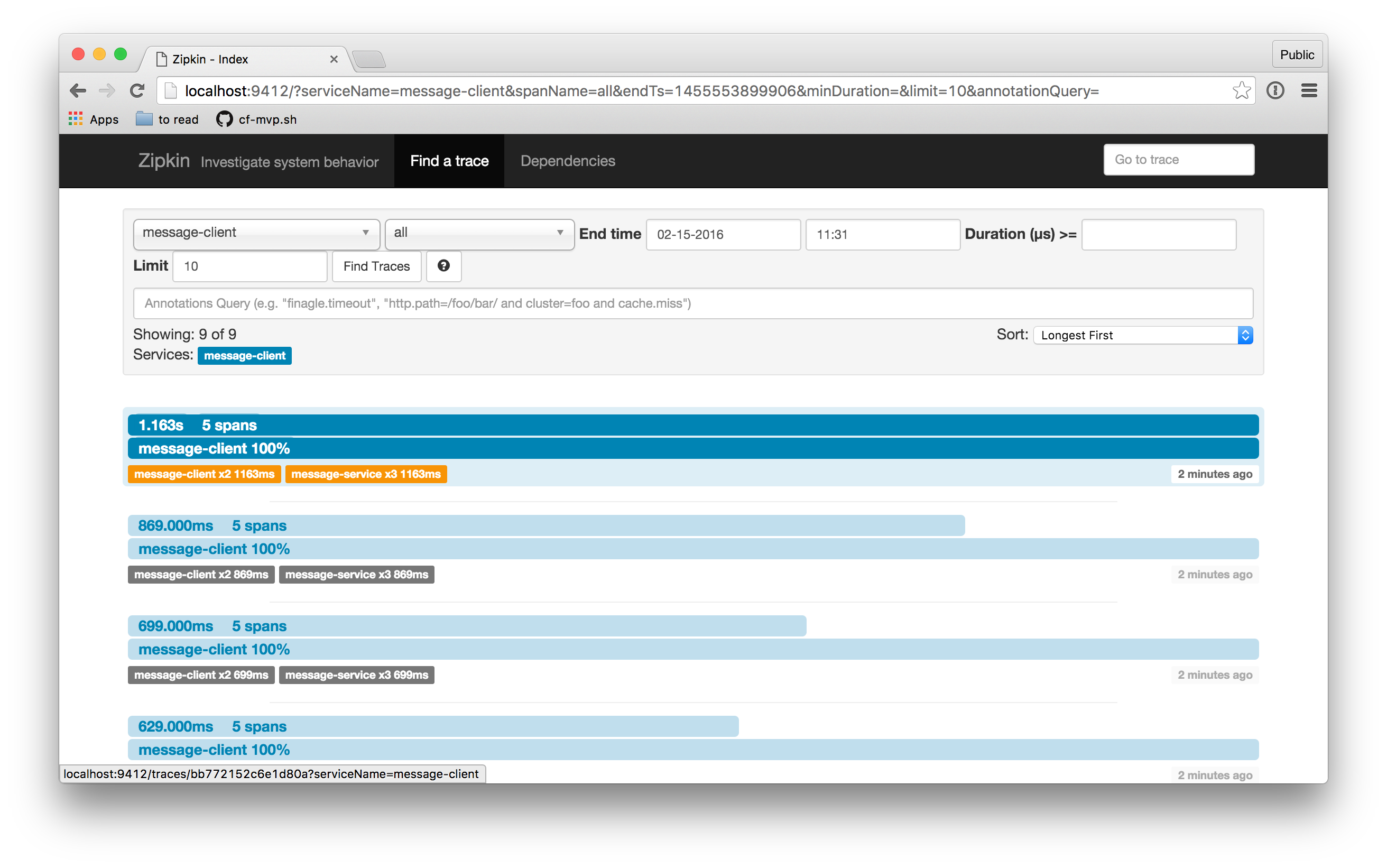
当我点击返回的一个追踪时,我得到一个如下所示的 UI
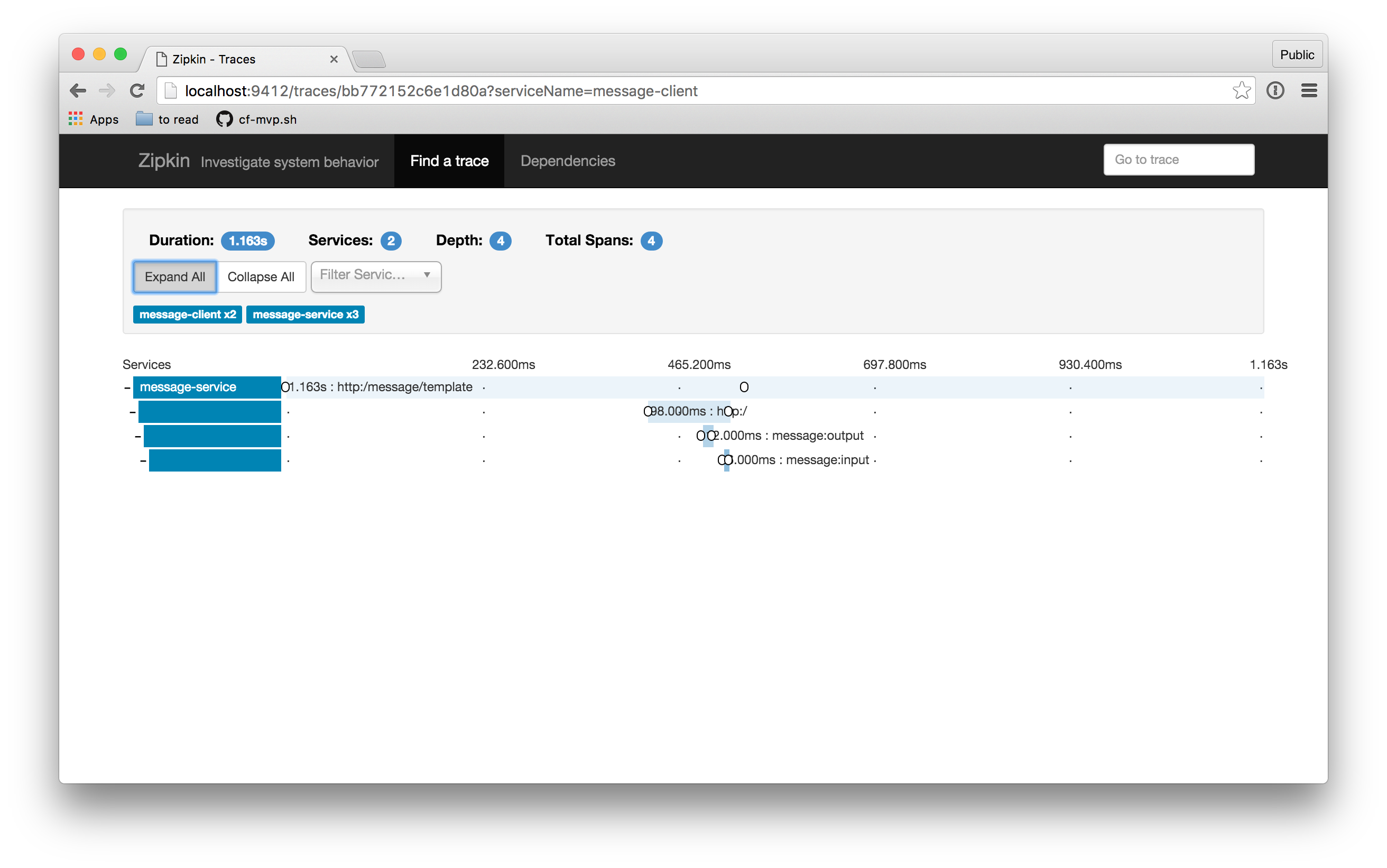
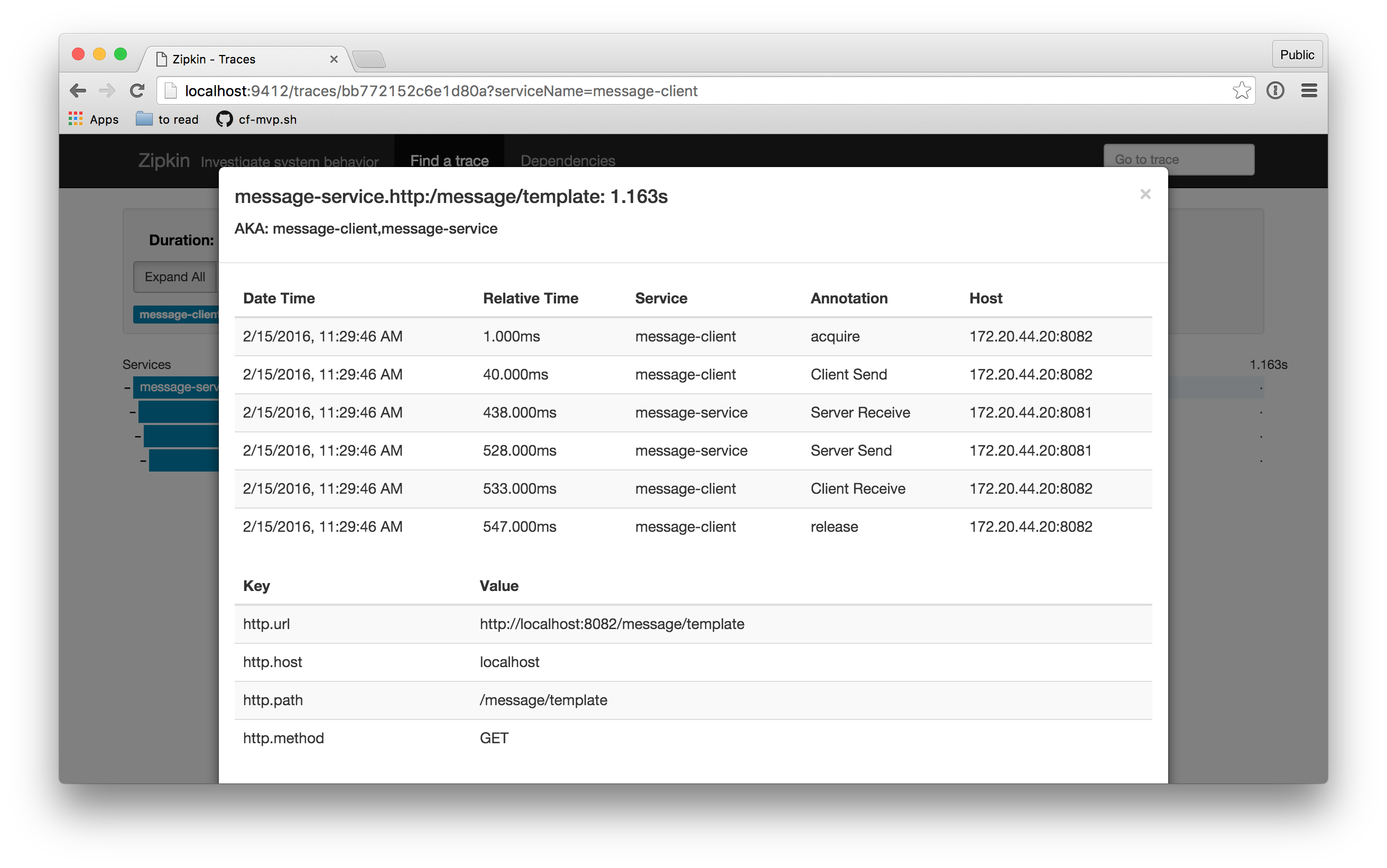
每个独立的 Span 也带有关于与其关联的特定请求的信息(**标签**)。你可以通过点击单个 Span 来查看这些详细信息
对于基于 Spring 的工作负载,分布式追踪再简单不过了!然而,追踪本身就是一个跨领域的问题,无论服务采用何种技术栈实现。OpenTracing 倡议旨在为多种语言和平台上的现代追踪标准化词汇和概念。OpenTracing 倡议得到了许多非常大型组织的支持,其牵头人之一是最初 Google Dapper 论文的作者之一。该倡议定义了语言绑定;目前已有 JavaScript、Python、Go 等语言的实现。我们将使 Spring Cloud Sleuth 在概念上与这项工作保持兼容,并会持续跟踪。虽然不强制要求,但预计这些绑定常常会以 Zipkin 作为其后端。
本博客旨在概述分布式追踪中的概念和支持技术。我们介绍了 Spring Cloud Sleuth 以及它如何与 Zipkin 配合工作。Zipkin 本身有一个有趣的支持生态系统。如果你真的想了解 Spring Cloud Sleuth、Zipkin、Apache 的 HTrace 等分布式追踪工具是基于什么模型构建的,请查阅原始的 Google Dapper 论文。你应该查看Adrian Cole 介绍更广泛 Zipkin 生态系统的视频。当然,本博客的代码也已在线。最后,直接访问 Spring Initializr,在你的 Maven 构建中添加 Spring Cloud Sleuth Stream 和 Zipkin Stream Server 即可开始使用。