
领先一步
VMware 提供培训和认证,助您加速进步。
了解更多您无疑已经阅读了Jennifer Hickey关于介绍 Cloud Foundry workers、它们在设置Ruby Resque 后台作业中的应用,以及今天关于介绍 Spring 支持的博文。
vmc 版本,执行 gem update vmc。public static void main 作业。也就是说,Cloud Foundry worker 本质上是一个进程,比 Web 应用程序低级,这自然适用于许多所谓的后台作业。java 命令,但更简单的方法是打包一个 shell 脚本,然后让 Cloud Foundry 为您运行该 shell 脚本。您提供的命令应使用 $JAVA_OPTS,Cloud Foundry 已提供该选项以确保一致的内存使用和 JVM 设置。org.codehaus.mojo:appassembler-maven-plugin 插件将帮助您创建启动脚本并打包您的 .jars 以便轻松部署,同时还可以指定入口点类。.jar 项目上执行 vmc push 时,Cloud Foundry 会询问您该应用程序是否为独立应用程序。确认后,它会引导您完成后续设置。因此,让我们来看一些使用 Cloud Foundry workers 更容易、更自然的常见体系结构和安排。我们将从 Spring 框架和两个周边项目 Spring Integration 和 Spring Batch 的角度来看这些模式,这两个项目都在 Web 应用程序内部和外部蓬勃发展。正如我们将看到的,这两个框架都支持解耦和改进的可组合性。我们将分离什么发生与何时发生,并将分离什么发生与何处发生,所有这些都是为了释放前端的容量。
我常被问到的一个常见问题是:“如何在 Cloud Foundry 上进行作业调度?” Cloud Foundry 支持 Spring 应用程序,而 Spring 当然一直以来都支持企业级的调度抽象,例如 Quartz 和 Spring 3.0 的 @Scheduled 注解。@Scheduled 非常好用,因为它极其容易添加到现有应用程序中。最简单的情况下,您只需将 @EnableScheduling 添加到您的 Java 配置中,或者将 <task:annotation-driven/> 添加到您的 XML 配置中,然后在代码中使用 @Scheduled 注解。这对于企业应用程序来说是非常自然的做法——也许您有一个需要运行的分析或报告流程?某个耗时长的批处理流程?我准备了一个示例,演示如何使用 @Scheduled 来运行一个 Spring Batch Job。Spring Batch 作业本身是一个工作线程,它与一个 Web 服务协同工作,该 Web 服务糟糕的 SLA 使其不适合实时使用。在 Spring Batch 中处理工作更安全、更干净,因为它的恢复和重试功能可以弥补任何网络中断、网络延迟等问题。有关大部分细节,我将 引用代码示例,我们只看入口点,然后看如何在 Cloud Foundry 上部署应用程序。
// set to every 10s for testing.
@Scheduled(fixedRate = 10 * 1000)
public void runNightlyStockPriceRecorder() throws Throwable {
JobParameters params = new JobParametersBuilder()
.addDate("date", new Date())
.toJobParameters();
JobExecution jobExecution = jobLauncher.run(job, params);
BatchStatus batchStatus = jobExecution.getStatus();
while (batchStatus.isRunning()) {
logger.info("Still running...");
Thread.sleep(1000);
}
logger.info(String.format("Exit status: %s", jobExecution.getExitStatus().getExitCode()));
JobInstance jobInstance = jobExecution.getJobInstance();
logger.info(String.format("job instance Id: %d", jobInstance.getId()));
}
此方法将在 @Scheduled 注解规定的频率下调用:在本例中,每 10 秒调用一次。使用 JobLauncher 启动 Job 后,应用程序将阻塞(这可以避免,但在本例中是可以接受的,因为我们预期它会发生)。根据数据和批处理的类型,它可能会阻塞几分钟……或者一周!Spring Batch 是一个健壮的批处理引擎,它能够安全地处理大型数据集。批处理流程通常不应与 HTTP 请求在同一管道中——它是确定性的、耗时长的,因此在 Cloud Foundry 中使用长时间运行的工作进程在这里是一个真正的优势。
让我们将应用程序部署到 Cloud Foundry。示例应用程序是 Maven 项目。要构建它们,请导航到代码库的根目录,并使用 Maven 构建工具运行 mvn clean install。
从这里开始部署应用程序很容易,前提是您已经设置了 vmc 命令行工具,并将其更新到了最新版本,正如 Jennifer 在第一篇博文中解释的那样。应用程序在其代码的根目录下包含一个 manifest.yml 文件。Cloud Foundry 的 manifest.yml 文件完整地描述了应用程序期望由平台即服务(PaaS)提供的所有内容,包括使用的数据库、分配的 RAM 大小等。Cloud Foundry 会读取此清单并在部署应用程序时满足其要求。因此,通过简单地部署此应用程序,您还将获得该应用程序需要存储示例数据的 PostgreSQL 数据库实例,以及 Spring Batch 为其运行时状态维护的表。
jlongmbp17:cf-workers-batch jlong$ vmc --path target/appassembler/ push
Pushing application 'batch'...
Creating Application: OK
Creating Service [stock_batch]: OK
Binding Service [stock_batch]: OK
Uploading Application:
Checking for available resources: OK
Processing resources: OK
Packing application: OK
Uploading (55K): OK
Push Status: OK
Staging Application 'batch': OK
Starting Application 'batch': OK
jlongmbp17:cf-workers-batch jlong$ vmc apps
+---------------------+----+---------+----------------------------------+----------------+
| Application | # | Health | URLS | Services |
+---------------------+----+---------+----------------------------------+----------------+
| batch | 1 | RUNNING | | stock_batch |
...
计划好的方法每十秒运行一次,所以在执行下一步之前请等待十秒。接下来,我们将登录数据库,看看我们的这个小进程做了什么。Spring Batch 作业获取 STOCKS 表中的所有股票代码,然后查找其当前价格信息,并将该快照数据插入到 STOCKS_DATA 表中。vmc tunnel 命令会创建一个直接连接到云端管理的数据库的隧道。我用它连接到我们的 PostgreSQL 实例,并在 STOCKS_DATA 表上运行一个查询(SELECT * FROM STOCKS_DATA)。
jlongmbp17:cf-workers-batch jlong$ vmc tunnel stock_batch
Binding Service [stock_batch]: OK
Stopping Application 'caldecott': OK
Staging Application 'caldecott': OK
Starting Application 'caldecott': OK
Getting tunnel connection info: OK
Service connection info:
username : u59993cf15bc0461a1d2648f7eab27f2da15f
password : p1be9035f3c764817809ac81f3267
name : d5c5a80838d7bcd79dc7eefa6c1b04d22
Starting tunnel to stock_batch on port 10002.
1: none
2: psql
Which client would you like to start?: 2
Launching 'psql -h localhost -p 10002 -d d5c5aefa6c1b04d2280838d7bcd79dc7e -U u59993cf15bc04817809ac861a1d2648f -w'
psql (9.0.5, server 9.0.4)
Type "help" for help.
d5c5aefa6c1b04d2280838d7bcd79dc7e=> select * from stocks_data;
id | date_analysed | high_price | low_price | closing_price | symbol
----+---------------+------------+-----------+---------------+--------
1 | 2012-05-08 | 613 | 602.3 | 602.3 | GOOG
2 | 2012-05-08 | 30.78 | 30.25 | 30.25 | MSFT
3 | 2012-05-08 | 27.87 | 27.56 | 27.56 | ORCL
4 | 2012-05-08 | 32.41 | 32.06 | 32.06 | ADBE
5 | 2012-05-08 | 107.38 | 103 | 103 | VMW
...
成功了!在继续之前,现在是很好的时机来停止应用程序。每十秒查找一次股票信息并插入新记录对您来说没有任何好处!几个小时后,该数据集可能会变得非常庞大。我建议您更改频率(参见注释中为 @Scheduled 注解提供的 cron 表达式,该表达式可在每周工作日下午 11 点运行),然后执行 vmc --path target/appassembler/ update,或者干脆将其停止。
jlongmbp17:cf-workers-batch jlong$ vmc stop batch
因此,批处理和作业调度是 Spring、Spring Batch 和 Cloud Foundry 都能出色处理的两个非常常见的用例。另一个(不同但同样常见)的用例是为易于扩展性而架构。毕竟,当您的下一个热门应用程序被“Oprah 效应”或/.'d 时,扩展到底意味着什么?我们现在来看看……
这有点违反直觉,但一个拥有大量小型、单一功能的组件的系统比一个单体应用程序更容易扩展,因为可以独立于应用程序的其他部分来扩展和调整单个工作负载。假设您有一个资源匮乏的前端 Web 应用程序,不应该承担缓慢的、可能是 I/O 繁重的任务。一种将主线程与缓慢的后台流程解耦的简单方法是引入一个消息队列,例如 RabbitMQ。在消息传递中,我们谈论积极的消费者模式,在这种模式下,工作被排队,而工作进程尽可能快地从中出队并完成。如果工作进程跟不上新工作的使用速度,那么添加新的工作进程来弥补就很容易了:只需运行 vmc instances my-backend +10!每个单独的请求可能仍然需要固定的一段时间,但系统的整体吞吐量会增加。
对于我们的下一个示例——它与上一个示例关系不大,除了它是另一种在 Cloud Foundry 上使用独立工作进程的方式——我们将构建一个面向消息的服务。我们将使用 RabbitMQ,一个世界一流的消息队列,它作为一项服务在 Cloud Foundry 上可用。消息传递系统就像广为人知的邮箱。它们接受消息并分发消息。通过将您的API简化为像 RabbitMQ 这样的消息传递代理(它本身基于 AMQP 协议),您可以为您的应用程序提供尽可能友好的接口。消息传递系统本质上是异步的,因此它们不会强制执行请求/回复交换的概念,尽管这也有支持。如果您想利用 RabbitMQ 与其他工作进程集成,您仍然可以向服务的使用者公开一个外观或网关,这样,如果您不愿意,他们就不必了解服务的实现方式。我们将使用 Spring Integration,它支持企业集成模式,来从 Java 接口类型构建一个消息网关。
```java
public interface StockSymbolLookupClient { StockSymbolLookup lookupSymbol (String symbol) throws Throwable; }
<P>With Spring Integration's help, calls to this method will result in a message being sent to RabbitMQ where, on the other side, our service will dequeue the message, process it, and then, eventually send a reply back to RabbitMQ, which the caller of this method will receive as the reply value. </P> <P> To configure the client, I used a little bit of Spring Integration to setup the gateway, which then forwards the request to the outbound AMQP gateway adapter.</P>
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans:beans ...>
...
<gateway
service-interface="org.cloudfoundry.workers.stocks.integration.client.StockClientGateway"
default-request-channel="outboundSymbolsRequests"
default-reply-channel="outboundSymbolsReplies"
/>
<amqp:outbound-gateway
request-channel="outboundSymbolsRequests"
reply-channel="outboundSymbolsReplies"
routing-key="tickers"
amqp-template="amqpTemplate"
/>
</beans:beans>
我省略了 RabbitMQ 特定连接机制的细节(当然,所有这些都使用 cloudfoundry-runtime API 来完成)——请参阅客户端示例。这段代码片段展示了重要部分:Spring 将根据 StockClientGateway interface 在运行时合成一个实现,我们可以在客户端代码中注入并使用它来调用服务。
在服务方,我们需要一些代码来从 RabbitMQ 中出队消息,然后将它们转发给工作节点,最后将结果通过 RabbitMQ 作为回复传递回来。服务方自然可以独立于客户端进行扩展。您可能有一个 Web 应用程序对应一个客户端,但运行十个服务实现,以承担剩余的工作并吸收额外需求。这是我们的服务实现的样子,同样省略了 RabbitMQ 特定的连接 Bean(请参考示例)。
<?xml version="1.0" encoding="UTF-8"?>
<beans:beans ...>
...
<amqp:inbound-gateway request-channel="inboundSymbolsRequests"
queue-names="tickers"
message-converter="mc"
connection-factory="connectionFactory"/>
<service-activator ref="client" input-channel="inboundSymbolsRequests" requires-reply="true"/>
</beans:beans>
这种方法非常强大。在我的示例中,我只是推迟了一个微不足道的 RESTful Web 服务调用成本。但您可以想象以这种方式执行更耗时的事情——图像处理、批处理作业、大型分析等。
此示例的部署稍微复杂一些,因为它有两个部分。网关实现是一个简单的 Bean,Spring Integration 将其作为一个类似客户端代理的消息传递系统提供。我们可以从另一个后台作业、Web 应用程序或其他任何东西中使用该网关。在我们的例子中,我们的客户端——一个 Spring MVC 应用程序——使用该网关来调用服务。服务负责提供有趣的功能,接收来自已配置的 RabbitMQ 实例的请求,调用股票代码查找 Bean,然后将结果通过 RabbitMQ 返回给请求者。我们需要先部署服务。和以前一样,如果您还没有这样做,您需要通过在根目录下运行 mvn clean install 来构建整个代码库。然后,在 cf-workers-integration-service 文件夹的根目录下,运行以下命令:
jlongmbp17:cf-workers-integration-service jlong$ vmc --path target/appassembler/ push
Pushing application 'integration-service'...
Creating Application: OK
Creating Service [stock_rabbitmq]: OK
Binding Service [stock_rabbitmq]: OK
Uploading Application:
Checking for available resources: OK
Processing resources: OK
Packing application: OK
Uploading (44K): OK
Push Status: OK
Staging Application 'integration-service': OK
Starting Application 'integration-service': OK
服务部署完毕后,让我们通过从 Web 客户端调用一次来测试它。返回到 cf-workers-integration-webclient 目录。然后,运行与服务相同的命令。
jlongmbp17:cf-workers-integration-webclient jlong$ vmc --path target/cf-workers-integration-webclient-1.0-SNAPSHOT push
Pushing application 'integration-webclient'...
Creating Application: OK
Binding Service [stock_rabbitmq]: OK
Uploading Application:
Checking for available resources: OK
Processing resources: OK
Packing application: OK
Uploading (3K): OK
Push Status: OK
Staging Application 'integration-webclient': OK
Starting Application 'integration-webclient': OK
应用程序部署完成后(您可以通过运行 vmc apps 来确认两者都在正常运行)。现在,让我们打开客户端来试用我们的服务:打开 Web 客户端应用程序的 URL。在我的例子中,URL 是 integration-webclient.cloudfoundry.com。它应该显示一个看起来很普通的表单。输入一个股票代码(我用 VMW 测试……)然后按回车键。您应该会在页面上看到数据出现。
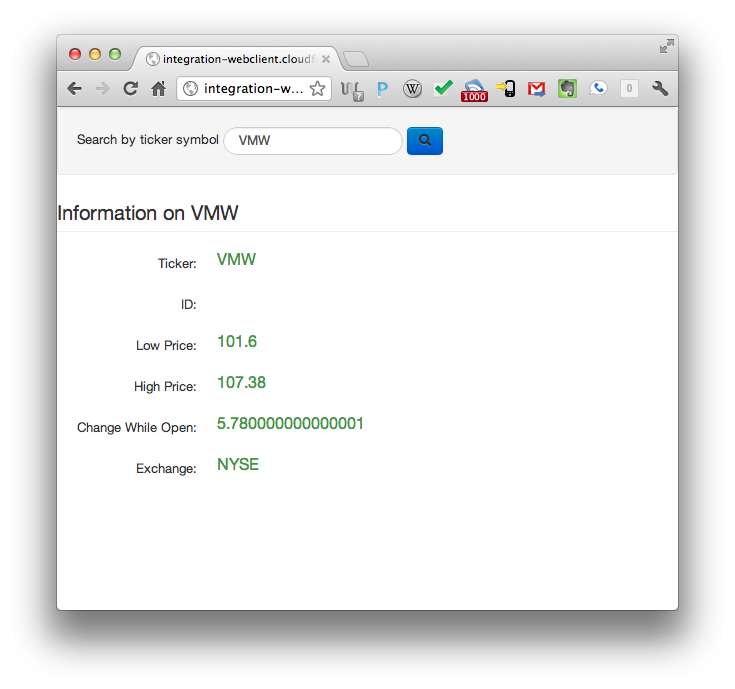
integration-service 的日志,您应该会看到控制台输出反映出与您在客户端看到的信息相同的内容。如果看到,恭喜您!
此时,您已经掌握了强大的能力。Cloud Foundry 工作进程非常适合处理那些不适合放入 HTTP 请求处理管道中的工作。根据我的经验,这涵盖了许多方面:批处理、集成和消息传递代码、分析、报告、大数据和补偿性事务,以及确实通过除 HTTP 之外的其他协议公开的系统。